Followers of my research will know that I’ve long been interested in rounding errors and how they can be controlled to best achieve efficient hardware designs. Going back 20 years, I published a book on this topic based on my PhD dissertation, where I addressed the question of how to choose the precision / word-length (often called ‘bit width’ in the literature) of fixed point variables in a digital signal processing algorithm, in order to achieve a controlled tradeoff between signal-to-noise ratio and implementation cost.
Fast forward several years, and my wonderful collaborators Fredrik Dahlqvist, Rocco Salvia, Zvonimir Rakamarić and I have a new paper out on this topic, to be presented by Rocco and Fredrik at CAV 2021 next week. In this post, I summarise what’s new here – after all, the topic has been studied extensively since Turing!
I would characterise the key elements of this work as: (i) probabilistic, i.e. we’re interested in showing that computation probably achieves its goal, (ii) floating point (especially of the low custom-precision variety), and (iii) small-scale computation on straight-line code, i.e. we’re interested in deep analysis of small kernels rather than very large code, code with complex control structures, or code operating on very large data structures.
Why would one be interested in showing that something probably works, rather than definitely works? In short because worst-case behaviour is often very far from average case behaviour of numerical algorithms, a point discussed with depth in Higham and Mary’s SIAM paper. Often, ‘probably works’ is good enough, as we’ve seen recently with the huge growth of machine learning techniques predicated on this assumption.
In recent work targeting large-scale computation, Higham and Mary and, independently, Ipsen, have considered models of rounding error that are largely / partially independent of the statistical distribution of the error induced by a specific rounding operation. Fredrik was keen to take a fresh look at the kind of distributions one might see in practice, and in our paper has derived a ‘typical distribution’ that holds under fairly common assumptions.
Rocco and Fredrik then decided that a great way to approximate the probabilistic behaviour of the program is to sandwich whatever distribution is of interest between two other easy to compute distributions, utilising the prior idea of a p-box.
One of the core problems of automated analysis of numerical programs has always been that of ‘dependence’. Imagine adding together two variables each in the range ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=ffffff&fg=000000&s=0&c=20201002)
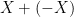
I am really excited by the end result: not only a wonderful blend of ideas from numerical analysis, programming languages, automated reasoning and hardware, but also a practical open-source tool people can use: https://github.com/soarlab/paf. Please give it a try!
Readers interested in learning more about the deeply fascinating topic of numerical properties of floating point would be well advised to read Higham’s outstanding book on the topic. Readers interested in the proofs of the theorems presented in our CAV paper should take a look at the extended version we have on arXiv. Those interested in some of the issues arising (in the worst case setting) when moving beyond straight-line code could consult this paper with Boland. Those interested in the history of this profoundly beautiful topic, especially in its links to linear algebra, would do well to read Wilkinson.
