This is the third post in a sequence relating to the geometry of block number formats as angle preservers. In my previous post, I argued that block number formats remain direction preservers even when their block scales are quantised all the way down to powers of two, as is common in some number representations like the MX concrete formats. The main result there was that exponent-only block scaling perturbs direction by at most about , and that is not that much in high dimensions. So we ended last time with the nice result that very coarse block-scale quantisation is relatively benign.
But that doesn’t mean power-of-two scaling is optimal. If we have a fixed budget of bits for representing block scales, how should we spend them? Specifically, should we spend them on exponent range, or on significand precision?
This post argues that the answer becomes much clearer once a high-precision tensor-wide scale is introduced, which is exactly the kind of two-level scaling used in NVIDIA’s NVFP4 format. In NVFP4, 4-bit E2M1 values are combined with an FP8 E4M3 scale for each 16-value micro-block and a second-level FP32 scale for the tensor.
With such a tensor-wide scale, the block scales are relieved of their duty to try to capture the global magnitude of the tensor. Instead, we can ask a more focused task of them: reconstruct the relative amplitudes of the blocks, so that the global direction of the represented vector is preserved.
Since drafting this post, Bardia Zadeh and I have also written Direction-Preserving Number Representations, which I blogged about separately. That paper studies the related question of what directions can be obtained when each coordinate of a vector is drawn from a finite scalar alphabet. This post is about block scales rather than scalar elements, but the same product-structured geometry reappears one level higher.
I will argue in this post that once we look at the problem that way, precision in the block scales starts to matter much more. This leads to a rough rule of thumb for the relationship between block scale formats and vector lengths.
What a tensor-wide scale changes
Suppose, as per my previous posts, that each block is represented as , where is a chosen mantissa vector and is the ideal real-valued block scale for that mantissa direction.
Now suppose that the final represented tensor has the form
where
is the high-precision tensor-wide scale,
is the low-precision per-block scale, and
denotes direct sum (block concatenation).
Of course, the tensor-wide scale has no effect on direction at all: it multiplies the whole tensor uniformly, so it only changes magnitude. That means the tensor-wide scale can be used to absorb the global length of the vector, leaving the block scales to encode relative block amplitudes.
In other words, once a tensor-wide scale is present, the block scales stop answering the question “how large is this tensor?” and instead answer the question “how do the blocks compare with one another?”
Exact scale-only cosine factor
Let denote the ideal blockwise representation obtained using the real-valued scales , and let denote the represented tensor after block-scale quantisation.
Write
Then the represented block is simply
So scale quantisation does not change any chosen block direction, it only rescales the ideal projected blocks.
Define
so that is the fraction of the ideal projected energy contained in block .
Then, exactly as in the previous post, we have
This says that directional distortion from block-scale quantisation depends only on how uneven the multiplicative scale errors are across blocks.
If all blocks were rescaled by the same factor, direction would be unchanged.
Two jobs for two different kinds of bits
A block-scale format does two things.
First, its exponent bits determine what range of relative block scales can be represented without clipping or underflow.
Second, its significand bits determine how accurately the in-range scales are represented.
So there are really two error sources:
tail loss, from blocks whose scales fall outside range;
in-range uneven rescaling, from finite precision within range.
The interesting question is how these trade off when the total number of scale bits is fixed.
A conservative scale-only view for fixed
Suppose the tensor is divided into blocks.
If we want a format-level guarantee, a natural scale-only question is:
for a given number of blocks , how should a fixed budget of scale bits be split between exponent and significand so as to control the worst-case angular loss caused by scale quantisation?
I am deliberately saying “scale-only” here because this is not a claim about the globally optimal scalar alphabet (a problem Bardia and I cover in our preprint, linked to above), nor about the full problem of choosing the mantissa vectors. It is a conservative model of the additional angular error introduced after the block directions have already been chosen.
To make this concrete, let
be the number of exponent bits,
be the significand precision in bits, and
be the total scale-field width.
Now make one simplifying assumption: the mantissa vectors used in different blocks all have the same norm. Under that assumption, projected block energy is proportional to the square of the ideal block scale. This lets us reason directly in terms of the block scales themselves.
If the exponent field is too narrow, then very small relative block scales may underflow to zero after tensor-wide normalisation. In the worst case, one block survives at unit scale and the remaining blocks sit just below the lower threshold and are lost.
If the smallest representable normalised scale is , then the exponent-side cosine contribution is bounded by
Here denotes the intermediate vector obtained by zeroing the blocks that fall below the representable scale threshold.
If, on the other hand, the surviving blocks remain in range but the scale precision is limited, then the remaining error comes from uneven in-range rescaling. Suppose the multiplicative scale errors for the surviving blocks satisfy
Then the interval argument from the previous post gives
In the common symmetric relative-error model, and , so this becomes
Putting the clipping and in-range effects together gives the conservative scale-only bound
In the symmetric relative-error model, this simplifies to
This is the key scale-only design inequality.
What this says about exponent bits
The first striking feature is that exponent bits only need to control the low-energy tail.
To make clipping negligible, it is enough to ensure that
Now the dynamic range of a floating-point-like scale grows extremely quickly with exponent width. A format-dependent way to write this is
where is a positive constant depending on details such as exponent bias, reserved encodings, and whether subnormals are supported.
Substituting into the clipping condition gives
Solving this roughly gives
The important point is the growth law. The number of exponent bits needed to control relative-tail clipping grows only like .
That is a very slow growth law: once is fixed, only a small number of exponent bits is needed before clipping becomes a second-order issue for direction.
What this says about significand bits
Once clipping is under control, the remaining scale error is dominated by in-range relative precision. That is the role of the significand.
In the symmetric relative-error model, the scale-only cosine contribution is
Equivalently, the angular contribution is at most
If a -bit significand gives a relative scale error of the form
where depends on the precise rounding convention, then asking the scale field alone to contribute at most an angle gives the rough condition
Equivalently,
So once the exponent field is “good enough”, every additional scale bit is more profitably spent on significand precision than on more dynamic range. This is the central conclusion of the scale-only model.
A simple rule of thumb
The previous discussion suggests the following design rule.
Use just enough exponent bits to make clipping of important blocks negligible. Spend the rest on significand precision.
For a tensor with blocks and a scale field of width , a rough rule of thumb is
Here is a small format-dependent additive correction – in a real format, it depends on details such as exponent bias, special encodings, and subnormal support. This is not meant as a precise optimum, only as a rough scale-only guide. But it makes the main point quite clearly:
exponent bits become sufficient very quickly; significand bits keep helping.
What this means for modern designs
This way of looking at the problem helps explain why a format that combines
a high-precision tensor-wide scale, and
a more precise block-scale format
looks like a very sensible design.
The tensor-wide scale deals with global magnitude. That leaves the block scales free to focus on preserving the relative block amplitudes that determine global direction.
This is exactly the tradeoff that makes NVFP4 interesting. Compared with exponent-only scaling, E4M3 block scales spend some representational power on non-power-of-two precision. The second-level FP32 tensor scale then compensates for the reduced range of the more precise E4M3 block-scale format.
There is also a useful connection with Bardia’s preprint. That paper studies the scalar alphabet inside a block, and finds that for 4-bit alphabets at the NVFP4 micro-block dimension , E2M1 is close to an independently optimized direction-preserving alphabet. This post studies a complementary question one level higher: once those micro-blocks have scales, how should the scale alphabet itself spend its bits?
So the two messages reinforce one another:
inside a micro-block, E2M1 is a surprisingly good product-structured scalar alphabet for direction preservation;
across micro-blocks, a tensor-wide scale makes the relative block-scale problem more important, so non-power-of-two block-scale precision becomes valuable.
From the perspective of directional reconstruction, that seems like a very good bargain.
Conclusion
The previous post showed that even exponent-only block scaling preserves direction surprisingly well.
This post goes a step further. Once a tensor-wide high-precision scale is available, the main question is no longer whether coarse block scaling is robust enough. Instead, we should ask whether the block scales are making the best possible use of their bits.
From the point of view of reconstructing global direction,
exponent bits protect against clipping of low-energy tail blocks;
significand bits improve the relative amplitudes of all the important in-range blocks.
Since exponent range grows very quickly with exponent width, only a modest number of exponent bits is needed before clipping becomes a secondary issue. After that, precision matters more.
This is a scale-only argument. It assumes the block directions have already been chosen, and studies the additional directional error caused by quantising the relative block amplitudes.
Proof sketch of the conservative scale-only bound
Readers not interested in the algebra can safely skip this section.
Assume equal mantissa norms across blocks, so that ideal projected block energy is proportional to the square of the ideal block scale.
Let be the ideal blockwise projected vector after tensor-wide normalisation. We model low-precision block scales in two stages.
First, let be obtained from by zeroing every block whose normalised scale falls below the smallest representable positive scale . In the worst case, one block survives at scale and the remaining blocks sit just below and are lost. The lost projected-energy fraction is then
so
Second, form the final represented vector by applying in-range rounding to the surviving block scales. If the surviving-block multiplicative errors satisfy
then the interval bound from the previous post gives
In the symmetric relative-error model, and , so this becomes
Now write , where is supported only on the clipped blocks. Since is supported only on the surviving blocks, we have , and hence
In the UK, the House of Commons Select Committee on Science, Innovation and Technology is currently holding an inquiry into “Low-Energy Computing”. The remit of the inquiry can be found below.
AI model sizes and data volumes are growing significantly. At the same time, areas like quantum computing and protein synthesis also require increasing amounts of computational power.
The Science, Innovation and Technology committee is examining how realistic a possibility this is, when breakthroughs might be expected to take place and what the government is doing to support research and innovation activity in this area.
This inquiry has been launched following pitches made to the committee as part of its Under the Microscope initiative.
I am reproducing my submission to this inquiry below, in case it is of value to others. The text can also be found – alongside all other submissions made – at the official parliamentary website.
In a couple of recent posts [1,2], I have been trying to reason through the geometric properties of block number formats. The basic idea is that when a group of numbers shares a scale factor, the small low-precision numbers inside the block are no longer meaningfully trying to approximate scalar magnitudes, as the scale has already taken care of much of the magnitude information. What remains is, to a significant extent, a question of direction.
This post is about a new preprint I have recently put out with Bardia Zadeh, “Direction-Preserving Number Representations”. The question we ask is “If a block scale has already taken care of magnitude, what should the scalar values inside the block look like if our aim is to preserve direction?”
That is not the usual question in computer arithmetic, and I can’t really find a historical precedent for this question in the usual places I would look (please let me know if you know others who have looked at this question from an arithmetic perspective!) We usually ask about absolute error, relative error, dynamic range, rounding behaviour, underflow, overflow, and so on. But in many modern machine learning settings, it is also natural to ask a more geometric question: how well do the values available inside a block cover the possible directions of a vector?
On the research methodology side, there is another aspect of this paper that is new for me personally. This is the first paper I have written where AI tools (namely GPT-5.4, GPT-5.5 and Aristotle) made a substantive contribution to the development of proof ideas, as well as to the Lean formalisation, which I am delighted we have open sourced. The AI tools definitely did not replace mathematical judgement or lead to a push button approach: the process still required many manual reformulations, checking, rewriting, and false starts. But it was a new and positive experience for me. In particular, the combination of exploratory AI assistance and Lean’s rock solid proof checking made for a very different style of research interaction from the one I am used to.
I will come back to Lean and AI below. First, let me describe the mathematical object we studied.
From scalar alphabets to directions
Suppose we have a finite scalar alphabet . For example, might be the set of real values represented by a 4-bit floating-point format, or by a 4-bit integer format.
If a block has dimension , then the unscaled vectors we can represent are the product set
But if the block also has an independent positive scale factor, then multiplying the whole vector by a positive scalar should not really change the information encoded by the low-precision elements. The scale can absorb that. What matters is the direction.
So the relevant object becomes
This is a finite set of points on the unit sphere. But these points can’t be placed arbitrarily on the sphere. The set has product structure, because each coordinate is chosen independently from the scalar alphabet.
The natural worst-case measure is the covering radius
This asks: given any true direction , how close is the nearest direction obtainable from the alphabet ? Smaller is better.
This lens changes the problem of how to select the alphabet. Instead of asking “which scalar values approximate real numbers well?”, we ask: which scalar values, when used coordinatewise, cover directions well?
You can see the two-dimensional directionality coverage of the floating-point alphabet with two exponent bits, one mantissa bit and one sign bit (E2M1), illustrated below. Each intersection of grid lines corresponds to a 2-vector with elements drawn from this alphabet. We may then find where the line between the origin and that intersection meets a circle (marked as red points). Note the non-uniform spacing around the circle: some regions are better covered than others.
Directional Coverage of E2M1
If you want to play with designing your own two-dimensional alphabet in a graphical user interface, you can get more intuition into this problem using this widget Bardia created: https://bardia01.github.io/directional_coverage_explorer/.
A Lean Interlude
As I mentioned above, I’m super pleased that we’ve open-sourced formalisations of all our theorems and definitions in Lean. The formalisation is organised so that the top-level declarations correspond closely to the paper.
Here Aq q is the class of scalar alphabets with elements. The definition P n A is the finite spherical code obtained by normalising nonzero elements of . The quantity F n A is the product-code covering objective . The definition rhoSph n m is the optimal covering radius of an unconstrained spherical code with points.
I’m giving these Lean definitions now so we can roughly follow along in Lean as we go for the rest of this blog post.
Product Codes versus Spherical Codes
It seems natural, almost obvious, that a product code should give worse directional coverage than a vector code chosen specifically to optimise directional coverage. Of course, the latter may not be practical, as the decoding process may be significant, but it still forms a useful baseline comparison point. Our first theoretical contribution is to quantify the gap between these two code classes.
Notice that the product structure induces a very severe geometric constraint. Even if has values, so that has up to raw vectors, those vectors are not arbitrary. They arise from independent coordinate choices from the same scalar alphabet. Meanwhile, a spherical code with points is free to place those points anywhere on the sphere.
The harmonic witness
A central construction in the paper is a direction that is hard for product codes to cover. Let
be the th harmonic number, and define the unit vector
The entries of this vector decay slowly, making the vector awkward for a finite scalar alphabet. The resulting theorem gives a lower bound on the worst-case angular error. If is the smaller of the number of positive and negative nonzero values in , then
The Lean statement is compact enough to include directly:
The notation mSign A is the Lean name for , the smaller nonzero sign count. The theorem is written as a lower bound on F n A, just as in the paper.
Since grows like , this bound tends towards for any fixed alphabet. In plain language: in sufficiently high dimension, every fixed scalar alphabet has some direction that it represents very badly.
This is a worst-case theorem. We’re not claiming that real neural network tensors look like the harmonic witness. What the theorem tells us is that if the metric is worst-case angular coverage of the entire sphere, product-structured scalar alphabets have an inherent limitation.
So What about Spherical Codes?
A product code built from a -element alphabet has at most raw codewords before normalisation. The fair unconstrained comparison is therefore a spherical code with points.
The paper proves that, for any fixed , sufficiently high-dimensional spherical codes beat every -element product code in worst-case angular covering radius.
Read from right to left, this says: take any scalar alphabet with elements. In all sufficiently large dimensions , the best unconstrained spherical code with points has strictly smaller covering radius than the product-code direction set induced by .
What about Floating and Fixed Point?
The next question we answer is more practical. Within the product-code world, are the usual scalar alphabets the best ones?
The paper studies standard floating-point, fixed-point, and two’s complement alphabets. The answer is that these conventional choices are asymptotically suboptimal for the worst-case directional metric.
Because the worst-case angle for any product code tends towards in high dimension (see above), it is more informative when comparing product codes to look at a normalised quantity such as:
Very roughly, this measures how slowly the worst-case angle approaches . Larger is better.
The Lean statement packages the relevant comparison as a liminf/limsup chain:
This is a theorem about -bit alphabets. The quantity normBestAlpha n (2 ^ b) is the best normalised performance obtainable by an arbitrary -element scalar alphabet. The quantity normBestFpCos n b is the corresponding floating-point quantity, optimised over valid splits of exponent and mantissa bits. The constants arbConst b and fpConst b are the two asymptotic constants being compared.
The middle inequality fpConst b < arbConst b is the key point. For , arbitrary scalar alphabets can do strictly better than the floating-point family in this asymptotic directional metric.
For four bits, the paper obtains a concrete constant-factor separation of at least
So if the design objective is “choose scalar levels whose product code covers directions well”, there are better alphabets than the standard ones, at least in this worst-case asymptotic sense.
AI and Lean
It feels worth saying a little more about the process followed to reach the proofs of these theorems. This paper is the first time I have had a genuinely substantive AI contribution to the development of proof ideas, not just text polishing and review. AI was useful both in the Lean formalisation and in exploring how some of the mathematical arguments might be structured.
The AI tools we used needed lots of iteration, but the workflow was unexpectedly productive. GPT-5.4 and 5.5 and Aristotle from Harmonic could suggest possible routes, propose intermediate lemmas, help with translation between informal mathematics and Lean statements, and generate candidate proof fragments.
This combination was new for me. I am used to mathematical collaboration involving conversations with people, paper sketches, whiteboards, and eventually LaTeX. Here there was another kind of interaction: a fast, imperfect, but useful assistant for exploring the proof space, coupled with Lean as a formal system that refused to accept anything vague.
Mathematical judgement still matters, in what we wanted to prove as well as what counts as an informative proof. But I came away from the experience more positive about the role these tools can play in research, especially when paired with formal verification rather than used as a substitute for it.
The Experimental Side: Exploring 4-bit Alphabets
The theory says that better scalar alphabets should exist. The experiments in the paper ask what they look like. For four-bit alphabets, we impose sign symmetry and include zero. Since multiplying all scalar levels by a common positive factor does not change the represented directions, we normalise the smallest positive value to one.
For block dimension (as used in NVIDIA NVFP4), the optimised positive levels found in the paper are approximately
The optimised alphabet is best across the tested dimensions. But what I find most interesting is how close E2M1 is to the optimum, especially compared with integer/fixed-point and pure powers-of-two formats.
E2M1 is the four-bit format used in NVFP4. The results suggest a geometric explanation for why it works well in block-scaled machine learning settings. The key point is that, for this bit-width and block size, the E2M1 levels lie surprisingly close to the levels obtained by directly optimising the product-code directional covering problem.
Conclusion
The main message is that the geometric lens provides value when considering how to design low-precision number formats for machine learning. Once a block scale is present, the scalar values inside the block are not merely approximating real numbers independently. Together, they are choosing a direction. The scalar alphabet therefore determines a product-structured spherical code.
There are three consequences I find useful.
First, product structure has unavoidable limitations. A coordinatewise scalar alphabet cannot cover directions as well as an unconstrained spherical code with the same number of raw codewords.
Second, standard scalar formats are not forced by the geometry. Floating-point, fixed-point, and two’s complement are natural formats for many reasons, but the directional covering objective points to other possibilities.
Third, E2M1 comes out looking very good. The optimised alphabet is better in the sampled worst-case metric, but E2M1 is close enough that its empirical success in block-scaled low-precision settings has a clean geometric explanation.
The Lean formalisation matters because it pins down the definitions, checks the asymptotic comparisons, verifies the separation from standard formats, and formalises the scale-search theorem used in the experiments.
The AI aspect matters to me for a different reason. It changed the way this paper was developed. The experience was not one of handing mathematics over to a machine, but of using AI as part of a proof-development workflow. For me, that was new, and it was positive.
So perhaps a promising design question for future low-precision formats should be phrased less like the traditional “Which scalar values approximate real numbers best?” and more like “Which scalar values, when used coordinatewise inside a block, represent directions best?” That seems like a useful question in the world of block-scaled arithmetic.
In the UK, the Parliamentary Select Committee on Education is currently holding an inquiry into “The use of Artificial Intelligence and EdTech in Education”. I am reproducing my submission to this inquiry below, in case it is of value to others. The text can also be found – alongside all other submissions made – at the official parliamentary website.
In my previous post, I argued that block number formats can be understood geometrically as direction preservers. That argument relied on an idealization: once a block direction had been chosen, its scale could be set optimally as an arbitrary real number.
Real hardware formats do not usually work that way. In many practical schemes, block scales are quantized very coarsely, sometimes all the way down to powers of two. In particular, in the MX specification, all the concrete compliant formats use E8M0 scaling.
So does the directional picture I painted in my last post survive this brutal scaling? Here I will argue, in the first of what I hope will be a short sequence of follow-up blog posts, that it does.
From ideal block scales to quantized block scales
Recall the setup from the earlier post. A vector is partitioned into blocks, , and each block is approximated as , where is a low-precision mantissa vector and is a scalar block scale.
In the earlier post, I assumed that was an arbitrary real value, chosen optimally in the least-squares sense. That gave the ideal blockwise representation .
Now let us keep the same mantissa vectors , but suppose that the scale factors themselves must be quantized. Write the implemented scale as , so that the represented block becomes .
It is convenient to define the multiplicative scale error . Then .
Note that, of course, quantizing the block scale does not change the chosen direction of a block at all; it only changes its length. So the only directional distortion comes from the relative rescaling of different blocks.
An exact cosine formula
Let , so that is the fraction of the ideal projected vector’s energy contained in block .
Then it can be shown that (the proof is included at the end of this post).
So the effect of scale quantization on direction depends only on how uneven the factors are across blocks. If all blocks were rescaled by the same factor, direction would be unchanged.
Exponent-only power-of-two scaling
Now consider the coarsest plausible case: each block scale is rounded to the nearest power of two. Then each multiplicative error satisfies .
So, from our exact cosine formula, we are interested in how small can be, when all the lie in the interval .
A simple inequality shows that the answer depends only on the two extreme values of the interval. If all the block rescaling factors lie in , then
(proof at the end of this blog post).
In the power-of-two case we have , , so , and therefore
.
Equivalently, .
So even if every block scale is rounded to the nearest power of two, the resulting vector remains within about of the ideally scaled one.
That is the main result of this post.
One striking feature of the bound is that it does not depend on the dimension of the vector. The reason is that the worst case is already attained by a two-group energy split: some blocks rounded up, others rounded down. Once those two groups exist, adding more blocks or more dimensions does not make the bound worse, as is apparent from the proof below.
20 degrees is less than it sounds
Our everyday intuition may tell us that this angle is not huge, but it’s not that small either. In a sense, that’s true. But angles behave very differently in high-dimensional spaces. In high dimension, most random vectors are almost orthogonal to one another: their angle is close to , so a guarantee that an approximation remains within of the original vector is much stronger than it would sound in two or three dimensions.
Beyond power-of-two
We’ve analysed power-of-two scaling here for two reasons: because it’s in a sense the crudest possible floating-point rounding, and because it’s commonly used in real hardware designs.
That does not mean it’s optimal. But it does raise two further questions. Firstly, we’ve assumed here that the exponent range is sufficiently wide – what if it’s not? Secondly – and relatedly – how much better can this angular bound get by spending some of the scale bits on greater precision?
My view is that the answer becomes clearer once a tensor-wide high-precision scale is introduced, something NVIDIA has recently done. In that setting, the block scales get relieved of their additional duty to capture global magnitude. This will be the subject of the next post on the topic!
Proofs
Readers not interested in the algebra can safely skip this section.
Cosine formula
Recall that for each block .
Then, because the blocks occupy disjoint coordinates, .
Also, , and .
Therefore .
Now, as per the main blog post, define .
Writing , so that , the numerator becomes and the denominator becomes , giving
.
20 degree bound
Assume that all the multiplicative error factors lie in an interval with .
Let .
Then the cosine is just . Since each , we have
.
Expanding this gives
.
Multiplying by and summing over gives
.
Therefore .
Now the weighted mean also lies in the interval , so it remains to minimize
over .
Differentiating shows that the minimum occurs at , the harmonic mean of and .
I’ve recently returned from the SIAM PP 2026 conference and as always, conferences help provide time for research reflection. One thing I’ve been reflecting on during my journey back is the various explanations people give for why the machine learning world is so keen on block number formats (MX, NVFP, etc.) – see my earlier blog post on MX if you need a primer. Many hardware engineers tend to answer that they lead to efficient storage, or efficient arithmetic, or improved data transfer bandwidth, which are all true. But I think there’s another complementary answer that’s less well discussed (if indeed it is discussed at all). I hope this blog post might help stimulate some discussion of this complementary take.
On the numerical side, at first glance it might seem surprising that despite these formats representing numbers with very limited precision, large neural networks often tolerate them remarkably well, with little loss in accuracy. In my experience, most explanations focus on dynamic range, quantization noise, the inherent noise robustness of neural networks, or calibration techniques. But I suspect there is also a simple geometric way to think about what these formats are doing: Block number formats help preserve vector direction. And for many machine learning computations, preserving direction matters far more than preserving exact numerical values.
Block formats inherently represent direction and magnitude
Consider a vector whose coordinates are partitioned into blocks .
In a block format, each block is represented using a shared scale and low-precision mantissas. For ease of discussion, we’ll consider the simplest case here, where scales are allowed to be arbitrary real-valued. In general, they may be much more restricted, e.g. powers of two.
Each block is approximated as
where
is a vector of low-precision mantissas, and
is a scalar shared scaling factor.
In other words, each block can be thought of as a direction (encoded by the mantissas) multiplied by a magnitude (the shared scale). Strictly speaking, the mantissa vectors need not be normalized, and in many formats their entries may have quite different magnitudes (for example in integer mantissa formats such as MXINT). However this does not change the geometry. The representation is invariant to rescaling of : multiplying by any constant simply rescales by the inverse factor. What matters for the approximation is therefore only the direction of , i.e. the one-dimensional subspace it spans.
Often we don’t think of it like this, but broadly speaking this is what has happened: block scaling allows us to decouple magnitude and direction representation. This resembles the familiar decomposition of a vector into its magnitude and direction, but applied locally within blocks.
If the mantissa vector points roughly in the same direction as the original block , then scaling it appropriately produces a good approximation of that block.
OK, but does preserving directions block by block actually preserve the direction of the whole vector? It turns out that the answer is yes.
Direction Preservation
Let us make the reasonable assumption that the scale of each block is not chosen arbitrarily, but rather is the best possible scale for that block in the least squares sense, for whatever mantissa vector we choose, i.e. . Then is the orthogonal projection of onto the line spanned by .
So to what extent do the approximate and the original block vector point in the same direction? We can measure the block cosine similarities of the blocks as: .
Equally, we can measure the the cosine similarity of the full vectors (the concatenation of the original blocks versus the concatenation of the approximated blocks): .
My aim here is to explain why small error in direction at block level leads to small error at vector level.
First, let’s define , which we can think of as the fraction of the vector’s energy contained in block ; these add to 1 over the whole vector. Now we can state the result:
Theorem (Block Cosines)
Under the blockwise least-squares scaling, .
For proof, see end of post.
In simple terms, this theorem states that the cosine similarity of the whole vector is the energy-weighted RMS of the block cosine similarities.
What are the implications?
The weights represent how much of the vector’s energy lies in each block. Blocks that contain very little energy contribute very little to the final direction. The important consequence is that direction errors do not accumulate catastrophically across blocks. Instead, the overall directional error simply depends on a weighted average of the block direction errors. In other words, if block number formats preserve the directions of individual blocks, they automatically preserve the direction of the entire vector.
Many core operations in machine learning depend heavily on vector direction. Notably, during training, stochastic gradient descent updates are already in the form of magnitude (learning rate) + direction. We already have a knob controlling magnitude (the learning rate); what matters is that the direction is preserved. In attention mechanisms and embedding, directional similarity measures are very important. Even for the humble dot product, the workhorse of inference, preservation of direction means that small perturbations in input give rise to only small perturbations in output, so the dot product behaves robustly.
Conclusion
Block floating-point and similar formats like block mini-float, MX, NVFP, are usually explained in terms of dynamic range and quantization noise. But geometrically, I like the perspective that they do something simpler: they approximate each block of a vector as direction × magnitude.
And as long as the block directions are preserved reasonably well, the direction of the whole vector is preserved too.
I think this is a useful intuition as to why very low-precision formats can work so well in modern machine learning systems. Block number formats are, in a very real sense, direction preservers. From this perspective, such low-precision block formats succeed not because they represent individual numbers accurately, but because they preserve the geometry of vectors.
Lots of extensions of this kind of analysis are of course possible. To name just a few:
We’ve focused on vectors, but tensor-level scaling may have interesting interplay with batching during training, for example
We made the simplifying assumption that scaling factors were real valued, but these can be restricted, most significantly to powers of two, and the analysis would need to be modified to incorporate that change.
We’ve not discussed mantissas at all, lots more of interest could be said here.
Potentially this approach could help provide some guidance to the empirical sizing of blocks in a block representation.
If anyone would like to work with me on this topic, do let me know your ideas.
Proof of the theorem
Readers not interested in the algebra can safely skip this section.
For each block , the approximation with chosen by least squares is the orthogonal projection of onto the line spanned by .
So we can write where is orthogonal to .
Taking the inner product with gives .
Now sum over blocks. Because the blocks correspond to disjoint coordinates,
This month I took a trip to California for the FPGA 2026 conference, together with my two new PhD students Ben Zhang and Bardia Zadeh, which I combined with a number of visits in the San Francisco Bay Area in the days preceding the conference. This post provides a brief summary of my visit.
First up on our travels was dinner with Rocco Salvia. Rocco was my Research Assistant – we worked together some years ago on automating the analysis of average-case numerical behaviour of reduced-precision floating-point computation. He is now working for Zoox, the robotaxi company owned by Amazon where his first-rate engineering skills are being put to good use!
The following day we went to visit Max Willsey at UC Berkeley and his PhD student Russel Arbore. Max and I (together with others) organised a Dagstuhl workshop on e-graphs recently, and we went to pick up the research conversations we left behind a month ago in Germany and spend some good quality whiteboard time together. Russel and Max are working on some really exciting problems in program analysis.
That afternoon, we had the chance to catch up with my old friend and colleague Satnam Singh, now working for the startup harmonic.fun. Harmonic is a really exciting company, combining modern AI tools with Lean-based formal theorem proving. Expect great things here.
George, Satnam, Bardia and Ben, enjoying coffee near the Harmonic office.
The following morning, we went to visit AMD, with whom I have longstanding collaborations. Amongst others, we met my two former PhD students Sam Bayliss and Erwei Wang there, and discussed our ongoing work on e-graphs and on efficient machine learning, as well as finding out the latest work in Sam’s team at AMD including their release of Triton-XDNA.
Rajarshi, Ben, Bardia, George and Atefeh at NVIDIA
It has long been a tradition that Peter Cheung, when in the Bay Area, organises a get-together of alumni of the Circuits and Systems Group (formerly Information Engineering group, when Bob Spence was Head of Group). This time was no exception – we met up with many of our department’s former students, and some came to a great dinner too. It’s always a delight to hear about the activity of our alumni, spread across the tech companies in the Bay Area.
CAS group Bay Area alumni dinner
After a flying visit to my former PhD student’s family, we then made it down to Monterey for FPGA 2026. Regular readers of this blog will know that I’ve been attending FPGA for more than 20 years, have been Program Chair, General Chair, Finance Chair and am now Steering Committee member of the conference. So it always feels a little like “coming home”. I also love Monterey – despite the touristy bits – and am a fan of Steinbeck‘s writing in which he immortalised Monterey with some of the best opening lines ever (of Cannery Row): “Cannery Row in Monterey in California is a poem, a stink, a grating noise, a quality of light, a habit, a nostalgia, a dream.”
This year, the general chair of FPGA 2026 was Jing Li, and the great programme was put together by Grace Zgheib.
My favourite paper at FPGA this year also won the best paper prize. Duc Hoang and colleagues identified that Kolmogorov-Arnold Networks are a natural fit to the LUT-based neural networks my group pioneered e.g. [1,2]. They form a really interesting design point, overcoming the exponential scaling of area with the product of precision and neuron fanin present in both my SOTA work with Marta Andronic and earlier work like Xilinx LogicNets, to produce a design that scales exponentially only in the precision. I very much enjoyed reading this paper and seeing it presented, and I think it opens up new areas of future work in this area.
Duc Hoang and his coauthor Aarush Gupta, receiving the best paper award from Grace and Jing
I also particularly enjoyed the work of Shun Katsumi, Emmet Murphy and Lana Josipović (ETH Zurich) on eager execution in elastic circuits. I previously collaborated with Lana on elastic circuits, and it’s great to see the latest work in this area and the use of formal verification tools to prove correctness of performance enhancements. I had a very nice discussion with Lana about possible ways to take this work further.
Rouzbeh Pirayadi, Ayatallah Elakhras, Mirjana Stojilović and Paolo Ienne (EPFL) had a really interesting paper on avoiding the overhead of load-store queues in dynamic high-level synthesis. (This paper was also the runner-up best paper).
From my own institution, Oliver Cosgrove, Ally Donaldson and John Wickerson had a great paper on fuzzing FPGA place and route tools, which has led a vendor to fix a bug they uncovered through their tool.
There were many other good papers, but just to mention a couple that I found particularly aligned to my own interests: EdgeSort on the design of line-rate streaming sorters and HACE on extracting CDFGs from RTL were both really interesting to hear presented.
It was great to be reunited with so many international colleagues and to provide my new students Bardia and Ben with the chance to begin their journey of integration into this welcoming community.
Me, John, Bardia, Oliver and Ben after the end of the final conference session
I’ve always struggled with the concept of “doing your best”, especially with regards to avoiding harm. This morning from my sick bed I’ve been playing around with how I could think about formalising this question (I always find formalisation helps understanding). I have not got very far with the formalisation itself, but here are some brief notes that I think could be picked up and developed later for formalisation. Perhaps others have already done so, and if so I would be grateful for pointers to summary literature in this space.
The context in which this arises, I think, is what does it mean to be responsible for something, or even to blame? We might try to answer this by appeal to social norms: what the “reasonable person” would have done. But in truth I’m not a big fan of social norms: they may be politically or socially biased, I’m never confident that they are not arbitrary, and they are often opaque to those who think differently.
So rather than starting from norms, in common with many neurodivergents, I want to think from first principles. How should we define our own responsibilities when we act with incomplete information? And what does it mean to be “trying one’s best” in that situation? And how do we not get completely overwhelmed in the process?
Responsibility and Causality
One natural starting point is causal responsibility. If I take action A and outcome B occurs, we ask: would B have been different if I had acted otherwise? Causal models could potentially make this precise through counterfactuals. This captures the basic sense of control: how pivotal was my action?
But responsibility isn’t just about causality. It is also about what I knew (or should have known) when I acted.
Mens Rea in the Information Age
The legal tradition of mens rea, the “guilty mind”, is helpful here. It recognises degrees of responsibility, such as:
Intention: I aimed at the outcome.
Knowledge: I knew the outcome was very likely.
Recklessness: I recognised a real risk but went ahead regardless.
Negligence: I failed to take reasonable steps that would have revealed the risk.
It’s the final one of these, negligence, that causes me the most difficulty on an emotional level. A generation ago, a “reasonable step” might be to ask a professional. But in the age of abundant online information, the challenge is defining what “reasonable steps” now are. No one can read everything, and I personally find it very hard to draw the line.
If we had knowledge of how the information we gain increases with the time we spend collecting that information, we would be in an informed place. We could decide, based on the limited time we have, how long we wish to explore any given problem.
From Omniscient Optimisation to Procedural Reasonableness
However, we must accept that there are at least two levels of epistemic uncertainty here. We don’t know everything there is to know, but nor do we even know how the amount of useful information we collect will vary based on the amount of time we put in. Maybe just one more Google search or just one more interaction with ChatGPT will provide the answer to our problem.
In response, I think we must shift the benchmark. Trying one’s best does not mean picking the action that hindsight reveals as correct. It means following a reasonable procedure given bounded time and attention.
So what would a reasonable procedure look like? I would suggest that we start with the most salient, socially-accepted, and low-cost information sources. We then keep going with our investigation until further investigation is unlikely to change the decision in proportion to its cost.
In principle, we may want to continue searching until the expected value of more information is less than its cost. But of course, in practice we cannot compute this expectation.
A workable heuristic appears then to be to allocate an initial time budget for exploration, and if by the end the information picture has stabilised (no new surprises, consistent signals), then stop and decide.
I suspect there is a good Bayesian interpretation of this heuristic.
The Value of Social Norms
What then of social norms? What counts as an obvious source, an expert, or standard practice, is socially determined. Even if I am suspicious of social norms, I have to admit that they carry indirect value: they embody social learning from others’ past mistakes. Especially in contexts where catastrophic harms have occurred such as in medicine and engineering, norms, heuristics and rules of thumb represent distilled experience.
So while norms need (should?) not be obeyed blindly, they deserve to be treated as informative priors: they tell us about where risks may lie and which avenues to prioritise for exploration.
Trying One’s Best: A Practical Recipe
Pulling these threads together, perhaps “trying one’s best” under uncertainty means:
Start with a first-principles orientation: aim for causal clarity and avoid blind conformity.
Consult obvious sources of information and relevant social norms as informative signals.
Allocate an initial finite time for self-investigation.
Stop when information appears stable. If significant new evidence arises during investigation, continue. The significance threshold should vary depending on the potential impact.
Document your reasoning if you depart from norms.
Responsibility is not about hindsight-optimal outcomes. It is about following a bounded, transparent, and risk-sensitive procedure. Social norms play a role not as absolute dictates, but as evidence of collective learning obtained in the context of a particular social environment. Above all, “trying one’s best” means replacing the impossible ideal of omniscience with procedural reasonableness.
While this approach still seems very vague, it has at least helped me to put decision making in some perspective.
Acknowledgements
The idea for this post came as a result of discussions with CM over the last two years. The fleshing out of the structure of the post and argument were over a series of conversations with ChatGPT 5 on 26th October 2025. The text was largely written by me.
This blog post sets up and analyses a simple mathematical model of Marx’s controversial “Law of the Tendency of the Rate of Profit to Fall” (CapitalIII §13-15). We will work under a simple normalisation of value that directly corresponds to the assumption of a fixed labour pool combined with the labour theory of value (LTV). I will make no remarks on the validity of LTV in this post, but all results are predicated on this assumption. We will also work in the simplest possible world of two firms, each generating baskets containing both means of production and consumer goods, and in which labour productivity equally improves productivity in the production of both types of goods. I will provide the mathematical derivations in sufficient detail that a sceptical reader can reproduce them quite easily with pen and paper.
The key interesting results I am able to derive here are:
If constant capital grows without bound, then the rate of profit falls, independently of any assumption on the rate of surplus value (a.k.a. the rate of exploitation).
There is a critical value of productivity (which we derive), above which innovation across firms raises the rate of profit of both firms, and below which the rate of profit is reduced.
There are investments that could be made by a single firm to raise its own productivity high enough to improve its own rate of profit when the competing firm does not change its production process. (We locate this threshold, ). However, none of these investments would reduce the rate of profit of when rolled out across both firms (i.e. ). There is therefore no “prisoner’s dilemma” of rates of profit causing capital investment to ratchet up.
However, a firm motivated by increasing its mass of profit (equivalently, its share of overall surplus value) is motivated to invest in productivity above a third threshold , which we also prove exists, and show that . Thus there is a range of investments that improve the profit mass of a single firm but also reduce the rate of profit when rolled out to both firms.
As a result, under the assumptions with which I am working, we can interpret Marx’s Law of the Tendency of the Rate of Profit to Fall to be an accurate summary of economic evolution in purely value terms, under the assumption that firms often seek out moderately productivity-enhancing innovations, so long as radically productivity-enhancing innovations are rare.
1. The Law of the Tendency of the Rate of Profit to Fall
Marx famously argued that the very innovations that make labour more productive eventually pull the average rate of profit downward. My understanding as a non-economist is that, even in Marxian economic circles, this law is controversial. Over my summer holiday, I have been reading a little about this (the literature is vast) and there are many complex arguments on both sides, often very wordy or apparently relying on assumptions that do not line up with a simple LTV analysis.
The aim of this post is thus to show, in the simplest possible algebra, how perfectly reasonable investment decisions by competitive firms reproduce Marx’s claim, providing explicit analysis for how the scale of productivity gains impact on the rate of profit and on individual motivating factors for the firms involved.
2. Set-up and notation
I will be working purely in terms of value, as I understand it from Capital Volume 1, i.e. socially necessary labour time (SNLT) – I will pass a very brief comment on price at the end of the post. We will use the following variables throughout the analysis, each with units of “socially necessary labour time per unit production period”.
Symbol
Definition
Economic reading in Capital
overall constant capital
machinery + materials
overall variable capital
value of wages
overall surplus value
unpaid labour
constant capital advanced by Firm i
machinery + materials
variable capital advanced by Firm i
value of wages
In addition, we will consider the following dimensionless scalar variables:
Symbol
Definition
Economic reading in Capital
The baseline production rate of commodities by Firm 2, as a multiple of that produced by Firm 1
capital deepening factor: the ratio of the post-investment capital advanced to the pre-investment capital advanced, evaluated in terms of SNLT at the time of investment
dearer machine (III §13)
labour-productivity factor: the ratio of the number of production units produced per unit production time post-investment to the same quantity prior to the investment.
fewer hours per unit (III §13)
We will work throughout under the constraint that . This can be interpreted as Marx’s “limits of the working day” (CapitalI §7) and flows directly from the LTV. Below I will refer to this as “the working day constraint”.
Before embarking on an analysis of productivity raising, it is worth understanding the rate of profit at an aggregate level. Marx defined the rate of profit as:
During my reading on the rate of profit, I have seen a number of authors describe the tendency of the rate to fall in the following terms: divide numerator and denominator by , to obtain . At that point an argument is sometimes made that keeping (the rate of surplus labour, or the rate of exploitation) constant (or bounded from above), as as . This immediately raises two questions: why should remain constant (or bounded), and why should ? In this post, I will attempt to show that the first of these assumptions is irrelevant, while providing a reasonable basis to understand the second. As a prelude, we will now prove the following elementary theorem:
Theorem 1 (Rate of Profit Declines with Increasing Capital Value). Under the working-time constraint, .
Proof.. □
It is worth noting that implies that , but the latter is not sufficient for – a simple counterexample would be to keep constant while , leading to an asymptotic rate of profit of .
Theorem 1 forms our motivation to consider why we may see increasing without bound. To understand this, we will be considering three scenarios:
Scenario A: the baseline. Each firm is producing in the same way, but they may have a different scale of production. We will normalise production of Firm 1 to 1 unit of production, with Firm 2 producing units of production per unit production time.
Scenario B: after a general rise in productivity. Each firm is again producing in the same way, with the same ratio of production units as Scenario A. Each firm has, however, made the same productivity-enhancing capital investment, so that Firm 1 is now producing units and Firm 2 is now producing units of production per unit time.
Scenario C: only a single firm, Firm 1, implements the productivity-enhancing capital investment. Firm 1 is now producing units and Firm 2 is still producing units of production per unit time. This scenario allows us to explore differences in rate and mass of profit for Firm 1 compared to Scenario A and Scenario B, proving several of the results mentioned at the outset of this post.
3. Scenario A — baseline
We have: and .
The total value of the units of production produced is (using the working day constraint). Each unit of production therefore has a value of . Firm 1 is producing 1 of these units.
The surplus value captured by (profit mass of) Firm 1 is therefore .
This gives an overall rate of profit for Firm 1 of: .
This rate of profit is the same for Firm 2, and indeed for the overall combination of the two. We now have a baseline rate and mass of profit, against which we will make several comparisons in the next two scenarios.
4 Scenario B — both firms upgrade
In this scenario, both firms upgrade their means of production, leading to productivity boost by a factor of , after an increase in the value of capital advanced by a factor of . We will assume that the firms keep the number of working hours constant, and ‘recycle’ the productivity enhancement to produce more goods rather than to drop the labour time employed.
We must carefully consider the impact on the value of variable and fixed capital of this enhancement. The value of variable capital has decreased by a factor , because it is now possible to meet the same consumption needs of the workforce with this reduced SNLT. Of course, we could make other assumptions, e.g. the ability of the labour force to ‘track’ productivity gains in terms of take-home pay, but the assumption of fixed real wages appears to be the most conservative reasonable assumption when it comes to demonstrating the fall of the rate of profit. Equally, the value of the fixed capital has reduced from the original for Firm to , because a greater investment has been made at old SNLT levels () but this investment has itself depreciated in value due to productivity gains. Marx refers to this as ‘cheapening’ in Capital III §14.
We will use singly-primed variables to denote the quantities in Scenario B, in order to distinguish them from Scenario A. We have:
The total value of the units of production produced is . Remembering that our firms together now produce units of production, each unit therefore has value .
Firm 1 is responsible for of these units, and therefore a value of . We may therefore calculate the portion of surplus labour it captures as:
, and its rate of profit as:
.
Simplifying, we have
.
These will be the same rate for Firm 2 (and overall) and a proportionately scaled mass for Firm 2.
It is clear that , i.e. profit mass is always increased by universally adopting an increased productivity (remember we are keeping real wages constant). However, it is not immediately clear what happens to profit rate.
Theorem 2 (Critical productivity rate for universal adoption). For any given set of variables from Scenario A, there exists a critical productivity rate . We have iff .
Proof. Firstly, we will establish that . This follows from the fact that and are both strictly less than 1.
Now iff . Clearing (positive) denominators and noting gives the equivalent inequality . Isolating gives . □
The the overall rate of profit in Scenario 2 can rise or fall, depending on the level of productivity those gains bring. The more the cost of the new means of production, the less is spent on wages, and the greater the fixed-capital intensive nature of the production process, the higher the productivity gain required to reach a rise in profit rate, arguably raising the critical threshold as capitalism develops. However, the fact that and that indicates it will always raise the rate of profit to invest in a productivity gain that’s more than the markup in capital required to implement that gain. That it is still beneficial for the overall rate of profit to adopt productivity gains less significant than the markup in capital expenditure, i.e. when , appears to be consistent with Marx’s Capital III §14, where he appears to be assuming this scenario.
5 Scenario C — Firm 1 upgrades alone
We are interested in now exploring a third scenario: the case where Firm 1 implements a way to increase its own productivity through fixed capital investment, but this approach is kept private to Firm 1. This scenario is useful for understanding cases that may motivate Firm 1 to improve productivity and to understand to what degree they differ from the cases motivating both firms to improve productivity by the same approach.
As per Scenario B, it is important to understand the changes to the SNLT required in production. In Capital I §1, it is clear that Marx saw this as an average. A suitable cheapening factor for labour in these circumstances is because with the same labour () as in Scenario A, we have gone from the overall social production of units of production ( from Firm 2 and 1 from Firm 1), to units of production.
In this scenario we will use doubly primed variable names to distinguish the variables from the former two scenarios. We will begin, as before, with fixed capital, noting that both firms’ capital and labour has cheapened through the change in SNLT brought about by the investment of Firm 1, however Firm 1 also bears the cost of that investment:
and .
.
The total value of the units of production produced by both firms during unit production time is now .
This means that since units of production are being produced, each unit of production now has value . As we did for Scenario B, we can now compute the value of the output of production of Firm 1 by scaling this quantity by , obtaining output value . We may then calculate the surplus value captured by Firm 1 by subtracting the corresponding fixed and variable capital quantities, remembering that both have been cheapened by the reduction in SNLT:
.
The first term in this profit mass expression simply reveals the revalued living labour contributed. The second term is intriguing. Why is there a term that depends on fixed capital value when considering the profit mass under the labour theory of value? Under the assumptions we have made, this happens because although fixed-capital-value-in = fixed-capital-value-out at the economy level, this is no longer true at the firm level; this corresponds to a repartition of SNLT in the market between Firm 1 and Firm 2, arising due to the fundamental assumption that each basket of production has the same value, independently of how it has been made. It is interesting to note that this second term, corresponding to revalued capital, changes sign depending on the relative magnitude of and . For , the productivity gain is high enough that Firm 1 is able to (also) boost its profit mass by capturing more SNLT embodied in the fixed capital, otherwise the expenditure will be a drag on profit mass, as is to be expected.
Now we have an explicit expression for , we may identify the circumstances under which profit mass rises when moving from Scenario A to Scenario C.
Theorem 3 (Critical Productivity Rate for Solo-Profit Mass Increase). For any given set of variables from Scenario A, there exists a critical productivity rate for which we have iff .
Proof. We will begin by considering the difference between surplus value captured in Scenario C and that captured in the baseline Scenario A. We will consider this as a function of .
.
Differentiating with respect to ,
.
Both denominators are positive. The first numerator is clearly positive. The second numerator is also positive for . Hence is strictly increasing over the interval .
Now note that as , . However, at , simplifies to . Hence by the intermediate value theorem and strict monotonicity there is a unique value with such that iff . □
At this point, it is worth understanding where this critical profit-mass inducing productivity increase lies, compared to the value we computed earlier as the minimum required productivity increase in Scenario B required to improve the rate of profit. It turns out that this depends on the various parameters of the problem. However, a limiting argument shows that for large Firm 1, any productivity enhancement will improve profit mass, whereas for small Firm 1 under sufficiently fixed-capital-intensive production, only productivity enhancements outstripping capital deepening would be sufficient:
Theorem 4 (Limiting Firm Size and Solo-Profit Mass). As , . As , .
Proof. Both statements follow by direct substitution into the expression for given in the proof of Theorem 3 and taking limits. □
It is worth dwelling briefly on why there is this dichotomous behaviour between large and small firms. A large Firm 1 () has an output that dominates the value of the product; it takes the lion share of SNLT, and the only impact on the firm of raising its productivity is to reduce the value of labour power as measured in SNLT, which will always be good for the firm. However, a small Firm 1 () has no impact on the value of the product or of labour power. It is certainly able to recover more overall value from the products in the market (the term ), but it must carefully consider its outlay on fixed-capital. In particular if , only small – a low capital intensity – would lead to a rise in profit mass.
So at least for large firms (or low capital intensity) there is a range of productivity enhancements that will induce a rise in profit mass for solo adopters (Scenario C) but would lead to a fall in the overall rate of profit when universally adopted (Scenario B).
It is now appropriate to consider the individual rate of profit of Firm 1 in Scenario C, having so far concentrated only on the mass of profit.
The rate of profit of Firm 1 in Scenario C is:
.
As with the mass of profit, we are able to demonstrate the existence of a critical value of productivity, above which Firm 1 increases its rate of profit as a solo adopter:
Theorem 5 (Critical Productivity Rate for Solo-Profit Rate Increase). For any given set of variables from Scenario A, there exists a critical productivity rate for which we have iff .
Proof. As per the proof of the profit mass case, we will firstly compute the difference between the two scenarios, which we will denote . Forming a common denominator that does not depend on between the expressions for and allows us to write where . Note that is differentiable for , with:
Hence is strictly increasing with .
Now let’s examine the sign of as . Firstly, by direct substitution, , where we have also recognised that , total surplus value in Scenario A, is . This expression simplifies to . Of the three multiplicative terms, the first is negative () while the other two are positive. Hence becomes negative as , and hence so does .
We should also examine the sign of at . This time, , which simplifies to . Since both multiplicative terms are positive, and hence is positive.
So again we can make use of the intermediate value theorem, combined with our proof that is strictly increasing to conclude that there exists a unique such that iff , completing the proof. We have already shown that that via the second half of the sign-change argument. □
It remains, now, to try to place in magnitude compared to the other critical value we discovered, :
Theorem 6 (Productivity required for solo rate improvement dominates that required for universal rate improvement)..
Proof. We can place our earlier expressions for and over a common denominator that does not depend on . Here and where and .
Note that . Evaluating at , we have . From Theorem 2, we know that and so the second term is negative and so .
Since was independent of and positive, we can conclude that . However, we also know that by definition of . Hence . And we may therefore conclude that . □
This theorem demonstrates that there is no “prisoner’s dilemma” when it comes to rate of profit in this model: if a firm is motivated to invest in order to raise its own rate of profit ( then that investment will also raise overall rate of profit if implemented universally.
6. Summary of Thresholds
We have demonstrated a number of critical thresholds of productivity increase. Collecting results, we have
In the case of large firms (or production that is sufficiently low in fixed-capital input), we may also write:
A numerical example of these thresholds is illustrated below, for the large firm case.
Several conclusions flow from this order:
There are no circumstances under which a firm, to improve its rate of profit, makes an investment that will not also improve the rate of profit if universally adopted ().
There are cases, especially for large firms, where investments that may be attractive from the perspective of improving profit mass nevertheless reduce profit rate ().
There are productivity-enhancing investments that may be unattractive from a purely driven (either mass or rate).
7. Conclusion: The Falling Rate of Profit
In this model, we can conclude that continuous investment in moderately productivity-enhancing means of production () will lead to a falling rate of profit. Overall capital value will grow, which (Theorem 1) will lead to a falling rate of profit independent of assumptions on the rate of exploitation (rate of surplus value) .
The results in this post suggest that, if value after investment is considered by the investing firm, a key driver for this capital investment may not be the individual search for rate-of-profit enhancement by individual firms but rather simply a drive to increase their profit mass, capturing a larger proportion of overall surplus value, a situation particularly relevant under constraints on the total working time available (e.g. constrained population), and a common situation for large firms.
Some further remarks:
It is important to note that unlike a typical Marxian analysis, none of these results rely on the dislocation of price and value. Of course, it is quite plausible that the incentive to invest is based not on value but rather on current prices, but we have been able to show that such dislocation is not necessary to explain a falling rate of profit.
We have also not considered temporal aspects. It is possible that investment could be motivated by values before investment, leading to ‘apparent’ rates and masses of profit, rather than values after investment. To keep this post at a manageable length, I have not commented on this possibility, but again the aim has been to show that the falling rate can be explained without recourse to this.
We have not discussed the economic advantage that Firm 1 in Scenario 3 may have, e.g. being able to use its additional surplus value for power over the market. This may be an additional motivator for Firm 1 to move despite lower rate of profit, further accelerating the decline in the rate of profit.
Finally, as noted earlier in the post, we have preserved real wages in value after productivity enhancements, rather than allowed real wages to track productivity or benefit even slightly from productivity enhancement. This is a purposely conservative assumption, made as it seems the most hostile to retaining the falling rate of profit, and yet we still obtain a falling rate. If we allow wages to scale with productivity, this will of course further reduce the rate of profit.
I would very much welcome comments from others on this analysis, in particular over whether you agree that my analysis is consistent with Marx’s LTV framework.
Acknowledgements
The initial motivation for this analysis came from discussions with TG, YL and LW. I improved my own productivity by developing the mathematics and plot in this blog post using a long sequence of interactive sessions with the o3 model from OpenAI over a last week or so.
Update 28/6/25: The proof of Theorem 3 contained an error spotted by YL. This has now been fixed.
Update 12-13/7/25: Added further clarification of redistribution of value in Scenario C following discussion with YL and LW. Corrected an earlier overly simple precondition for spotted by YL.
I’ve recently returned from the IEEE International Symposium on Field-Programmable Custom Computing Machines (known as FCCM). I used to attend FCCM regularly in the early 2000s, and while I have continued to publish there, I have not attended myself for some years. I tried a couple of years ago, but ended up isolated with COVID in Los Angeles. In contrast, I am pleased to report that the conference is in good health!
The conference kicked off on the the evening of the 4th May, with a panel discussion on the topic of “The Future of FCCMs Beyond Moore’s Law”, of which I was invited be be part, alongside industrial colleagues Chris Lavin and Madhura Purnaprajna from AMD, Martin Langhammer from Altera, and Mark Shand from Waymo. Many companies have tried and failed to produce lasting post-Moore alternatives to the FPGA and the microprocessor over the decades I’ve been in the field and some of these ideas and architectures (less commonly, associated compiler flows / design tools) have been very good. But, as Keynes said, “markets can remain irrational longer than you can remain solvent”. So instead of focusing on commercial realities, I tried to steer the panel discussion towards the genuinely fantastic opportunities our academic field has for a future in which power, performance and area innovation changes become a matter of intellectual advances in architecture and compiler technology rather than riding the wave of technology miniaturisation (itself, of course, the product of great advances by others).
The evening panel, as imagined by AI. I’m 2nd to left. The AI tool was clearly unaware of Martin’s height difference!The reality of the panel. We look older, and we don’t have beer.
The following day, the conference proper kicked off. Some highlights for me from other authors included the following papers aligned with my general interests:
AutoNTT: Automatic Architecture Design and Exploration for Number Theoretic Transform Acceleration on FPGAs from Simon Fraser University, presented by Zhenman Fang.
RealProbe: An Automated and Lightweight Performance Profiler for In-FPGA Execution of High-Level Synthesis Designs from Georgia Tech, presented by Jiho Kim from Callie Hao‘s group.
High Throughput Matrix Transposition on HBM-Enabled FPGAs from the University of Southern California (Viktor Prasanna‘s group).
ITERA-LLM: Boosting Sub-8-Bit Large Language Model Inference Through Iterative Tensor Decomposition from my colleague Christos Bouganis‘ group at Imperial College, presented by Keran Zheng.
Guaranteed Yet Hard to Find: Uncovering FPGA Routing Convergence Paradox from Mirjana Stojilovic‘s group at EPFL – and winner of this year’s best paper prize!
In addition, my own group had two full papers at FCCM this year:
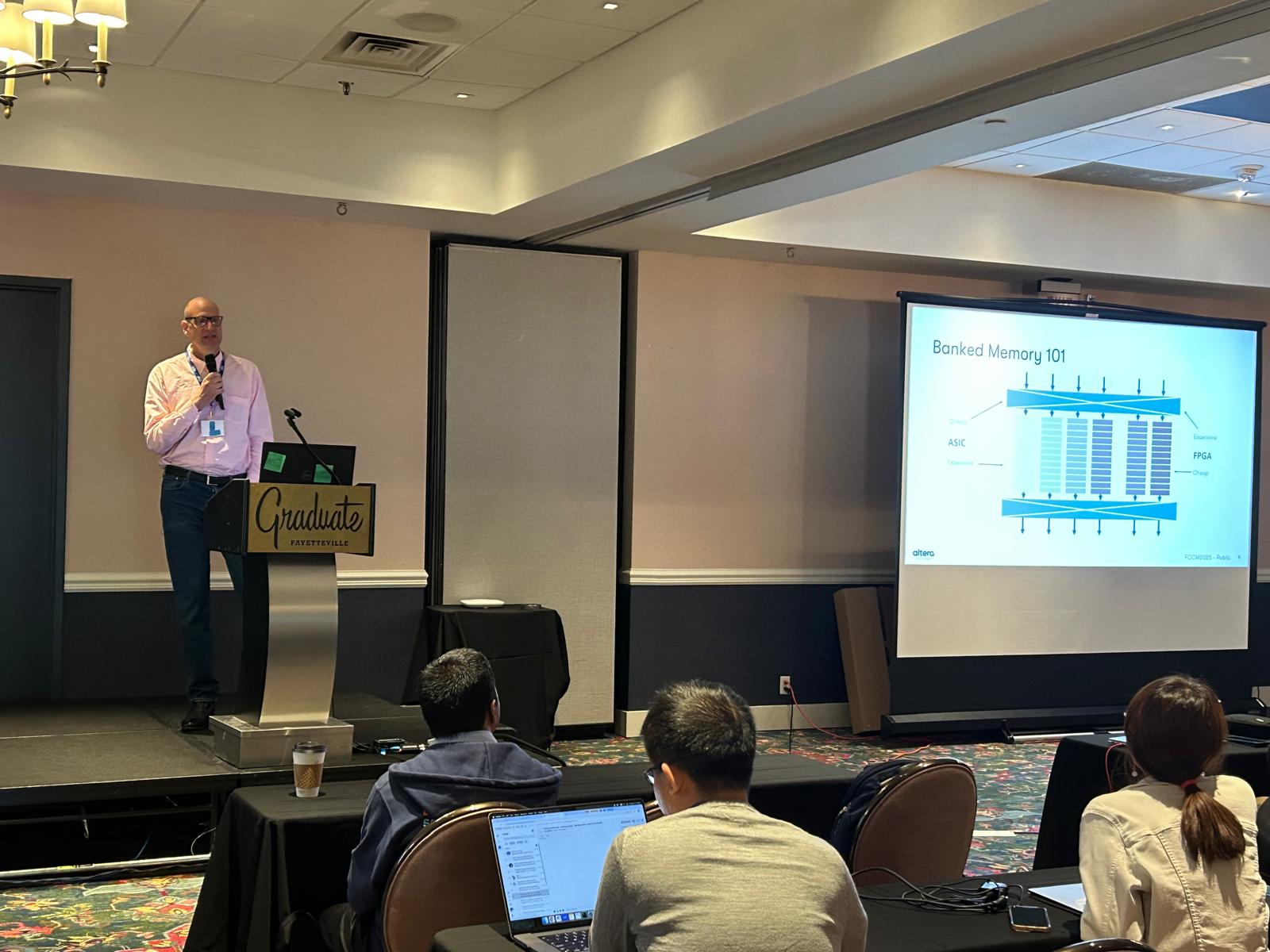
Banked Memories for Soft SIMT Processors, joint work between Martin Langhammer (Altera) and me, where Martin has been able to augment his ultra-high-frequency soft-processor with various useful memory structures. This is probably the last paper of Martin’s PhD – he’s done great work in both developing a super-efficient soft-processor and in forcing the FPGA community to recognise that some published clock frequency results are really quite poor and that people should spend a lot longer thinking about the physical aspects of their designs if they want to get high performance.
NeuraLUT-Assemble: Hardware-aware Assembling of Sub-Neural Networks for Efficient LUT Inference, joint work between my PhD student Marta Andronic and me. I think this is a landmark paper in terms of the results that Marta has been able to achieve. Compared to her earlier NeuraLUT work which I’ve blogged on previously, she has added a way to break down large LUTs into trees of smaller LUTs, and a hardware-aware way to learn sparsity patterns that work best, localising nonlinear interactions in these neural networks to within lookup tables. The impact of these changes on the area and delay of her designs is truly impressive.
Martin explaining efficient memory structures for soft processorsMarta explaining LUT-based neural networks on FPGAs
Overall, it was well worth attending. Next year, Callie will be hosting FCCM in Atlanta.





is the high-precision tensor-wide scale,
is the low-precision per-block scale, and
denotes direct sum (block concatenation).








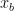

be the number of exponent bits,
be the significand precision in bits, and
be the total scale-field width.



































 . For example,
. For example,  , then the unscaled vectors we can represent are the product set
, then the unscaled vectors we can represent are the product set 


 , how close is the nearest direction obtainable from the alphabet
, how close is the nearest direction obtainable from the alphabet  is better.
is better.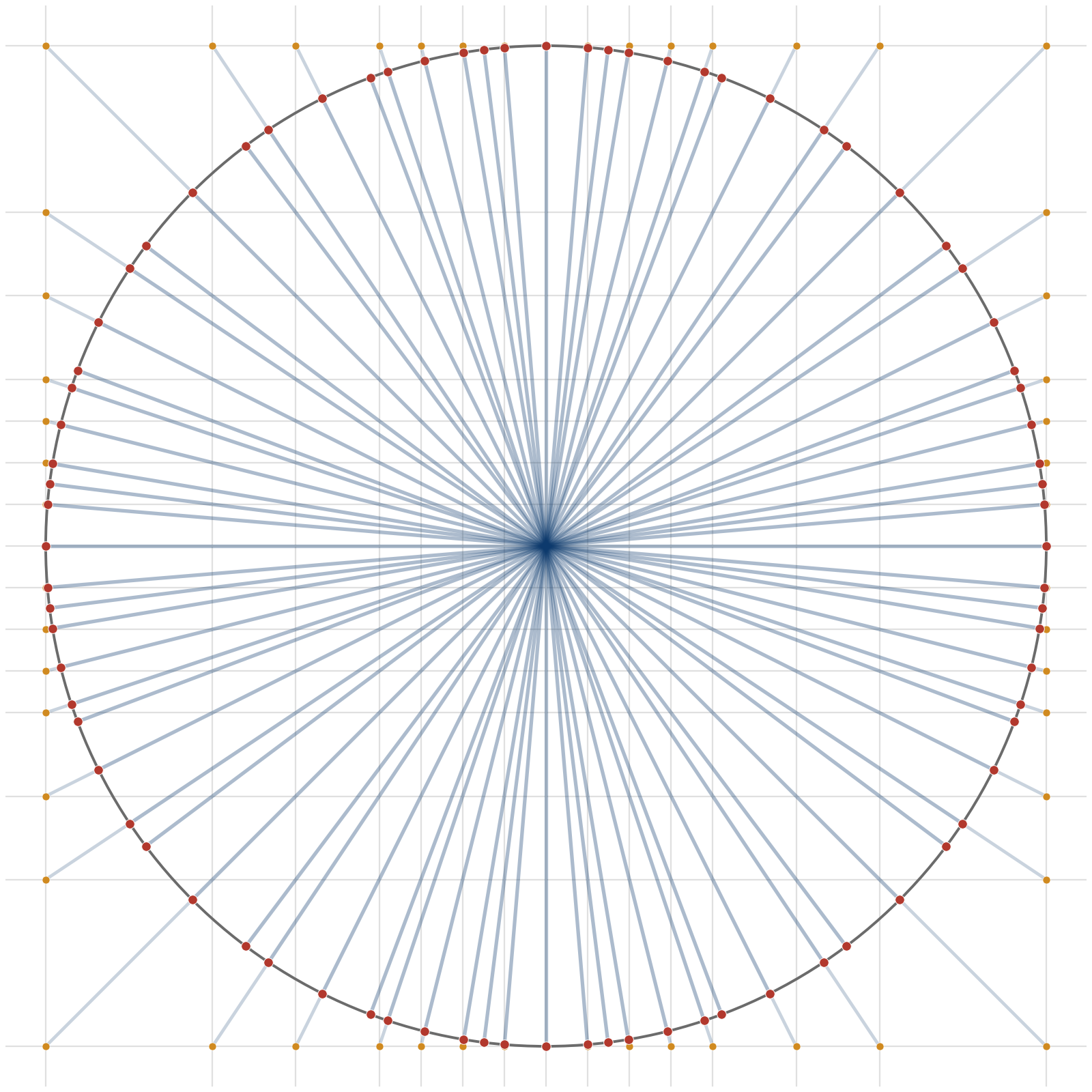
 elements. The definition
elements. The definition 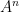 . The quantity
. The quantity  points.
points. 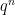 raw vectors, those vectors are not arbitrary. They arise from independent coordinate choices from the same scalar alphabet. Meanwhile, a spherical code with
raw vectors, those vectors are not arbitrary. They arise from independent coordinate choices from the same scalar alphabet. Meanwhile, a spherical code with 

 is the smaller of the number of positive and negative nonzero values in
is the smaller of the number of positive and negative nonzero values in 
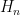 grows like
grows like  , this bound tends towards
, this bound tends towards 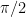 for any fixed alphabet. In plain language: in sufficiently high dimension, every fixed scalar alphabet has some direction that it represents very badly.
for any fixed alphabet. In plain language: in sufficiently high dimension, every fixed scalar alphabet has some direction that it represents very badly.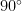 in high dimension (see above), it is more informative when comparing product codes to look at a normalised quantity such as:
in high dimension (see above), it is more informative when comparing product codes to look at a normalised quantity such as:
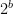 -element scalar alphabet. The quantity normBestFpCos n b is the corresponding floating-point quantity, optimised over valid splits of exponent and mantissa bits. The constants arbConst b and fpConst b are the two asymptotic constants being compared.
-element scalar alphabet. The quantity normBestFpCos n b is the corresponding floating-point quantity, optimised over valid splits of exponent and mantissa bits. The constants arbConst b and fpConst b are the two asymptotic constants being compared. , arbitrary scalar alphabets can do strictly better than the floating-point family in this asymptotic directional metric.
, arbitrary scalar alphabets can do strictly better than the floating-point family in this asymptotic directional metric.

 , and each block is approximated as
, and each block is approximated as  , where
, where  is a scalar block scale.
is a scalar block scale. .
. . Then
. Then  .
. , so that
, so that  (the proof is included at the end of this post).
(the proof is included at the end of this post).![x_b \in [2^{-1/2},\,2^{1/2}]](https://s0.wp.com/latex.php?latex=x_b+%5Cin+%5B2%5E%7B-1%2F2%7D%2C%5C%2C2%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. can be, when all the
can be, when all the ![[2^{-1/2},\,2^{1/2}]](https://s0.wp.com/latex.php?latex=%5B2%5E%7B-1%2F2%7D%2C%5C%2C2%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.![[\ell,u]](https://s0.wp.com/latex.php?latex=%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002) , then
, then (proof at the end of this blog post).
(proof at the end of this blog post). ,
,  , so
, so  , and therefore
, and therefore .
. .
. .
. , and
, and  .
. .
. , so that
, so that  , the numerator becomes
, the numerator becomes  and the denominator becomes
and the denominator becomes  , giving
, giving .
. 
![x_b \in [\ell,u]](https://s0.wp.com/latex.php?latex=x_b+%5Cin+%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002) with
with  .
. .
. . Since each
. Since each ![x_b\in[\ell,u]](https://s0.wp.com/latex.php?latex=x_b%5Cin%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002) , we have
, we have .
. .
. .
. .
. also lies in the interval
also lies in the interval  over
over ![\mu\in[\ell,u]](https://s0.wp.com/latex.php?latex=%5Cmu%5Cin%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. , the harmonic mean of
, the harmonic mean of 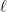 and
and  ,
, .
. .
. ,
, .
. whose coordinates are partitioned into blocks
whose coordinates are partitioned into blocks  .
. is invariant to rescaling of
is invariant to rescaling of  of a vector into its magnitude and direction, but applied locally within blocks.
of a vector into its magnitude and direction, but applied locally within blocks. , then scaling it appropriately produces a good approximation of that block.
, then scaling it appropriately produces a good approximation of that block. . Then
. Then  is the orthogonal projection of
is the orthogonal projection of  .
. .
. , which we can think of as the fraction of the vector’s energy contained in block
, which we can think of as the fraction of the vector’s energy contained in block  .
. represent how much of the vector’s energy lies in each block. Blocks that contain very little energy contribute very little to the final direction. The important consequence is that direction errors do not accumulate catastrophically across blocks. Instead, the overall directional error simply depends on a weighted average of the block direction errors. In other words, if block number formats preserve the directions of individual blocks, they automatically preserve the direction of the entire vector.
represent how much of the vector’s energy lies in each block. Blocks that contain very little energy contribute very little to the final direction. The important consequence is that direction errors do not accumulate catastrophically across blocks. Instead, the overall directional error simply depends on a weighted average of the block direction errors. In other words, if block number formats preserve the directions of individual blocks, they automatically preserve the direction of the entire vector. where
where  is orthogonal to
is orthogonal to  .
. .
. .
. , we obtain
, we obtain .
. .
. .
. , and writing
, and writing .
. , we obtain
, we obtain .
.




 (which we derive), above which innovation across firms raises the rate of profit of both firms, and below which the rate of profit is reduced.
(which we derive), above which innovation across firms raises the rate of profit of both firms, and below which the rate of profit is reduced. ). However, none of these investments would reduce the rate of profit of when rolled out across both firms (i.e.
). However, none of these investments would reduce the rate of profit of when rolled out across both firms (i.e.  ). There is therefore no “prisoner’s dilemma” of rates of profit causing capital investment to ratchet up.
). There is therefore no “prisoner’s dilemma” of rates of profit causing capital investment to ratchet up. , which we also prove exists, and show that
, which we also prove exists, and show that  . Thus there is a range of investments that improve the profit mass of a single firm but also reduce the rate of profit when rolled out to both firms.
. Thus there is a range of investments that improve the profit mass of a single firm but also reduce the rate of profit when rolled out to both firms.


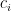




 . This can be interpreted as Marx’s “limits of the working day” (Capital I §7) and flows directly from the LTV. Below I will refer to this as “the working day constraint”.
. This can be interpreted as Marx’s “limits of the working day” (Capital I §7) and flows directly from the LTV. Below I will refer to this as “the working day constraint”.
 , to obtain
, to obtain  . At that point an argument is sometimes made that keeping
. At that point an argument is sometimes made that keeping  (the rate of surplus labour, or the rate of exploitation) constant (or bounded from above),
(the rate of surplus labour, or the rate of exploitation) constant (or bounded from above),  as as
as as  . This immediately raises two questions: why should
. This immediately raises two questions: why should  .
. . □
. □ implies that
implies that  constant while
constant while  , leading to an asymptotic rate of profit of
, leading to an asymptotic rate of profit of  .
. units and Firm 2 is now producing
units and Firm 2 is now producing  units of production per unit time.
units of production per unit time. and
and  .
. (using the working day constraint). Each unit of production therefore has a value of
(using the working day constraint). Each unit of production therefore has a value of  . Firm 1 is producing 1 of these units.
. Firm 1 is producing 1 of these units.  .
. .
. . We will assume that the firms keep the number of working hours constant, and ‘recycle’ the productivity enhancement to produce more goods rather than to drop the labour time employed.
. We will assume that the firms keep the number of working hours constant, and ‘recycle’ the productivity enhancement to produce more goods rather than to drop the labour time employed. to
to  , because a greater investment has been made at old SNLT levels (
, because a greater investment has been made at old SNLT levels (
 . Remembering that our firms together now produce
. Remembering that our firms together now produce  units of production, each unit therefore has value
units of production, each unit therefore has value  .
. . We may therefore calculate the portion of surplus labour it captures as:
. We may therefore calculate the portion of surplus labour it captures as: , and its rate of profit as:
, and its rate of profit as: .
.  .
. , i.e. profit mass is always increased by universally adopting an increased productivity (remember we are keeping real wages constant). However, it is not immediately clear what happens to profit rate.
, i.e. profit mass is always increased by universally adopting an increased productivity (remember we are keeping real wages constant). However, it is not immediately clear what happens to profit rate.  . We have
. We have  iff
iff  .
. . This follows from the fact that
. This follows from the fact that  and
and  are both strictly less than 1.
are both strictly less than 1.  . Clearing (positive) denominators and noting
. Clearing (positive) denominators and noting  . Isolating
. Isolating  . □
. □ , appears to be consistent with Marx’s Capital III §14, where he appears to be assuming this scenario.
, appears to be consistent with Marx’s Capital III §14, where he appears to be assuming this scenario. because with the same labour (
because with the same labour ( ) as in Scenario A, we have gone from the overall social production of
) as in Scenario A, we have gone from the overall social production of  units of production (
units of production ( units of production.
units of production. and
and  .
. .
. .
. units of production are being produced, each unit of production now has value
units of production are being produced, each unit of production now has value  . As we did for Scenario B, we can now compute the value of the output of production of Firm 1 by scaling this quantity by
. As we did for Scenario B, we can now compute the value of the output of production of Firm 1 by scaling this quantity by  . We may then calculate the surplus value captured by Firm 1 by subtracting the corresponding fixed and variable capital quantities, remembering that both have been cheapened by the reduction in SNLT:
. We may then calculate the surplus value captured by Firm 1 by subtracting the corresponding fixed and variable capital quantities, remembering that both have been cheapened by the reduction in SNLT:
 .
. , the productivity gain is high enough that Firm 1 is able to (also) boost its profit mass by capturing more SNLT embodied in the fixed capital, otherwise the expenditure will be a drag on profit mass, as is to be expected.
, the productivity gain is high enough that Firm 1 is able to (also) boost its profit mass by capturing more SNLT embodied in the fixed capital, otherwise the expenditure will be a drag on profit mass, as is to be expected. , we may identify the circumstances under which profit mass rises when moving from Scenario A to Scenario C.
, we may identify the circumstances under which profit mass rises when moving from Scenario A to Scenario C. for which we have
for which we have  iff
iff  .
. of
of  .
. .
. . Hence
. Hence  .
. ,
,  . However, at
. However, at  ,
,  simplifies to
simplifies to ![\Theta(\alpha) = \frac{(\alpha - 1)\left[ u+ (1+u)v_1 \right]}{(\alpha + u)(u + 1)} > 0](https://s0.wp.com/latex.php?latex=%5CTheta%28%5Calpha%29+%3D+%5Cfrac%7B%28%5Calpha+-+1%29%5Cleft%5B+u%2B+%281%2Bu%29v_1+%5Cright%5D%7D%7B%28%5Calpha+%2B+u%29%28u+%2B+1%29%7D+%3E+0&bg=ffffff&fg=000000&s=0&c=20201002) . Hence by the intermediate value theorem and strict monotonicity there is a unique value
. Hence by the intermediate value theorem and strict monotonicity there is a unique value  such that
such that  . □
. □ ,
,  . As
. As  ,
,  .
. ) has an output that dominates the value of the product; it takes the lion share of SNLT, and the only impact on the firm of raising its productivity is to reduce the value of labour power as measured in SNLT, which will always be good for the firm. However, a small Firm 1 (
) has an output that dominates the value of the product; it takes the lion share of SNLT, and the only impact on the firm of raising its productivity is to reduce the value of labour power as measured in SNLT, which will always be good for the firm. However, a small Firm 1 ( ), but it must carefully consider its outlay on fixed-capital. In particular if
), but it must carefully consider its outlay on fixed-capital. In particular if  , only small
, only small  – a low capital intensity – would lead to a rise in profit mass.
– a low capital intensity – would lead to a rise in profit mass. that will induce a rise in profit mass for solo adopters (Scenario C) but would lead to a fall in the overall rate of profit when universally adopted (Scenario B).
that will induce a rise in profit mass for solo adopters (Scenario C) but would lead to a fall in the overall rate of profit when universally adopted (Scenario B).  .
. for which we have
for which we have  iff
iff  .
. . Forming a common denominator
. Forming a common denominator  that does not depend on
that does not depend on  and
and  allows us to write
allows us to write  where
where ![N(\rho) := (c_1+v_1)\left[ \rho - (1+u)v_1 + \frac{u(u+1)c_1(\rho-\alpha)}{\rho+u} \right] - (\alpha c_1 + v_1)\left[ 1 - (1+u)v_1 \right]](https://s0.wp.com/latex.php?latex=N%28%5Crho%29+%3A%3D+%28c_1%2Bv_1%29%5Cleft%5B+%5Crho+-+%281%2Bu%29v_1+%2B+%5Cfrac%7Bu%28u%2B1%29c_1%28%5Crho-%5Calpha%29%7D%7B%5Crho%2Bu%7D+%5Cright%5D+-+%28%5Calpha+c_1+%2B+v_1%29%5Cleft%5B+1+-+%281%2Bu%29v_1+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Note that
. Note that  is differentiable for
is differentiable for  , with:
, with:![\frac{dN}{d\rho} = (c_1+v_1)\left[ 1 + u(u+1)c_1\frac{u+\alpha}{(\rho+u)^2} \right] > 0](https://s0.wp.com/latex.php?latex=%5Cfrac%7BdN%7D%7Bd%5Crho%7D+%3D+%28c_1%2Bv_1%29%5Cleft%5B+1+%2B+u%28u%2B1%29c_1%5Cfrac%7Bu%2B%5Calpha%7D%7B%28%5Crho%2Bu%29%5E2%7D+%5Cright%5D+%3E+0&bg=ffffff&fg=000000&s=0&c=20201002)
 is strictly increasing with
is strictly increasing with  . Firstly, by direct substitution,
. Firstly, by direct substitution, ![N(\rho) \to (c_1+v_1) \left[ S + c_1 u (1-\alpha) \right] - (\alpha c_1 + v_1)S](https://s0.wp.com/latex.php?latex=N%28%5Crho%29+%5Cto+%28c_1%2Bv_1%29+%5Cleft%5B+S+%2B+c_1+u+%281-%5Calpha%29+%5Cright%5D+-+%28%5Calpha+c_1+%2B+v_1%29S&bg=ffffff&fg=000000&s=0&c=20201002) , where we have also recognised that
, where we have also recognised that  . This expression simplifies to
. This expression simplifies to ![(1-\alpha)c_1 \left[S+ (c_1+v_1)u \right]](https://s0.wp.com/latex.php?latex=%281-%5Calpha%29c_1+%5Cleft%5BS%2B+%28c_1%2Bv_1%29u+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Of the three multiplicative terms, the first is negative (
. Of the three multiplicative terms, the first is negative (![N(\alpha) = (c_1+v_1)\left[ \alpha - (1 - S) \right] - (\alpha c_1 + v_1) S](https://s0.wp.com/latex.php?latex=N%28%5Calpha%29+%3D+%28c_1%2Bv_1%29%5Cleft%5B+%5Calpha+-+%281+-+S%29+%5Cright%5D+-+%28%5Calpha+c_1+%2B+v_1%29+S&bg=ffffff&fg=000000&s=0&c=20201002) , which simplifies to
, which simplifies to ![N(\alpha) = (\alpha - 1)v_1\left[ 1+ c_1(1 + u) \right]](https://s0.wp.com/latex.php?latex=N%28%5Calpha%29+%3D+%28%5Calpha+-+1%29v_1%5Cleft%5B+1%2B+c_1%281+%2B+u%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Since both multiplicative terms are positive,
. Since both multiplicative terms are positive,  and hence
and hence  is positive.
is positive. iff
iff  and
and  over a common denominator
over a common denominator  that does not depend on
that does not depend on  and
and  where
where  and
and  .
.  . Evaluating at
. Evaluating at  , we have
, we have  . From Theorem 2, we know that
. From Theorem 2, we know that  .
. was independent of
was independent of  . However, we also know that
. However, we also know that  by definition of
by definition of  . And we may therefore conclude that
. And we may therefore conclude that  then that investment will also raise overall rate of profit if implemented universally.
then that investment will also raise overall rate of profit if implemented universally.

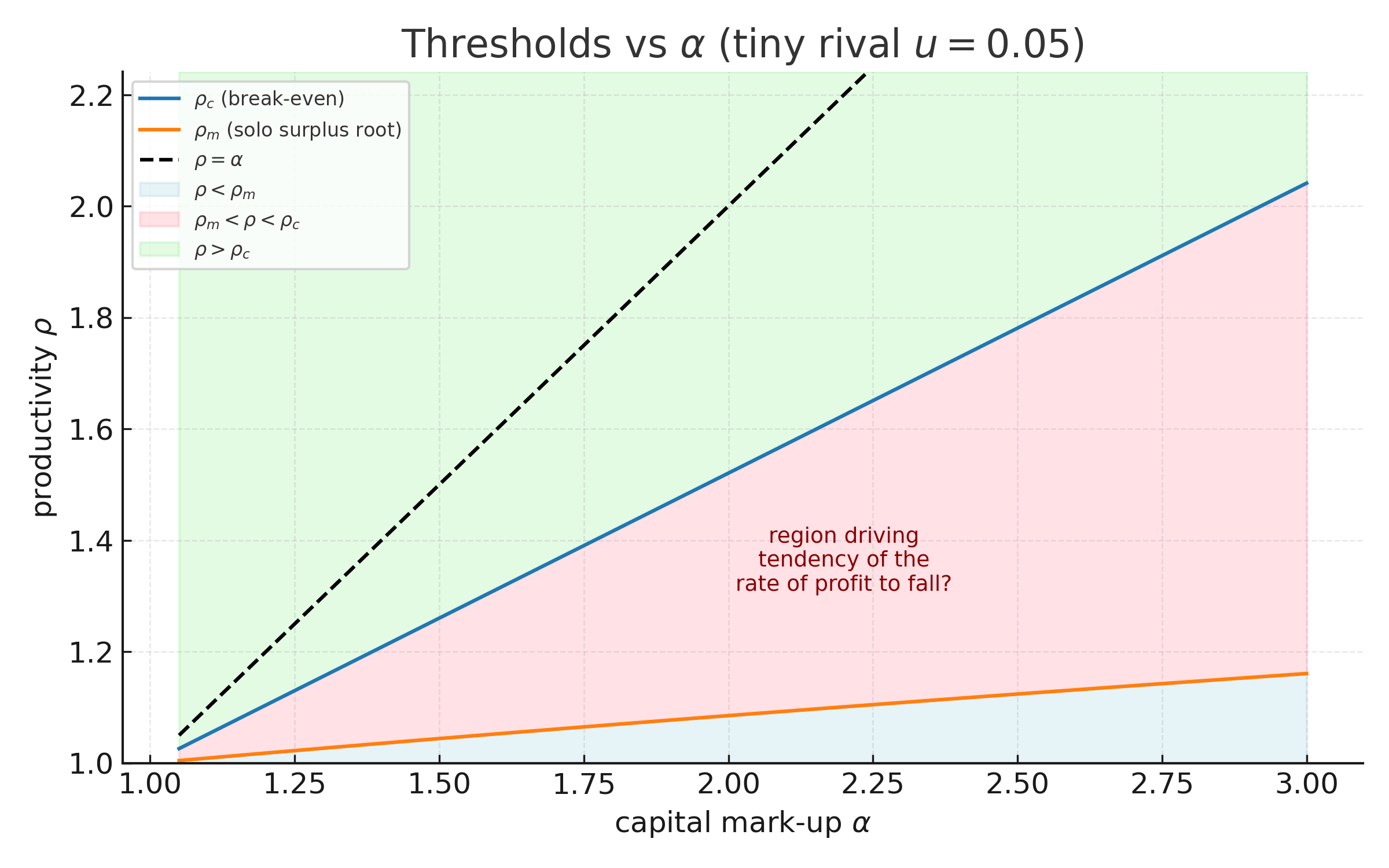
 ).
). .
.