In recent years there has been a rediscovery (sometimes multiple times!) of block floating point, a number representation used in the early days of the electronic computer for general purpose compute, but also in specialist areas such as signal processing, throughout the field’s history. The main reason for this modern rediscovery is the value of block floating point, and related ideas like block minifloat, in modern machine learning implementations.
Just like in the early days of floating point, a number of different approaches and implementations have flourished in recent years, so it was interesting to see the recent launch of the Open Compute Project OCP Microscaling Formats (MX) Specification, coauthored across Microsoft, AMD, Arm, Intel, Meta, NVIDIA and Qualcomm by a number of well-known figures (including Imperial’s very own Martin Langhammer). This document will be referred to as “the specification” in the rest of this blog post. At the same time, a paper was released on arXiv, supported by a GitHub repo, to show that when used for training deep neural networks (DNNs), MX-based implementations can produce high quality results.
In this blog post, I will briefly review a few of the features of the specification that I found particularly interesting as an “old hand” in fixed point and block floating point computer arithmetic, and raise some issues that the community may wish to take forward.
Firstly, I should say that it’s great to see efforts like this to raise the profile and awareness of block floating point and related number systems. My hope is that efforts like this will drive further work on the extremely important topic of efficient numerical hardware.
Storage
- Building block types. The focus of the specification is primarily one of storage, although certain computations are mentioned. The specification primarily defines the construction of a type for MX computations from three parameters: a (scalar) type for scalings, a (scalar) type for elements, and a (natural) number of elements. A value inhabiting this type is a scalar scaling
together with
elements,
, for
. The numbers represented are (except special values),
. This is a very flexible starting point, which is to be welcomed, and there is much to explore under this general hood. In all the examples given, the scalar data types are either floating point or integer/fixed point, but there seems to be nothing in the specification specifically barring other representations, which could of course go far beyond traditional block floating point and more recent block exponent biases.
- Concrete types. In addition to specifying a generic type constructor, as above, the specification also defines certain concrete instantiations, always with a power-of-two scaling stored in a conventional 8-bit biased integer exponent, and with either floating point or integer elements. By my reading of the specification, to obtain an MX-compliant implementation, one does not seem to need to implement any of these concrete types, however.
- Subnormals mandated. If implementing a concrete format specified, subnormal representations must be implemented.
Computation
1. Dot products
Apart from conversion into MX, the only MX operation discussed in the specification is dot products of MX vectors of equal number of elements. This appears to leave some basic operations undefined, for example simple addition of two MX vectors. (It is, of course, possible to provide a reasonable semantics for this operation consistent with the scalar base types, but it is not in the specification.)
The definition given of the “Dot” operation is interesting. The specification says “The following semantics must be minimally supported”, and gives the following equation:

where 



To my mind, the problem with this definition is that 
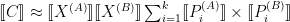
2. General Dot Products
The specification also defines an operation called “DotGeneral” which is a dot product of two vectors made up of MX-vector components. The specification defines it in the following way:

“where 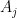



I would be interested to hear from any blog readers who think I have misinterpreted the standard, or who think other components of the specification – not discussed here – are more interesting. I will be watching for uptake of this specification: please do alert me of interesting uses.

Hi Prof. Constantinides,
Indeed you explained very well and very hot topic of todays computation. I still remember I while working on Systolic Arrays during my PhD, I went through these ideas you just has described.. but due to some limitation I could not proceed with block-floating point: later one student of H.T Kung did great similar application of block-floating point in ML accelerators (https://www.eecs.harvard.edu/htk/static/files/2022-hpca-zhang-mcdanel-kung.pdf).
I beleive the BFloat-16 adventure that Google did to have speedy computation with similar range as in single precision was good shot but to me it seems short-cut to chase the high speed by compromising the precision as usually people do in approximate computing.. I beleive there is space exist, e.g., if we can do dot-product summation without having the alignment and rounding stage: One possible way is to have a large width accumulation, may be e.g., 100 width for accumulation for single precision or 190 bits for double precision (like posit guys are doing nowadays), if we can crack this and able to do the accmulation without requiring alignment and rounding I think we can acheive similar results to Bfloat-16 without loosing precision. In short, we need to rethink the arithmetic for todays application specific hardwares (e.g., our one of DAC work is simple example with integer type computation: https://ieeexplore.ieee.org/abstract/document/9218585).
Regards,
Kashif
LikeLike