We’re often faced with numerical computation expressed as arithmetic over the reals but implemented as finite precision arithmetic, for example over the floats. A natural question arises: how accurate is my calculated answer?
For many years, I’ve studied the closely related problem “how do I design a machine to implement a numerical computation most efficiently to a given level of accuracy?” for various definitions of “numerical computation”, “efficiently” and “accuracy”.
The latest incarnation of this work is particularly exciting, in my opinion. ACM Transactions on Mathematical Software has recently accepted a manuscript reporting joint work of my former post-doc, Victor Magron, Alastair Donaldson and myself.
The basic setting is borrowed from earlier work I did with my former PhD student David Boland. Imagine that you’re computing 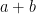 in floating-point arithmetic. Under some technical assumptions, the answer you get will not actually be , but rather
in floating-point arithmetic. Under some technical assumptions, the answer you get will not actually be , but rather  where
where  is bounded by a constant determined only by the precision of the arithmetic involved. The same goes for any other fundamental operator *, /, etc. Now imagine chaining a whole load of these operations together to get a computation. For straight-line code consisting only of addition and multiplication operators, the result will be polynomial in all your input variables as well as in these error variables
is bounded by a constant determined only by the precision of the arithmetic involved. The same goes for any other fundamental operator *, /, etc. Now imagine chaining a whole load of these operations together to get a computation. For straight-line code consisting only of addition and multiplication operators, the result will be polynomial in all your input variables as well as in these error variables  .
.
Once you know that, we can view the problem of determining worst-case accuracy as bounding a polynomial subject to constraints on its variables. There are various ways of bounding polynomials, but David and I were particularly keen to explore options that – while difficult to calculate – might lead to easily verifiable certificates. We ended up using Handelman representations, a particular result from real algebraic geometry.
The manuscript with Magron and Donaldson extends the approach to a more general semialgebraic setting, using recently developed ideas based on hierarchies of semidefinite programming problems that converge to equally certifiable solutions. Specialisations are introduced to deal with some of the complexity and numerical problems that arise, through a particular formulation that exploits sparsity and the numerical properties of the problem at hand. This has produced an open source tool as well as the paper.
This work excites me because it blends some amazing results in real algebraic geometry, some hard problems in program analysis, and some very practical implications for efficient hardware design – especially for FPGA datapath. Apart from the practicalities, algebraic sets are beautiful objects.