Imperial College had the privilege of hosting the 24th IEEE Symposium on Computer Arithmetic (ARITH24) this week, thanks to the local arrangements work of my colleague Dr David Thomas. ARITH is the main conference dedicated solely to questions of computer arithmetic. It’s a small but active and dedicated community with – I would argue – increasing significance in the world of custom and FPGA-based accelerator computation, and I’ve enjoyed being on the Technical Programme Committee of the conference in recent years.
In this post, I describe my personal highlights from the conference.

Nick Higham from the University of Manchester gave the first keynote talk on the rise of mixed precision algorithms. This was an exciting tour de force. Nick highlighted the various floating-point precisions available in modern machines, as well as the move to low-precision computation in areas such as machine learning and ultra-high precision requirements in other areas. The key problem studied in the talk was how to solve systems of linear equations while taking advantage of the availability of mixed precision. Nick traced the idea of solution via iterative refinement of an initial approximate solution back to Wilkinson, and traced its development since then. Nick’s own recent work on this problem, in collaboration with Erin Carson, has been to introduce a method involving three different floating-point precisions. He went on to show how such an approach can produce numerical results equivalent to high precision while the bulk of the work is done in low precision. The approach uses approximate LU factorisation, followed by GMRES iterations. I found the whole approach – especially the analysis – fascinating. Moreover, it was an outstanding example of the link between algorithm development and data type selection, a link which was the topic of my own invited talk at ARITH, which I summarise below.
Gonzalez-Navarro and Hormigo presented an interesting floating-point arithmetic where normalisation is limited for efficiency reasons, and presented some empirical results from applying this to DSP tasks.
Oscar Gustafsson presented a very interesting fixed-point implementation of complex rotations, avoiding roundoff errors for low-complexity computation.
In my talk (extended abstract available here), I acted as devil’s advocate in a session organised by Martin Langhammer from Intel. Martin had invited me to give a talk putting a different perspective than “faster / better floating point.” I decided to do this by (semi-) formalising the joint problem of algorithm / data type design for numerical computation, in order to draw out the main differences between design for general purpose processors and for custom or FPGA implementations. After highlighting these from an abstract perspective, I gave a concrete example due to my PhD student Juan Jerez from a few years ago, before discussing work that is trying to automate the kind of design problems faced in this context. Such work includes bounding numerical errors, refactoring code, and in general synthesising numerical code.
Rocca, Dang, and Magron had a very interesting paper on Certified Roundoff Error Bounds using Bernstein Expansions and Sparse Krivine-Stengle Representations. This is the latest incarnation of work Magron, Donaldson and myself started together when Magron was a postdoc in my group, based in turn on the early work I did with Boland bringing automated roundoff error analysis and real algebraic geometry together. It is exciting to see this work branching off in new ways.
Pasca (Intel) and Istoan (INSA) presented a very nice approach to fixed-point function generation for FPGAs. Istoan will be joining my research group as a postdoctoral researcher in September, and I’m excited to be welcoming his expertise.
I organised a special session on Arithmetic in Digital Signal Processing on the second day of the conference. This featured interesting papers from Serre and Püschel (ETHZ) on optimal streamed linear permutations – I have been a fan of Püschel’s work since the first days of SPIRAL – as well as from Imagination Technologies (Rovers and Elliott), Linköping (Gustafsson, et al.), Intel (both Langhammer and Pasca from Intel PSG and Krishnamurthy.)
Unfortunately, I had to miss more than half of the presentations at ARITH due to an unscheduled hospital trip. So there are probably a huge number of exciting talks I have missed out on discussing here – my apologies to the authors. I will definitely be sure to prioritise ARITH attendance in future years.

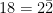 where the bar over a digit indicates a negative digit. But it also has the remarkable property that addition can be performed without inducing carries, leading to the potential for very significant parallelism. I particularly enjoyed that Miloš was able to trace this idea back to the 1700s, in a paper by John Colson, published in the Philosophical Transactions of the Royal Society, entitled
where the bar over a digit indicates a negative digit. But it also has the remarkable property that addition can be performed without inducing carries, leading to the potential for very significant parallelism. I particularly enjoyed that Miloš was able to trace this idea back to the 1700s, in a paper by John Colson, published in the Philosophical Transactions of the Royal Society, entitled