This post contains some summary informal notes of key ideas from my reading of Mícheál Ó Searcóid’s Metric Spaces (Springer, 2007). These notes are here as a reference for me, my students, and any others who may be interested. They are by no means exhaustive, but rather cover topics that seemed interesting to me on first reading. By way of a brief book review, it’s worth noting that Ó Searcóid’s approach is excellent for learning a subject. He has a few useful tricks up his sleeve, in particular:
- Chapters will often start with a theorem proving equivalence of various statements (e.g. Theorem 8.1.1, Criteria for Continuity at a Point). Only then will he choose one of these statements as a definition, and he explains this choice carefully, often via reference to other mathematics.
- The usual definition-theorem-proof style is supplemented with ‘question’ – these are relatively informally-stated questions and their answers. They have been carefully chosen to highlight some questions the reader might be wondering about at that point in the text and to demonstrate key (and sometimes surprising) answers before the formal theorem statement.
- The writing is pleasant, even playful at times though never lacking formality. This is a neat trick to pull off.
- There are plenty of exercises, and solutions are provided.
These features combine to produce an excellent learning experience.
1. Some Basic Definitions
A metric on a set X is a function  such that:
such that:
- Positivity:
 with equality iff
with equality iff 
- Symmetry:

- Triangle inequality:
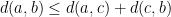
The combination of such a metric and a the corresponding set is a metric space.
Given a metric space  , the point function at
, the point function at  is
is  .
.
A pointlike function  is one where
is one where 
For metric spaces and  ,
,  is a metric subspace of
is a metric subspace of  iff
iff  and
and  is a restriction of
is a restriction of  .
.
For metric spaces and , an isometry  is a function such that
is a function such that 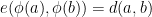 . The metric subspace
. The metric subspace 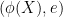 is an isometric copy of .
is an isometric copy of .
Some standard constructions of metrics for product spaces:
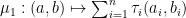

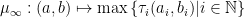
A conserving metric on a product space is one where 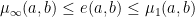 . Ó Searcóid calls these conserving metrics because they conserve an isometric copy of the individual spaces, recoverable by projection (I don’t think this is a commonly used term). This can be seen because fixing elements of all-but-one of the constituent spaces makes the upper and lower bound coincide, resulting in recovery of the original metric.
. Ó Searcóid calls these conserving metrics because they conserve an isometric copy of the individual spaces, recoverable by projection (I don’t think this is a commonly used term). This can be seen because fixing elements of all-but-one of the constituent spaces makes the upper and lower bound coincide, resulting in recovery of the original metric.
A norm on a linear space  over
over 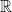 or
or 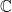 is a real function such that for
is a real function such that for 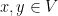 and
and  scalar:
scalar:
The metric defined by the norm is  .
.
2. Distances
The diameter of a set  of metric space is
of metric space is 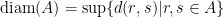 .
.
The distance of a point  from a set is
from a set is  .
.
An isolated point 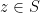 where
where  is one for which
is one for which 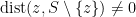 .
.
An accumulation point or limit point 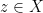 of is one for which
of is one for which 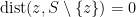 . Note that doesn’t need to be in
. Note that doesn’t need to be in  . A good example is
. A good example is  ,
, 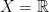 ,
, 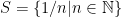 .
.
The distance from subset  to subset
to subset  of a metric space is defined as
of a metric space is defined as 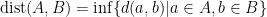 .
.
A nearest point  of to is one for which
of to is one for which 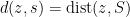 . Note that nearest points don’t need to exist, because
. Note that nearest points don’t need to exist, because  is defined via the infimum. If a metric space is empty or admits a nearest point to each point in every metric superspace, it is said to have the nearest-point property.
is defined via the infimum. If a metric space is empty or admits a nearest point to each point in every metric superspace, it is said to have the nearest-point property.
3. Boundaries
A point  is a boundary point of in iff
is a boundary point of in iff  . The collection of these points is the boundary
. The collection of these points is the boundary  .
.
Metric spaces with no proper non-trivial subset with empty boundary are connected. An example of a disconnected metric space is  as a metric subspace of , while itself is certainly connected.
as a metric subspace of , while itself is certainly connected.
Closed sets are those that contain their boundary.
The closure of in is  . The interior is
. The interior is  . The exterior is
. The exterior is 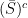 .
.
Interior, boundary, and exterior are mutually disjoint and their union is .
4. Sub- and super-spaces
A subset is dense in iff 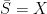 , or equivalently if for every ,
, or equivalently if for every ,  . The archetypal example is that
. The archetypal example is that 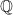 is dense in
is dense in 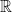 .
.
A complete metric space is one that is closed in every metric superspace of . An example is .
5. Balls
Let  denote an open ball and similarly
denote an open ball and similarly ![b[a;r] = \{ x \in X | d(a,x) \leq r \}](https://s0.wp.com/latex.php?latex=b%5Ba%3Br%5D+%3D+%5C%7B+x+%5Cin+X+%7C+d%28a%2Cx%29+%5Cleq+r+%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) denote a closed ball. In the special case of normed linear spaces,
denote a closed ball. In the special case of normed linear spaces,  and similarly for closed balls, so the important object is this unit ball – all others have the same shape. A norm on a space is actually defined by three properties such balls
and similarly for closed balls, so the important object is this unit ball – all others have the same shape. A norm on a space is actually defined by three properties such balls  must have:
must have:
- Convexity
- Balanced (i.e.
 )
) - For each
 , the set
, the set  ,
,
- is nonempty
- must have real supremum

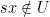
6. Convergence
The  th tail of a sequence
th tail of a sequence 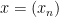 is the set
is the set 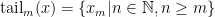 .
.
Suppose is a metric space, and  is a sequence in . Sequence
is a sequence in . Sequence  converges to in , denoted
converges to in , denoted 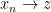 iff every open subset of that contains includes a tail of . In this situation, is unique and is called the limit of the sequence, denoted
iff every open subset of that contains includes a tail of . In this situation, is unique and is called the limit of the sequence, denoted  .
.
It follows that for a metric space, and  a sequence in , the sequence converges to in iff the real sequence
a sequence in , the sequence converges to in iff the real sequence  converges to
converges to  in .
in .
For real sequences, we can define the:
- limit superior,
 and
and - limit inferior,
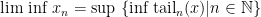 .
.
It can be shown that iff  .
.
Clearly sequences in superspaces converge to the same limit – the same is true in subspaces if the limit point is in the subspace itself. Sequences in finite product spaces equipped with product metrics converge in the product space iff their projections onto the individual spaces converge.
Every subsequence of a convergent sequence converges to the same limit as the parent sequence, but the picture for non-convergent parent sequences is more complicated, as we can still have convergent subsequences. There are various equivalent ways of characterising these limits of subsequences, e.g. centres of balls containing an infinite number of terms of the parent sequence.
A sequence is Cauchy iff for every 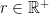 , there is a ball of radius
, there is a ball of radius  that includes a tail of . Every convergent sequence is Cauchy. The converse is not true, but only if the what should be the limit point is missing from the space — adding this point and extending the metric appropriately yields a convergent sequence. It can be shown that a space is complete (see above for definition) iff every Cauchy sequence is also a convergent sequence in that space.
that includes a tail of . Every convergent sequence is Cauchy. The converse is not true, but only if the what should be the limit point is missing from the space — adding this point and extending the metric appropriately yields a convergent sequence. It can be shown that a space is complete (see above for definition) iff every Cauchy sequence is also a convergent sequence in that space.
7. Bounds
A subset of a metric space is a bounded subset iff  or is included in some ball of . A metric space is bounded iff it is a bounded subset of itself. An alternative characterisation of a bounded subset is that it has finite diameter.
or is included in some ball of . A metric space is bounded iff it is a bounded subset of itself. An alternative characterisation of a bounded subset is that it has finite diameter.
The Hausdorff metric is defined on the set  of all non-empty closed bounded subsets of a set equipped with metric . It is given by
of all non-empty closed bounded subsets of a set equipped with metric . It is given by  .
.
Given a set and a metric space , 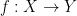 is a bounded function iff
is a bounded function iff 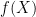 is a bounded subset of . The set of bounded functions from to is denoted
is a bounded subset of . The set of bounded functions from to is denoted 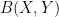 . There is a standard metric on bounded functions,
. There is a standard metric on bounded functions,  where is the metric on .
where is the metric on .
Let be a nonempty set and be a nonempty metric space. Let  be a sequence of functions from to and
be a sequence of functions from to and  . Then:
. Then:
- converges pointwise to
 iff
iff  converges to
converges to  for all
for all - converges uniformly to iff
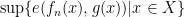 is real for each
is real for each 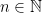 and the sequence
and the sequence  converges to zero in .
converges to zero in .
It’s interesting to look at these two different notions of convergence because the second is stronger. Every uniformly-convergent sequence of functions converges pointwise, but the converse is not true. An example is the sequence  given by
given by  . This converges pointwise but not uniformly to the zero function.
. This converges pointwise but not uniformly to the zero function.
A stronger notion than boundedness is total boundedness. A subset of a metric space is totally bounded iff for each  , there is a finite collection of balls of of radius that covers . An example of a bounded but not totally bounded subset is any infinite subset of a space with the discrete metric. Total boundedness carries over to subspaces and finite unions.
, there is a finite collection of balls of of radius that covers . An example of a bounded but not totally bounded subset is any infinite subset of a space with the discrete metric. Total boundedness carries over to subspaces and finite unions.
Conserving metrics play an important role in bounds, allowing bounds on product spaces to be equivalent to bounds on the projections to the individual spaces. This goes for both boundedness and total boundedness.
8. Continuity
Given metric spaces and , a point and a function 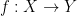 , the function is said to be continuous at iff for each open subset
, the function is said to be continuous at iff for each open subset  with
with 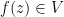 , there exists and open subset of with
, there exists and open subset of with  such that
such that  .
.
Extending from points to the whole domain, the function is said to be continuous on iff for each open subset , 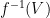 is open in .
is open in .
Continuity is not determined by the codomain, in the sense that a continuous function is continuous on any metric superspace of its range. It is preserved by function composition and by restriction.
Continuity plays well with product spaces, in the sense that if the product space is endowed with a product metric, a function mapping into the product space is continuous iff its compositions with the natural projections are all continuous.
For and metric spaces,  denotes the metric space of continuous bounded functions from to with the supremum metric
denotes the metric space of continuous bounded functions from to with the supremum metric  . is closed in the space of bounded functions from to .
. is closed in the space of bounded functions from to .
Nicely, we can talk about convergence using the language of continuity. In particular, let be a metric space, and  . Endow
. Endow  with the inverse metric
with the inverse metric  for
for 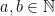 ,
,  and
and 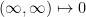 . Let
. Let  . Then
. Then  is continuous iff the sequence converges in to
is continuous iff the sequence converges in to  . In particular, the function extending each convergent sequence with its limit is an isometry from the space of convergent sequences in to the metric space of continuous bounded functions from to .
. In particular, the function extending each convergent sequence with its limit is an isometry from the space of convergent sequences in to the metric space of continuous bounded functions from to .
9. Uniform Continuity
Here we explore increasing strengths of continuity: Lipschitz continuity > uniform continuity > continuity. Ó Searcóid also adds strong contractions into this hierarchy, as the strongest class studied.
Uniform continuity requires the  in the epsilon-delta definition of continuity to extend across a whole set. Consider metric spaces and , a function , and a metric subspace . The function
in the epsilon-delta definition of continuity to extend across a whole set. Consider metric spaces and , a function , and a metric subspace . The function  is uniformly continuous on iff for every
is uniformly continuous on iff for every  there exists a
there exists a 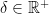 s.t. for every
s.t. for every  for which
for which 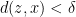 , it holds that
, it holds that  .
.
If is a metric space with the nearest-point property and is continuous, then is also uniformly continuous on every bounded subset of . A good example might be a polynomial on .
Uniformly continuous functions map compact metric spaces into compact metric spaces. They preserve total boundedness and Cauchy sequences. This isn’t necessarily true for continuous functions, e.g. 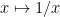 on
on ![(0,1]](https://s0.wp.com/latex.php?latex=%280%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) does not preserve the Cauchy property of the sequence
does not preserve the Cauchy property of the sequence  .
.
There is a remarkable relationship between the Cantor Set and uniform continuity. Consider a nonempty metric space . Then is totally bounded iff there exists a bijective uniformly continuous function from a subset of the Cantor Set to . As Ó Searcóid notes, this means that totally bounded metric spaces are quite small, in the sense that none can have cardinality greater than that of the reals.
Consider metric spaces and and function . The function is called Lipschitz with Lipschitz constant  iff
iff  for all
for all  .
.
Note here the difference to uniform continuity: Lipschitz continuity restricts uniform continuity by describing a relationship that must exist between the  s and s – uniform leaves this open. A nice example from Ó Searcóid of a uniformly continuous non-Lipschitz function is
s and s – uniform leaves this open. A nice example from Ó Searcóid of a uniformly continuous non-Lipschitz function is 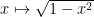 on
on  .
.
Lipschitz functions preserve boundedness, and the Lipschitz property is preserved by function composition.
There is a relationship between Lipschitz functions on the reals and their differentials. Let  be a non-degenerate intervals of and
be a non-degenerate intervals of and 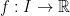 . Then is Lipschitz on iff
. Then is Lipschitz on iff  is bounded on .
is bounded on .
A function with Lipschitz constant less than one is called a strong contraction.
Unlike the case for continuity, not every product metric gives rise to uniformly continuous natural projections, but this does hold for conserving metrics.
10. Completeness
Let be a metric space and 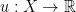 . The function
. The function  is called a virtual point iff:
is called a virtual point iff:
We saw earlier that a metric space is complete iff it is closed in every metric superspace of . There are a number of equivalent characterisations, including that every Cauchy sequence in converses in .
Consider a metric space . A subset of is a complete subset of iff  is a complete metric space.
is a complete metric space.
If is a complete metric space and , then is complete iff is closed in .
Conserving metrics ensure that finite products of complete metric spaces are complete.
A non-empty metric space is complete iff 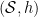 is complete, where
is complete, where 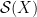 denotes the collection of all non-empty closed bounded subsets of and
denotes the collection of all non-empty closed bounded subsets of and  denotes the Hausdorff metric.
denotes the Hausdorff metric.
For a non-empty set and a metric space, the metric space of bounded functions from to with the supremum metric is a complete metric space iff is complete. An example is that the space of bounded sequences in is complete due to completeness of .
We can extend uniformly continuous functions from dense subsets to complete spaces to unique uniformly continuous functions from the whole: Consider metric spaces and with the latter being complete. Let be a dense subset of and  be a uniformly continuous function. Then there exists a uniformly continuous function
be a uniformly continuous function. Then there exists a uniformly continuous function 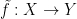 such that
such that 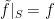 . There are no other continuous extensions of to .
. There are no other continuous extensions of to .
(Banach’s Fixed-Point Theorem). Let be a non-empty complete metric space and 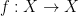 be a strong contraction on with Lipschitz constant
be a strong contraction on with Lipschitz constant  . Then has a unique fixed point in and, for each
. Then has a unique fixed point in and, for each  , the sequence
, the sequence  converges to the fixed point. Beautiful examples of this abound, of course. Ó Searcóid discusses IFS fractals – computer scientists will be familiar with applications in the semantics of programming languages.
converges to the fixed point. Beautiful examples of this abound, of course. Ó Searcóid discusses IFS fractals – computer scientists will be familiar with applications in the semantics of programming languages.
A metric space is called a completion of metric space iff is complete and is isometric to a dense subspace of .
We can complete any metric space. Let be a metric space. Define  where
where  denotes the set of all point functions in and
denotes the set of all point functions in and  denotes the set of all virtual points in . We can endow
denotes the set of all virtual points in . We can endow  with the metric given by
with the metric given by  . Then is a completion of .
. Then is a completion of .
Here the subspace  of
of  forms the subspace isometric to .
forms the subspace isometric to .
11. Connectedness
A metric space is a connected metric space iff cannot be expressed as the union of two disjoint nonempty open subsets of itself. An example is with its usual metric. As usual, Ó Searcóid gives a number of equivalent criteria:
- Every proper nonempty subset of has nonempty boundary in
- No proper nonempty subset of is both open and closed in
- is not the union of two disjoint nonempty closed subsets of itself
- Either
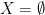 or the only continuous functions from to the discrete space
or the only continuous functions from to the discrete space  are the two constant functions
are the two constant functions
Connectedness is not a property that is relative to any metric superspace. In particular, if is a metric space,  is a metric subspace of and
is a metric subspace of and  , then the subspace of is a connected metric space iff the subspace of is a connected metric space. Moreover, for a connected subspace of with
, then the subspace of is a connected metric space iff the subspace of is a connected metric space. Moreover, for a connected subspace of with 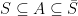 , the subspace is connected. In particular,
, the subspace is connected. In particular, 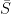 itself is connected.
itself is connected.
Every continuous image of a connected metric space is connected. In particular, for nonempty  , is connected iff is an interval. This is a generalisation of the Intermediate Value Theorem (to see this, consider the continuous functions
, is connected iff is an interval. This is a generalisation of the Intermediate Value Theorem (to see this, consider the continuous functions 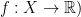 .
.
Finite products of connected subsets endowed with a product metric are connected. Unions of chained collections (i.e. sequences of subsets whose sequence neighbours are non-disjoint) of connected subsets are themselves connected.
A connected component of a metric space is a subset that is connected and which has no proper superset that is also connected – a kind of maximal connected subset. It turns out that the connected components of a metric space are mutually disjoint, all closed in , and is the union of its connected components.
A path in metric space is a continuous function ![f : [0, 1] \to X](https://s0.wp.com/latex.php?latex=f+%3A+%5B0%2C+1%5D+%5Cto+X&bg=ffffff&fg=000000&s=0&c=20201002) . (These functions turn out to be uniformly continuous.) This definition allows us to consider a stronger notion of connectedness: a metric space is pathwise connected iff for each there is a path in with endpoints and
. (These functions turn out to be uniformly continuous.) This definition allows us to consider a stronger notion of connectedness: a metric space is pathwise connected iff for each there is a path in with endpoints and  . An example given by Ó Searcóid of a space that is connected but not pathwise connected is the closure in
. An example given by Ó Searcóid of a space that is connected but not pathwise connected is the closure in  of
of  . From one of the results above,
. From one of the results above,  is connected because
is connected because  is connected. But there is no path from, say,
is connected. But there is no path from, say, 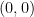 (which nevertheless is in ) to any point in .
(which nevertheless is in ) to any point in .
Every continuous image of a pathwise connected metric space is itself pathwise connected.
For a linear space, an even stronger notion of connectedness is polygonal connectedness. For a linear space with subset and 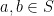 , a polygonal connection from to in is an
, a polygonal connection from to in is an  -tuple of points
-tuple of points 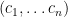 s.t.
s.t. 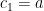 ,
, 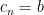 and for each
and for each 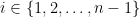 ,
, ![\{(1 - t)c_i + t c_{i+1} | t \in [0,1] \} \subseteq S](https://s0.wp.com/latex.php?latex=%5C%7B%281+-+t%29c_i+%2B+t+c_%7Bi%2B1%7D+%7C+t+%5Cin+%5B0%2C1%5D+%5C%7D+%5Csubseteq+S&bg=ffffff&fg=000000&s=0&c=20201002) . We then say a space is polygonally connected iff there exists a polygonal connection between every two points in the space. Ó Searcóid gives the example of
. We then say a space is polygonally connected iff there exists a polygonal connection between every two points in the space. Ó Searcóid gives the example of  as a pathwise connected but not polygonally connected subset of
as a pathwise connected but not polygonally connected subset of 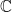 .
.
Although in general these three notions of connectedness are distinct, they coincide for open connected subsets of normed linear spaces.
12. Compactness
Ó Searcóid gives a number of equivalent characterisations of compact non-empty metric spaces , some of the ones I found most interesting and useful for the following material include:
- Every open cover for has a finite subcover
- is complete and totally bounded
- is a continuous image of the Cantor set
- Every real continuous function defined on is bounded and attains its bounds
The example is given of closed bounded intervals of as archetypal compact sets. An interesting observation is given that ‘most’ metric spaces cannot be extended to compact metric spaces, simply because there aren’t many compact metric spaces — as noted above in the section on bounds, there are certainly no more than  , given they’re all images of the Cantor set.
, given they’re all images of the Cantor set.
If is a compact metric space and then is compact iff is closed in . This follows because inherits total boundedness from , and completeness follows also if is closed.
The Inverse Function Theorem states that for and metric spaces with compact, and for injective and continuous,  is uniformly continuous.
is uniformly continuous.
Compactness plays well with intersections, finite unions, and finite products endowed with a product metric. The latter is interesting, given that we noted above that for non conserving product metrics, total boundedness doesn’t necessarily carry forward.
Things get trickier when dealing with infinite-dimension spaces. The following statement of the Arzelà-Ascoli Theorem is given, which allows us to characterise the compactness of a closed, bounded subset of for compact metric spaces and :
For each , define 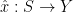 by
by  for each
for each  . Let
. Let  . Then:
. Then:
 and
and- is compact iff
 from to
from to  is continuous
is continuous
13. Equivalence
Consider a set and the various metrics we can equip it with. We can define a partial order 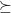 on these metrics in the following way. is topologically stronger than ,
on these metrics in the following way. is topologically stronger than ,  iff every open subset of
iff every open subset of  is open in . We then get an induced notion of topological equivalence of two metrics, when and
is open in . We then get an induced notion of topological equivalence of two metrics, when and  .
.
As well as obviously admitting the same open subsets, topologically equivalent metrics admit the same closed subsets, dense subsets, compact subsets, connected subsets, convergent sequences, limits, and continuous functions to/from that set.
It turns out that two metrics are topologically equivalent iff the identity functions from to and vice versa are both continuous. Following the discussion above relating to continuity, this hints at potentially stronger notions of comparability – and hence of equivalence – of metrics, which indeed exist. In particular is uniformly stronger than iff the identify function from to is uniformly continuous. Also, is Lipschitz stronger than iff the identity function from to is Lipschitz.
The stronger notion of a uniformly equivalent metric is important because these metrics additionally admit the same Cauchy sequences, totally bounded subsets and complete subsets.
Lipschitz equivalence is even stronger, additionally providing the same bounded subsets and subsets with the nearest-point property.
The various notions of equivalence discussed here collapse to a single one when dealing with norms. For a linear space , two norms on are topologically equivalent iff they are Lipschitz equivalent, so we can just refer to norms as being equivalent. All norms on finite-dimensional linear spaces are equivalent.
Finally, some notes on the more general idea of equivalent metric spaces (rather than equivalent metrics.) Again, these are provided in three flavours:
- topologically equivalent metric spaces and are those for which there exists a continuous bijection with continuous inverse (a homeomorphism) from to .
- for uniformly equivalent metric spaces, we strengthen the requirement to uniform continuity
- for Lipschitz equivalent metric spaces, we strengthen the requirement to Lipschitz continuity
- strongest of all, isometries are discussed above
Note that given the definitions above, the metric space is equivalent to the metric space if and are equivalent, but the converse is not necessarily true. For equivalent metric spaces, we require existence of a function — for equivalent metrics this is required to be the identity.

 consists of a set of relation symbols, a set of function symbols, a set of constant symbols and, for each relation and function symbol, a positive number known as its arity. The set of all these symbols is denoted
consists of a set of relation symbols, a set of function symbols, a set of constant symbols and, for each relation and function symbol, a positive number known as its arity. The set of all these symbols is denoted 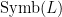 .
.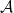 consists of a set
consists of a set  of arity
of arity  of
of 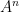 ; for each function symbol
; for each function symbol  ; for each constant symbol
; for each constant symbol  , a value
, a value  .
. be
be 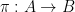 s.t.: for all relation symbols
s.t.: for all relation symbols  ,
, 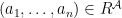 iff
iff 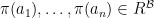 ; for all function symbols
; for all function symbols 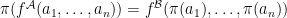 ; for all constant symbols
; for all constant symbols  .
. is an isomorphism iff there is an embedding
is an isomorphism iff there is an embedding  s.t.
s.t.  is the identity on
is the identity on  is the identity on
is the identity on 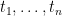 are terms of
are terms of 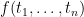 is a term; only something built from the preceding clauses in finitely many steps is a term.
is a term; only something built from the preceding clauses in finitely many steps is a term. and
and 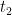 are terms, then
are terms, then  is a formula; if
is a formula; if  are terms and
are terms and  is a formula; if
is a formula; if 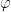 and
and 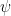 are formulas, then
are formulas, then  and
and 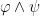 are formulas; if
are formulas; if ![\exists x[\varphi]](https://s0.wp.com/latex.php?latex=%5Cexists+x%5B%5Cvarphi%5D&bg=ffffff&fg=000000&s=0&c=20201002) is a formula; only something built from the preceding four clauses in finitely many steps is a formula. We will write
is a formula; only something built from the preceding four clauses in finitely many steps is a formula. We will write 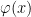 for a formula with free variables
for a formula with free variables 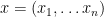 in some defined order.
in some defined order. for some
for some 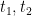 or of the form
or of the form  for some relation symbol
for some relation symbol  are atomic formulas.
are atomic formulas. be a term of
be a term of  be a list of variables including all those appearing in
be a list of variables including all those appearing in  is a function from
is a function from  to
to 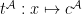 ; if
; if  then
then 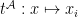 ; if
; if 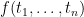 then
then 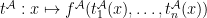 .
. (read
(read 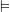 as ‘models’) recursively as:
as ‘models’) recursively as:  iff
iff  ;
; 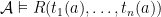 iff
iff 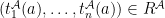 ;
;  iff
iff  ;
; 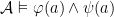 iff
iff 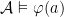 and
and  ;
; ![\mathcal{A} \vDash \exists x[\varphi(x,a)]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BA%7D+%5CvDash+%5Cexists+x%5B%5Cvarphi%28x%2Ca%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) iff there is some
iff there is some  s.t.
s.t.  .
.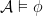 we say
we say  , we say that
, we say that 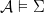 ) iff it is a model of all sentences in
) iff it is a model of all sentences in  if every model of
if every model of  , if
, if 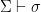 then
then  .
. .
. is the set of all
is the set of all 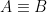 iff for every
iff for every 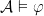 iff
iff 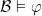 .
. 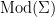 the class of all
the class of all  be an axiomatisable class with arbitrarily large finite models (i.e. for every
be an axiomatisable class with arbitrarily large finite models (i.e. for every 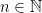 there is a model
there is a model  whose domain is finite and of size at least
whose domain is finite and of size at least  and
and  for the cardinality of language
for the cardinality of language  .
. .
. 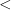 relation and
relation and 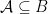 ,
, 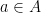 , then
, then  .
.![\exists x[ x < 0 ]](https://s0.wp.com/latex.php?latex=%5Cexists+x%5B+x+%3C+0+%5D&bg=ffffff&fg=000000&s=0&c=20201002) clearly has a model in the integers but not in the naturals.
clearly has a model in the integers but not in the naturals.  , iff
, iff  ,
, 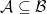 be an
be an 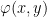 and every
and every  and
and 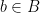 such that
such that  , there is
, there is  such that
such that 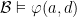 . Then
. Then  . Then there exists an elementary substructure
. Then there exists an elementary substructure  such that
such that  and
and 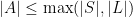 .
.  , there exists an
, there exists an  such that
such that 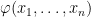 s.t.
s.t.  .
.  is a definable set and
is a definable set and  is an automorphism of
is an automorphism of 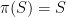 .
. ). We will write
). We will write  for the set of all definable subsets of
for the set of all definable subsets of  , every definable subset of
, every definable subset of  has quantifier elimination iff for every
has quantifier elimination iff for every  , there is a quantifier-free
, there is a quantifier-free  such that
such that ![T \vdash \forall x [\varphi(x) \leftrightarrow \theta(x)]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cforall+x+%5B%5Cvarphi%28x%29+%5Cleftrightarrow+%5Ctheta%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.  ). Given an
). Given an  by adding a new distinct constant symbol
by adding a new distinct constant symbol  for every
for every  of a
of a  is a complete
is a complete  for
for 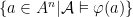 .
. 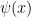 such that: (i)
such that: (i) ![T \vdash \exists x [\psi(x)]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cexists+x+%5B%5Cpsi%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) , (ii) for every
, (ii) for every ![T \vdash \forall x[ \psi(x) \to \varphi(x) ]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cforall+x%5B+%5Cpsi%28x%29+%5Cto+%5Cvarphi%28x%29+%5D&bg=ffffff&fg=000000&s=0&c=20201002) or
or ![T \vdash \forall x[ \psi(x) \to \neg \varphi(x)]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cforall+x%5B+%5Cpsi%28x%29+%5Cto+%5Cneg+%5Cvarphi%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.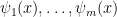 be principal formulas in
be principal formulas in  . Then every definable set in
. Then every definable set in  , and
, and 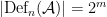 .
. and
and  -categorical) theories. It turns out that countably categorical complete theories are exactly those whose models have only finitely many definable subsets for each fixed dimension:
-categorical) theories. It turns out that countably categorical complete theories are exactly those whose models have only finitely many definable subsets for each fixed dimension:  ,
, 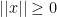 with equality iff
with equality iff 



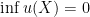


 of sets.
of sets.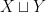 is defined as the disjoint union of
is defined as the disjoint union of  is used for the set of functions from
is used for the set of functions from  . This reminds me of digital circuit construction: the former corresponds to a time-multiplexed circuit capable of producing outputs from
. This reminds me of digital circuit construction: the former corresponds to a time-multiplexed circuit capable of producing outputs from 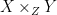 , given functions
, given functions  and
and  is defined as the set
is defined as the set 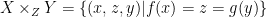 . Any set isomorphic to this fibre product is called a pullback of the diagram
. Any set isomorphic to this fibre product is called a pullback of the diagram  .
. , given functions
, given functions 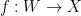 and
and  is the quotient of
is the quotient of  by the equivalence relation
by the equivalence relation  generated by
generated by 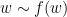 and
and  for all
for all  . A pushout of
. A pushout of 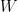 is any set
is any set 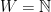 ,
,  ,
,  . Then we’re left with
. Then we’re left with  , where
, where  is an element corresponding to the collapsing of all negative elements in
is an element corresponding to the collapsing of all negative elements in  , if
, if  then
then  . A function
. A function  , if
, if  then
then  . By this time in the book, we get the hint that we’re learning this new language as it will generalise later beyond functions from sets to sets – the chapter ends with various slightly more structured concepts, like set-indexed functions, where the idea is always to define the object and the type of morphism that might make sense for that object.
. By this time in the book, we get the hint that we’re learning this new language as it will generalise later beyond functions from sets to sets – the chapter ends with various slightly more structured concepts, like set-indexed functions, where the idea is always to define the object and the type of morphism that might make sense for that object.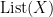 of lists of elements of
of lists of elements of  associated with the monoid
associated with the monoid  having the properties
having the properties 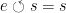 for any
for any  , where
, where  , where
, where  is the monoid operation. The discussion of monoids is nice and detailed, and I enjoyed the exercises, especially those leading up to one of the author’s slogans: “A finite state machine is an action of a free monoid on a finite set.”
is the monoid operation. The discussion of monoids is nice and detailed, and I enjoyed the exercises, especially those leading up to one of the author’s slogans: “A finite state machine is an action of a free monoid on a finite set.”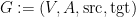 of a set of vertices
of a set of vertices  ,
,  mapping each arrow into its source and destination vertex. This corresponds then to what I would call a multigraph, as parallel edges can exist, though it is called a graph in the book.
mapping each arrow into its source and destination vertex. This corresponds then to what I would call a multigraph, as parallel edges can exist, though it is called a graph in the book. and
and 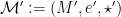 be monoids (the tuple is of the set, identity element, and operation). Then a monoid homomorphism
be monoids (the tuple is of the set, identity element, and operation). Then a monoid homomorphism 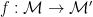 is a function
is a function 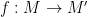 preserving identity and operation, i.e. (i)
preserving identity and operation, i.e. (i)  and
and 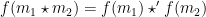 for all
for all 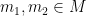 .
. for
for  are defined as pairs of functions
are defined as pairs of functions  and
and 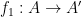 preserving the endpoints of arrows, i.e. such that the diagrams below commute.
preserving the endpoints of arrows, i.e. such that the diagrams below commute.

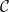 is defined as a collection of various things: a set of objects
is defined as a collection of various things: a set of objects  , a set of morphisms
, a set of morphisms 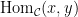 for every pair of objects
for every pair of objects  , a specified identity morphism
, a specified identity morphism  for every object
for every object 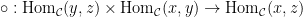 . To qualify as a category, such things must satisfy identity laws and also associativity of composition.
. To qualify as a category, such things must satisfy identity laws and also associativity of composition. and
and  is defined as a morphism (in
is defined as a morphism (in 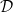 )
)  for each object
for each object  , such that the diagram below commutes for every morphism
, such that the diagram below commutes for every morphism 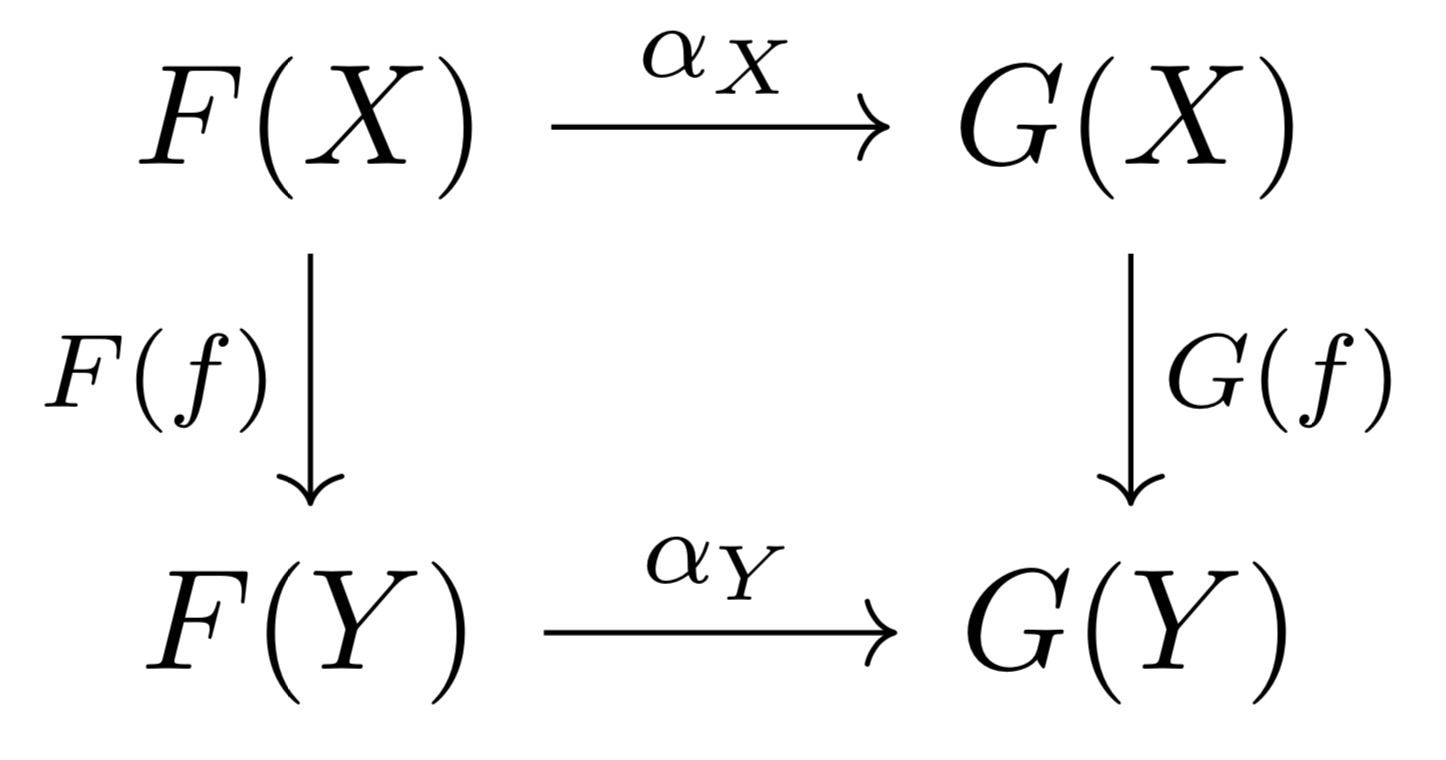
 , say one
, say one  and one
and one 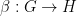 to obtain a natural transformation
to obtain a natural transformation 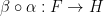 . The other combines a natural transformation
. The other combines a natural transformation  between functors
between functors 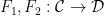 with one
with one  between functors
between functors  , to produce one,
, to produce one,  .
. – weaker than isomorphism – is introduced on categories as a functor
– weaker than isomorphism – is introduced on categories as a functor  such that there exists a functor
such that there exists a functor  and natural isomorphisms
and natural isomorphisms 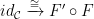 and
and 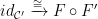 . This seemed odd to me — the lack of insistence on isomorphism for equivalence — but the examples all make sense. More importantly it is shown that this requirement is sufficient for the on-homomorphism part of the functor
. This seemed odd to me — the lack of insistence on isomorphism for equivalence — but the examples all make sense. More importantly it is shown that this requirement is sufficient for the on-homomorphism part of the functor 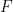 to be bijective for every fixed pair of objects in
to be bijective for every fixed pair of objects in  , a span is defined as a triple
, a span is defined as a triple  where
where  and
and 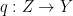 are morphisms in
are morphisms in  is then defined as as span on
is then defined as as span on  such that the following diagram commutes. Again, I rather like the author’s slogan for this: “none shall map to
such that the following diagram commutes. Again, I rather like the author’s slogan for this: “none shall map to 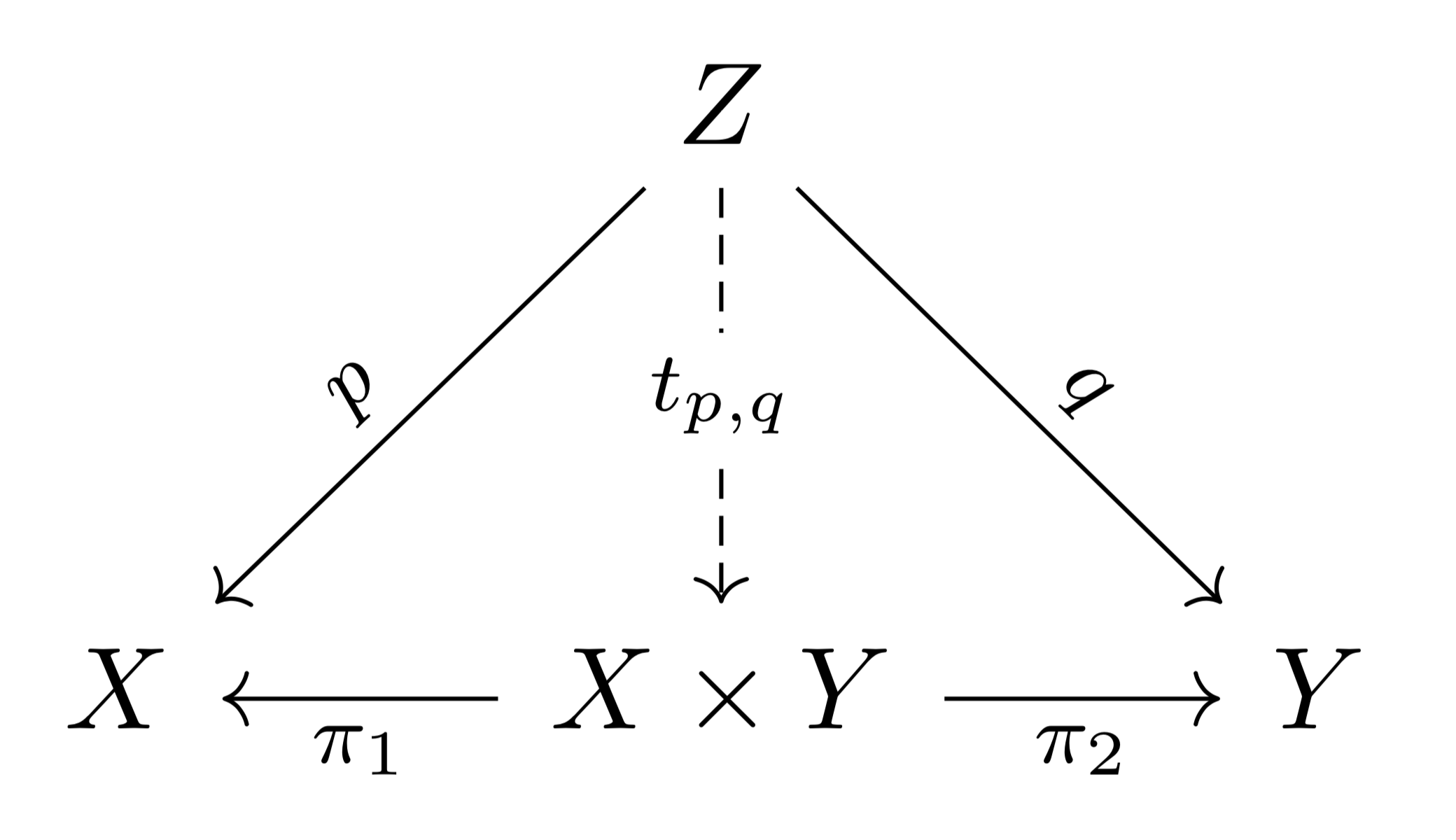
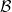 and
and 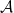 , an adjunction is defined as a pair of functors
, an adjunction is defined as a pair of functors 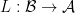 and
and  together with a natural isomorphism
together with a natural isomorphism 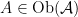 ,
, 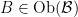 is
is  . Several preceding results and examples can then be re-expressed in this framework, and understood as examples of adjunctions. Adjuctions are also revisited later in the chapter to show a close link with monads.
. Several preceding results and examples can then be re-expressed in this framework, and understood as examples of adjunctions. Adjuctions are also revisited later in the chapter to show a close link with monads. sending objects in
sending objects in  and similarly for morphisms. This is then used in the following theorem:
and similarly for morphisms. This is then used in the following theorem: be an object, and
be an object, and 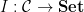 be a set-valued functor. There is a natural bijection
be a set-valued functor. There is a natural bijection  .
.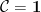 (the category with one object) with
(the category with one object) with  with
with  and convinced myself this works just fine for those two examples. Unfortunately, the general proof is not covered in the book – readers are referred to
and convinced myself this works just fine for those two examples. Unfortunately, the general proof is not covered in the book – readers are referred to  consisting of a functor
consisting of a functor  , a natural transformation
, a natural transformation 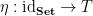 , and natural transformation
, and natural transformation  such that the following diagrams commute:
such that the following diagrams commute: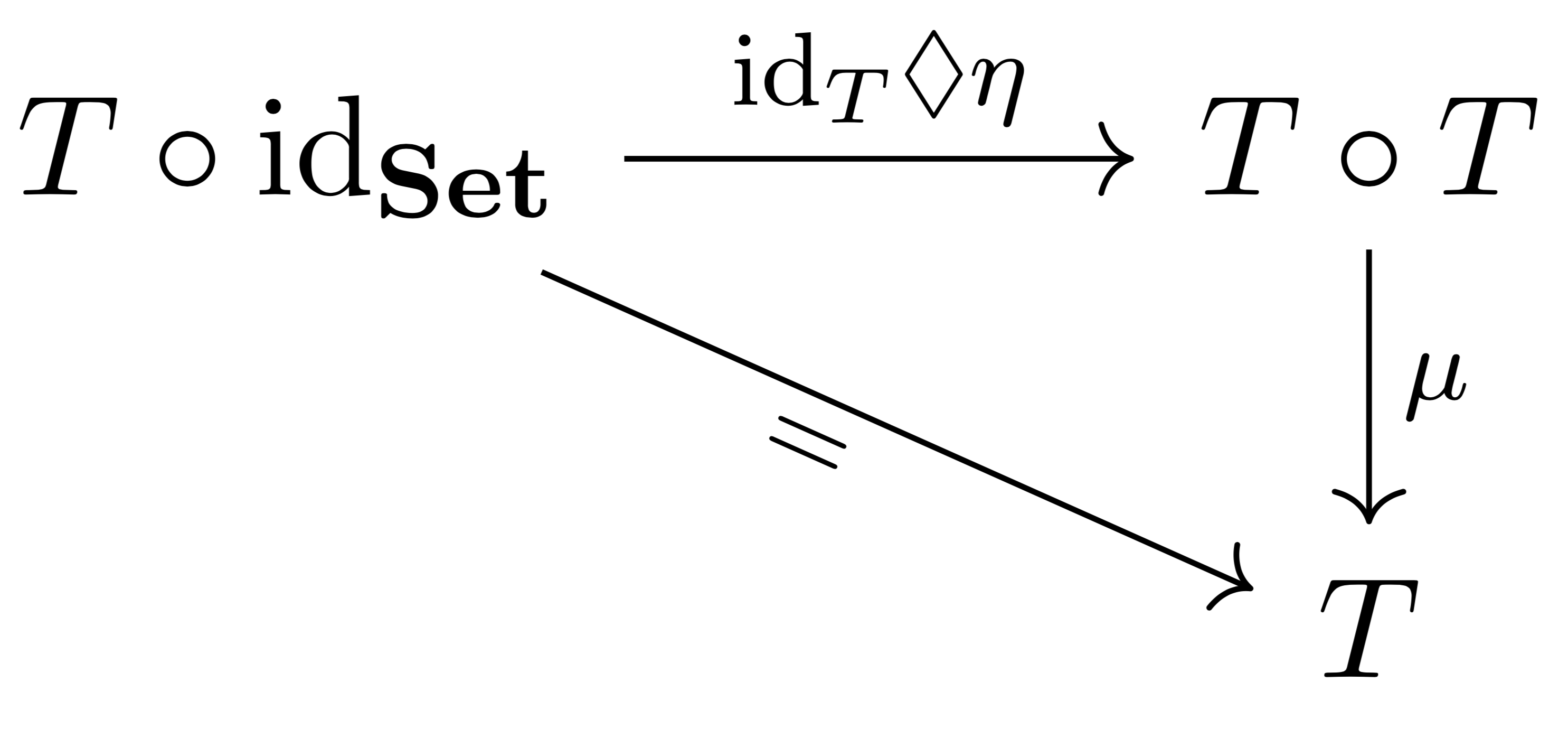
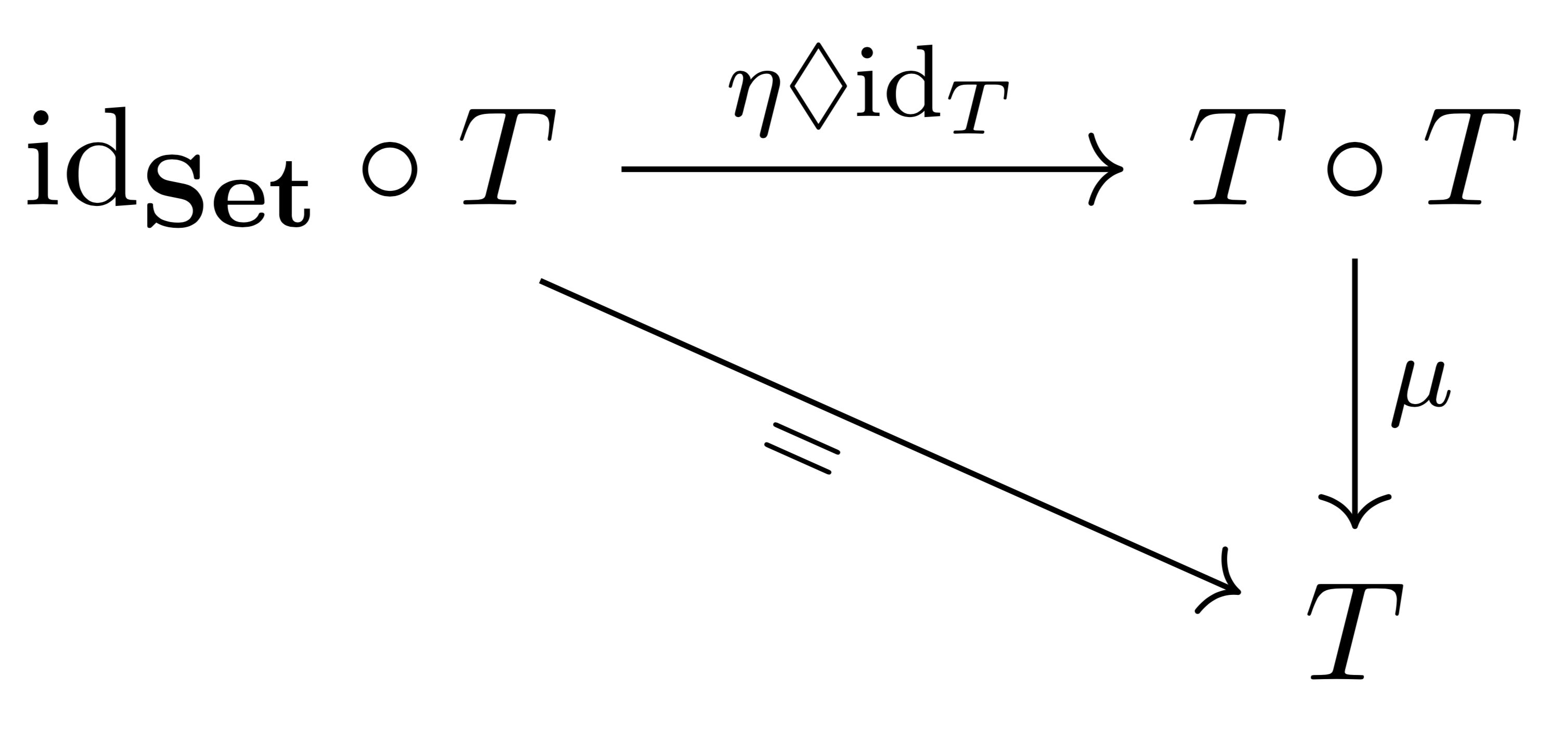
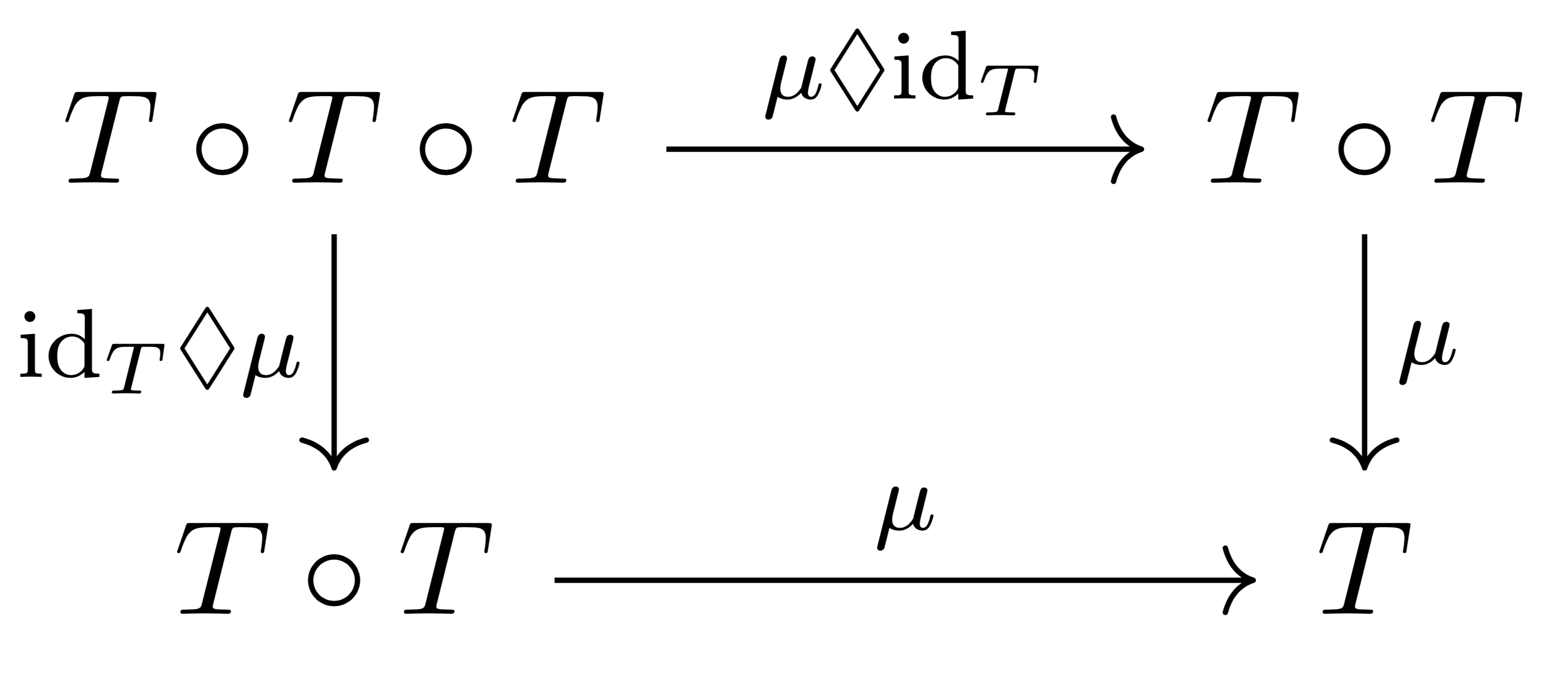
 of a monad
of a monad 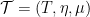 on
on  and morphisms
and morphisms  . Identity is
. Identity is  in
in  in
in  in
in  in
in 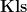 .
.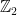 corresponds to the classical case. There are no great surprises here for a reader who has read a basic text in computational complexity together with Chapters 1-3 of this book. The authors round off the chapter by using this new machinery to cast results from
corresponds to the classical case. There are no great surprises here for a reader who has read a basic text in computational complexity together with Chapters 1-3 of this book. The authors round off the chapter by using this new machinery to cast results from  , while Tarski becomes every definable set over
, while Tarski becomes every definable set over 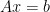 gets amplified by the condition number of the matrix
gets amplified by the condition number of the matrix 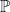 ).
). . The chapter then goes on to show that probabilistic machines over
. The chapter then goes on to show that probabilistic machines over  , whereas this is unknown for the classical setting. The essence of the argument makes use of a special real number (shown, non constructively, to exist), encoding all the different “coin flips” that a probabilistic program makes during its execution, which is then encoded as a machine constant in the simulating machine.
, whereas this is unknown for the classical setting. The essence of the argument makes use of a special real number (shown, non constructively, to exist), encoding all the different “coin flips” that a probabilistic program makes during its execution, which is then encoded as a machine constant in the simulating machine. , parallel polylogarithmic time, for sets that can be decided in time
, parallel polylogarithmic time, for sets that can be decided in time  using a polynomial number of processors, and
using a polynomial number of processors, and 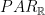 , parallel polynomial time, for sets that can be decided in polynomial time using an exponential number of processors (definitions following a
, parallel polynomial time, for sets that can be decided in polynomial time using an exponential number of processors (definitions following a 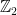 , i.e. the classical model, compared to real machines which take inputs restricted to be drawn from
, i.e. the classical model, compared to real machines which take inputs restricted to be drawn from  can be done by encoding the characteristic function of the set as the digits of some real constant in the program. It is then shown that additive real machines (a restricted form of the machines discussed above, containing no multiplication or division) that additionally contain branching only on equality can solve exactly the same problems in polynomial time as in the classical model. This is unlike the case where branching can be over inequality, where some additional computational power is provided by this model.
can be done by encoding the characteristic function of the set as the digits of some real constant in the program. It is then shown that additive real machines (a restricted form of the machines discussed above, containing no multiplication or division) that additionally contain branching only on equality can solve exactly the same problems in polynomial time as in the classical model. This is unlike the case where branching can be over inequality, where some additional computational power is provided by this model. problems and
problems and  , respectively. In the latter case, I think this essentially says that known results in the classical case carry forward to computation over the reals despite the move away from a finite ring. I am not familiar enough with computational complexity literature to comment on how the former result compares with the classical setting, and I didn’t feel that this point is was very well described in the book.
, respectively. In the latter case, I think this essentially says that known results in the classical case carry forward to computation over the reals despite the move away from a finite ring. I am not familiar enough with computational complexity literature to comment on how the former result compares with the classical setting, and I didn’t feel that this point is was very well described in the book.