I have been reading Spivak’s book ‘Category Theory for the Sciences’ on-and-off for the last 18 months during vacations as some of my ‘holiday reading.’ I’ve wanted to learn something about category theory for a while, mainly because I feel it’s something that looks fun and different enough to my day-to-day activity not to feel like work. I found Spivak’s book on one of my rather-too-regular bookshop trips a couple of years ago, and since it seemed like a more applied introduction, I thought I’d give it a try. This blog post combines my views on the strengths of this book from the perspective of a mathematically-minded engineer, together with a set of notes on the topic which might be useful for me – and maybe other readers – to refer back to in the future.

The book has a well-defined structure. The first few chapters cover topics that should be familiar to applied mathematicians and engineers: sets, monoids, graphs, orders, etc., but often presented in an unusual way. This sets us up for the middle section of the book which presents basic category theory, showing how the structures previously discussed can be viewed as special cases within a more general framework. The final chapters of the book discuss some topics like monads that can then be explored using the machinery of this framework.
Set
Chapter 3 covers the category 
One of the definitions here that’s less common in engineering is that of coproduct. The coproduct of sets 

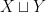
The notation 
To give a flavour of the kind of exercises provided, we are asked to prove an isomorphism 

The fibre product, 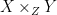


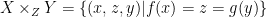

The fibre sum, 
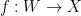



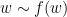



A good intuitive description in the text is to think of the fibre sum of 




The familiar notions of surjective and injective functions are recast as monomorphisms and epimorphisms, respectively. A function 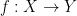







Monoids, Groups, Graphs, Orders & Databases
In Chapter 4, the reader is introduced to several other structures. With the exception of the databases part, this was familiar material to me, but with slightly unfamiliar presentation.
We learn the classical definition of a monoid and group, and also discuss the free monoid generated by a set 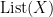



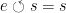







Graphs are dealt with in a slightly unusual way (for me) as quadruples 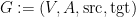



For each of the structures discussed, we finish by looking at their morphisms.
As an example, let 
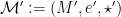
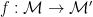
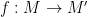

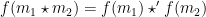
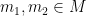
Similarly, for graphs, graph homomorphisms 


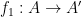


Order morphisms are similarly defined, this time as those preserving order.
Thus we are introduced to several different (somewhat) familiar mathematical structures, and in each case we’re learning about how to describe morphisms on these structures that somehow preserve the structure.
Categories, Functors, and Natural Transformations
Things really heat up in Chapter 5, where we actually begin to cover the meat of category theory. This is exciting and kept me hooked by the pool. The unusual presentation of certain aspects in previous chapters (e.g. the graphs) all made sense during this chapter.
A category 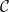




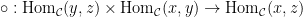
Examples of the category of Monoids, of Groups, of Sets, of Graphs, of Pre-Orders, etc., are explored. Isomorphisms between objects in a category are carefully defined.
Functors are introduced as transformations from one category to another, via a function transforming objects and a function transforming morphisms, such that identities and composition and preserved. Functors are then used to rigorously explore the connections between preorders, graphs, and categories, and I finally understood why the author had focused so much on preorders in the previous chapters!
Things started to take a surprising and exciting turn for me when the author shows, via the use of functors, that a monoid is a category with one object (the set of the monoid becomes the morphisms in the category), and that groups can therefore be understood as categories with one object for which each morphism is an isomorphism. This leads to a playful discussion, out of which pops groupoids, amongst other things. Similar gymnastics lead to preorders reconstituted as categories in which hom-sets have one or fewer elements, and graphs reconstituted as functors from a certain two-object category to
The final part of this chapter deals with natural transformations. Just as functors transform categories to categories, natural transformations transform functors to functors. Specifically, a natural transformation between functor 

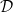



I think this section on natural transformations is where the huge number of exercises in the book really came into its own; I doubt very much I would’ve grasped some of the subtleties of natural transformations without them.
We learn about two kinds of composition of natural transformations. The first combines two natural transformations on functors 

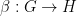
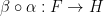

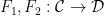



An equivalence relation 


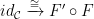
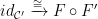
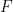
Limits and Colimits
Chapter 6 is primarily given over to the definitions and discussion of limits and colimits, generalising the ideas in 


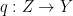



The chapter then further generalises these ideas to the the ideas of limit and colimit. This section was a step up in abstraction and also one of the least “applied” parts of the book. It has certainly piqued my interest – what are limits and colimits in various structures I might use / encounter in my work? – but I found the examples here fairly limited and abstract compared to the copious ones in previous chapters. It’s in this chapter that universal properties begin to rear their head in a major way, and again I’m still not totally intuitively comfortable with this idea – I can crank the handle and answer the exercises, but I don’t feel like I’m yet at home with the idea of universal properties.
Categories at Work
In the final section of the book, we first study adjunctions. Given categories 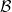
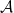
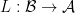


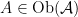
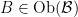

Categories of functors are discussed, leading up to a discussion of the Yoneda lemma. This is really interesting stuff, as it seems to cross huge boundaries of abstraction. Consider a category 

Let 
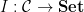

This looks super weird: the right-hand side is just a plain old set and yet the left hand-side seems to be some tower of abstraction. I worked through a couple of examples I dreamt up, namely 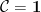



Monads are then covered. I’ve briefly seen monads in a very practical context of functional programming, specifically for dealing with I/O in Haskell, but I’ve never looked at them from a theoretical perspective before.
A monad on 

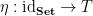




I found this discussion enlightening and relatively straight-forward. Firstly, exception monads are discussed, like Maybe in Haskell, and a nice example of wrapping sets and their functions into power sets and their functions, for which I again enjoyed the exercises. Kleisli categories of monads are defined, and it then becomes apparent why this is such a powerful formalism to think about concepts like program state and I/O.
The Kleisli category 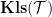
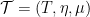




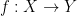



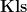
Finally, the book ends with a (very) brief discussion of operads. I’ve not come across operads before, and from this brief discussion I’m not really sure what they ‘buy’ me beyond monoidal categories.
General
The exercises are copious and great, especially in the earlier chapters. They kept me engaged throughout and helped me to really understand what I was reading, rather than just think I had. In the later exercises there are many special cases that turn out to be more familiar things. This is both enlightening “oh, an X is just a Y!” and frustrating “yeah, but I want to see Xs that aren’t Ys, otherwise what’s this all heavyweight general machinery for?” I guess this comes from trying to cover a lot of ground in one textbook.
I am struck by just how much mental gymnastics I feel I had to go through to see mathematical structures from the “outside in” as well as from the “inside out”, and how category theory helped me do that. This is a pleasing feeling.
The slogans are great and often amusing, e.g. when describing a functor from the category of Monoids to the category of Sets, “you can use a smartphone as a paperweight.”
The book ends rather abruptly after the brief discussion of operads, with no conclusion. I felt it would be nice to have a summary discussion, and perhaps point out the current directions the field of applied category theory is taking.
Overall, this book has been an enlightening read. It has helped me to see the commonality behind several disparate mathematical structures, and has encouraged me to look for such commonality and relationships in my own future work. Recommended!
