Approximate Computing has been a buzzphrase for a while. The idea, generally, is to trade off quality of result / solution, for something else – performance, power consumption, silicon area. This is not a new topic, of course, because in numerical computation people have generally always worked with finite precision number representations. In my early work in 2001, before the phrase “Approximate Computing” was in circulation, I introduced this as “Lossy Synthesis” – the idea that circuit synthesis can be broadened to incorporate the automated control of loss of numerical quality in exchange for reduction in area and increase in performance.
Most approximate computing frameworks focus on domains where numerical error is tolerable. Perhaps we don’t care if our answer is 1% wrong, for example, or perhaps we don’t even care if it’s out by 100%, so long as that happens very infrequently.
However, there is another interesting class of computation. Consider a function producing a Boolean output  , where
, where  . An interesting challenge is to produce another function
. An interesting challenge is to produce another function  with a ternary output
with a ternary output  bearing a close resemblance to
bearing a close resemblance to  . We can make the idea of bearing a close resemblance precise in the following way: if
. We can make the idea of bearing a close resemblance precise in the following way: if  declares a value true (false), then so must . We can think of this as relation between fibres:
declares a value true (false), then so must . We can think of this as relation between fibres:
 and
and  (1)
(1)
We can then think of the function as approximating if the fibre of the ‘don’t know’ element,  , is small in some sense, e.g. if
, is small in some sense, e.g. if 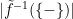 is small.
is small.
In the context of approximate computing, we can pose the following optimisation problem:
 subject to
subject to  and (1),
and (1),
where  represents the cost (energy, area, latency) of implementing a function. One application area for this kind of investigation is in computer graphics. It is often the case that, when rendering a scene, an algorithm first needs to decide which components of the scene will definitely not be visible, and therefore need not be considered further. Should this part of the graphics pipeline make a mistake by deciding a component may be visible when it is actually invisible, little harm is done – more computation is required downstream in the graphics pipelining, costing energy and time, but not a reduced quality rendering. On the other hand, if it makes a mistake by deciding that a component is invisible when it is actually visible, this may cause a significant visual artefact in the rendered scene.
represents the cost (energy, area, latency) of implementing a function. One application area for this kind of investigation is in computer graphics. It is often the case that, when rendering a scene, an algorithm first needs to decide which components of the scene will definitely not be visible, and therefore need not be considered further. Should this part of the graphics pipeline make a mistake by deciding a component may be visible when it is actually invisible, little harm is done – more computation is required downstream in the graphics pipelining, costing energy and time, but not a reduced quality rendering. On the other hand, if it makes a mistake by deciding that a component is invisible when it is actually visible, this may cause a significant visual artefact in the rendered scene.
Last year, I had a bright Masters student, Georgios Chatzianastasiou, who decided to explore this problem in the context of being the Slab Method in computer graphics and being one of a family of approximations  , each produced by using interval arithmetic approximations to computed in floating-point with precision
, each produced by using interval arithmetic approximations to computed in floating-point with precision  . In this way we get a family of approximate computing hardware IP blocks, all of which guarantee that, when given a ray and a bounding box, if the IP reports no intersection between the two, then there is provably no intersection. Yet each family member operates at a different precision, requiring different circuit area, trading off against the rate of `false positives’. Georgios wrote a paper on the implementation, which was accepted by FPL 2018 – he presents it next Wednesday.
. In this way we get a family of approximate computing hardware IP blocks, all of which guarantee that, when given a ray and a bounding box, if the IP reports no intersection between the two, then there is provably no intersection. Yet each family member operates at a different precision, requiring different circuit area, trading off against the rate of `false positives’. Georgios wrote a paper on the implementation, which was accepted by FPL 2018 – he presents it next Wednesday.
If you’re at the FPL conference, please go and say hello to Georgios. If you’re interested in working with me to deepen and broaden the scope of this work, please get in touch!
