I’ve recently returned from the IEEE International Symposium on Field-Programmable Custom Computing Machines (known as FCCM). I used to attend FCCM regularly in the early 2000s, and while I have continued to publish there, I have not attended myself for some years. I tried a couple of years ago, but ended up isolated with COVID in Los Angeles. In contrast, I am pleased to report that the conference is in good health!
The conference kicked off on the the evening of the 4th May, with a panel discussion on the topic of “The Future of FCCMs Beyond Moore’s Law”, of which I was invited be be part, alongside industrial colleagues Chris Lavin and Madhura Purnaprajna from AMD, Martin Langhammer from Altera, and Mark Shand from Waymo. Many companies have tried and failed to produce lasting post-Moore alternatives to the FPGA and the microprocessor over the decades I’ve been in the field and some of these ideas and architectures (less commonly, associated compiler flows / design tools) have been very good. But, as Keynes said, “markets can remain irrational longer than you can remain solvent”. So instead of focusing on commercial realities, I tried to steer the panel discussion towards the genuinely fantastic opportunities our academic field has for a future in which power, performance and area innovation changes become a matter of intellectual advances in architecture and compiler technology rather than riding the wave of technology miniaturisation (itself, of course, the product of great advances by others).


We look older, and we don’t have beer.
The following day, the conference proper kicked off. Some highlights for me from other authors included the following papers aligned with my general interests:
- AutoNTT: Automatic Architecture Design and Exploration for Number Theoretic Transform Acceleration on FPGAs from Simon Fraser University, presented by Zhenman Fang.
- RealProbe: An Automated and Lightweight Performance Profiler for In-FPGA Execution of High-Level Synthesis Designs from Georgia Tech, presented by Jiho Kim from Callie Hao‘s group.
- High Throughput Matrix Transposition on HBM-Enabled FPGAs from the University of Southern California (Viktor Prasanna‘s group).
- ITERA-LLM: Boosting Sub-8-Bit Large Language Model Inference Through Iterative Tensor Decomposition from my colleague Christos Bouganis‘ group at Imperial College, presented by Keran Zheng.
- Guaranteed Yet Hard to Find: Uncovering FPGA Routing Convergence Paradox from Mirjana Stojilovic‘s group at EPFL – and winner of this year’s best paper prize!
In addition, my own group had two full papers at FCCM this year:
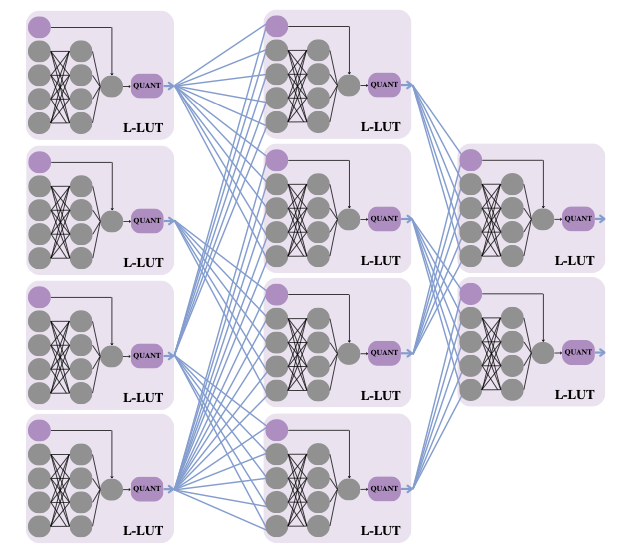
- Banked Memories for Soft SIMT Processors, joint work between Martin Langhammer (Altera) and me, where Martin has been able to augment his ultra-high-frequency soft-processor with various useful memory structures. This is probably the last paper of Martin’s PhD – he’s done great work in both developing a super-efficient soft-processor and in forcing the FPGA community to recognise that some published clock frequency results are really quite poor and that people should spend a lot longer thinking about the physical aspects of their designs if they want to get high performance.
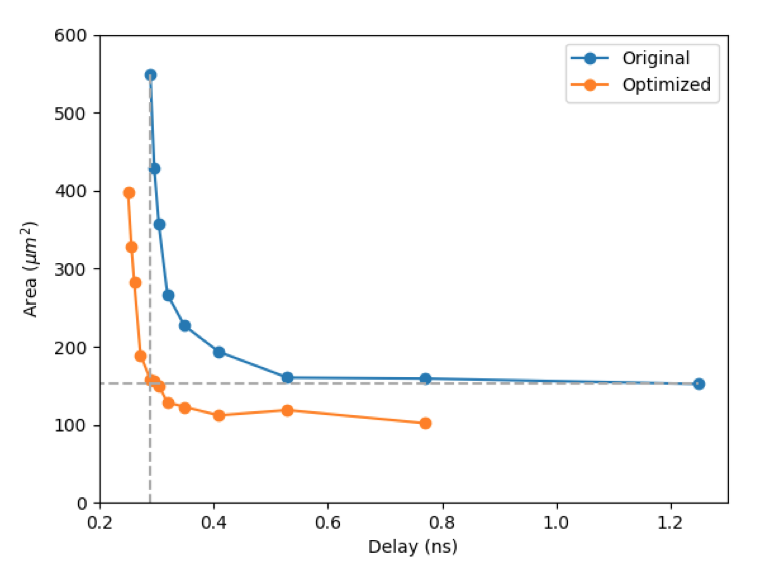
- NeuraLUT-Assemble: Hardware-aware Assembling of Sub-Neural Networks for Efficient LUT Inference, joint work between my PhD student Marta Andronic and me. I think this is a landmark paper in terms of the results that Marta has been able to achieve. Compared to her earlier NeuraLUT work which I’ve blogged on previously, she has added a way to break down large LUTs into trees of smaller LUTs, and a hardware-aware way to learn sparsity patterns that work best, localising nonlinear interactions in these neural networks to within lookup tables. The impact of these changes on the area and delay of her designs is truly impressive.
memory structures for soft processors

Overall, it was well worth attending. Next year, Callie will be hosting FCCM in Atlanta.

 -input Boolean function, then learn all
-input Boolean function, then learn all  lines in that function’s truth table. Since then, Marta and I have been exploring ways of parameterising that space to decouple the complexity of the function-classes implemented from the number of inputs. This gave rise to PolyLUT (parameterised as polynomials) and NeuraLUT (parameterised as small neural networks). Once we have learnt a function
lines in that function’s truth table. Since then, Marta and I have been exploring ways of parameterising that space to decouple the complexity of the function-classes implemented from the number of inputs. This gave rise to PolyLUT (parameterised as polynomials) and NeuraLUT (parameterised as small neural networks). Once we have learnt a function  , all these methods enumerate the inputs of the function for the discrete space of quantised activations to produce the L-LUT. Olly’s work introduces `don’t cares’ into the picture: if a particular combination of inputs to the function is never, or rarely, seen in the training data, then the optimisation is allowed to treat the function as a don’t care at that point.
, all these methods enumerate the inputs of the function for the discrete space of quantised activations to produce the L-LUT. Olly’s work introduces `don’t cares’ into the picture: if a particular combination of inputs to the function is never, or rarely, seen in the training data, then the optimisation is allowed to treat the function as a don’t care at that point. 


 , then I may as well be computing
, then I may as well be computing  . In both cases, the fundamental issue becomes how to identify whether a value will be unused later in a computation. Intriguingly, this question is tightly related to the way a computation is performed: there are many ways of computing a given mathematical computation, and each one will have its own redundancies to exploit.
. In both cases, the fundamental issue becomes how to identify whether a value will be unused later in a computation. Intriguingly, this question is tightly related to the way a computation is performed: there are many ways of computing a given mathematical computation, and each one will have its own redundancies to exploit. and equivalences expressing clock and data gating within the same rewriting framework. A collection of these latter equivalences are shown in the table below from our paper.
and equivalences expressing clock and data gating within the same rewriting framework. A collection of these latter equivalences are shown in the table below from our paper. 
 for its inputs
for its inputs  and some learned weight vector
and some learned weight vector 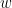 and bias
and bias  , where
, where  is typically a fixed nonlinear function such as a
is typically a fixed nonlinear function such as a  . The Xilinx team noted that if they restrict the length of the vector
. The Xilinx team noted that if they restrict the length of the vector  . In this way, we can tune a knob: turn down to
. In this way, we can tune a knob: turn down to  for minimal expressivity but the smallest number of parameters to train, and recover LogicNets as a special case; turn up
for minimal expressivity but the smallest number of parameters to train, and recover LogicNets as a special case; turn up 
 and
and  are the extracted “close” expressions.
are the extracted “close” expressions.
 can just be replaced by
can just be replaced by  , e.g.
, e.g.  . But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g.
. But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g.  , where I am using math script to denote the value of a variable and teletype script to denote an expression.
, where I am using math script to denote the value of a variable and teletype script to denote an expression. . Now let’s imagine introducing a new operator
. Now let’s imagine introducing a new operator  that takes two expressions, the second of which is interpreted as a Boolean. Let’s give
that takes two expressions, the second of which is interpreted as a Boolean. Let’s give  . In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as
. In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as  . These
. These ![x \in [-1,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , then a classical evaluation of
, then a classical evaluation of  would give me
would give me ![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=ffffff&fg=000000&s=0&c=20201002) , due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite
, due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite  would likely fire, resulting in zero residing in the same e-class as
would likely fire, resulting in zero residing in the same e-class as  . Since the interval associated with
. Since the interval associated with  is
is ![[0,0]](https://s0.wp.com/latex.php?latex=%5B0%2C0%5D&bg=ffffff&fg=000000&s=0&c=20201002) , the same interval will automatically be associated with
, the same interval will automatically be associated with 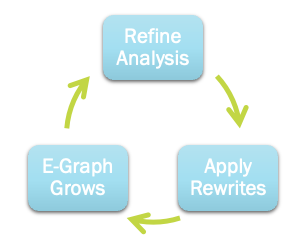

 of ‘hard’ samples I used to characterise the network varies in practice from the actual proportion
of ‘hard’ samples I used to characterise the network varies in practice from the actual proportion  , then I may end up with a somewhat different behaviour, as indicated by the purple region.
, then I may end up with a somewhat different behaviour, as indicated by the purple region.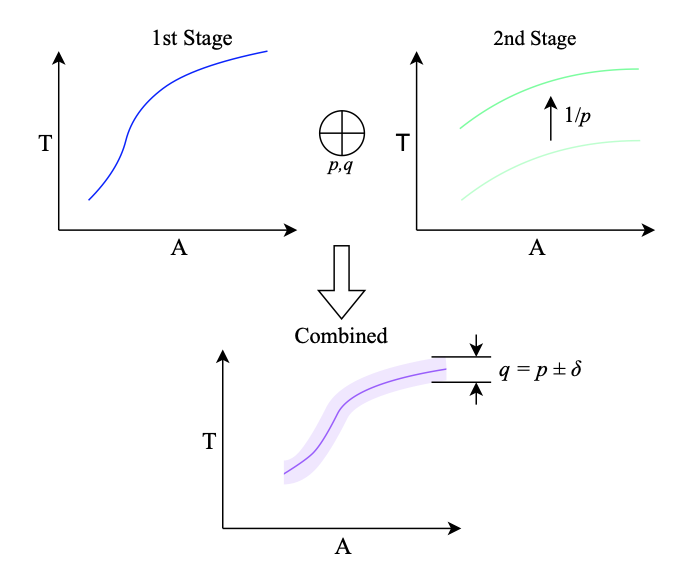
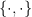 to denote a function taking two bit vectors and concatenating them together. Of course the ‘multiplication by 10 is easy’ becomes ‘multiplication by 2 is easy’ in binary. Putting this together, we can write
to denote a function taking two bit vectors and concatenating them together. Of course the ‘multiplication by 10 is easy’ becomes ‘multiplication by 2 is easy’ in binary. Putting this together, we can write 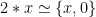 , meaning that multiplication by two is the same as concatenation with a zero. But what does ‘the same as’ actually mean here? Clearly they are not the same expression syntactically and one is cheap to compute whereas one is expensive. What we mean is that no matter which value of
, meaning that multiplication by two is the same as concatenation with a zero. But what does ‘the same as’ actually mean here? Clearly they are not the same expression syntactically and one is cheap to compute whereas one is expensive. What we mean is that no matter which value of  rather than
rather than  .
. 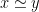 then it necessarily follows that
then it necessarily follows that  for every function symbol
for every function symbol 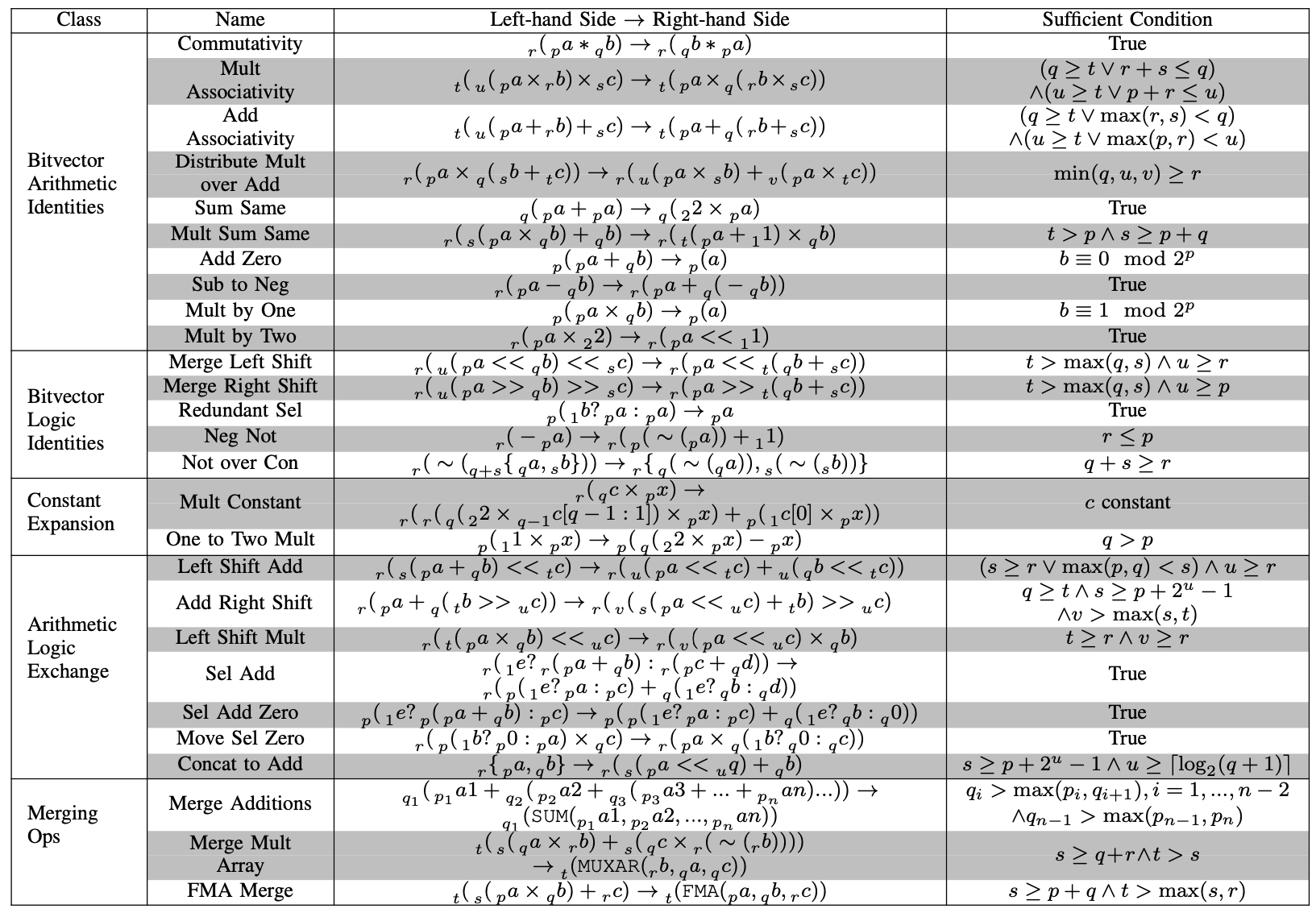
 then I wouldn’t bother to calculate
then I wouldn’t bother to calculate 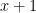 twice. We describe in our paper how we address this problem via an optimisation formulation. Our tool solves this optimisation and produces synthesisable Verilog code for the resulting circuit.
twice. We describe in our paper how we address this problem via an optimisation formulation. Our tool solves this optimisation and produces synthesisable Verilog code for the resulting circuit.