Over several holiday and train journeys, I’ve been slowly reading and digesting this book by Blum, Cucker, Shub, and Smale. It’s one of a number of books I’ve read that are definitively not in my research field – hence holiday reading – and yet touches it tangentially enough to get me excited. I’ve been interested in computation defined in terms of real numbers ever since my own PhD thesis back in 1998-2001, which looked at ways to take a specific class of computation defined on the reals and synthesise hardware circuits operating in very efficient fixed-point arithmetic. While my own work has often involved specifying computation on the reals, including recently exploiting the differences between real and finite precision computation for circuits, this book takes a fundamental look at computation over the reals themselves. In particular, it looks at what happens to notions of computability and complexity if you consider real addition, multiplication, division, and subtraction as basic operators in a computation model: what is computable, what resulting complexity bounds can be proved? Ever since my first exposure to algebraic geometry, especially real algebraic geometry, I see it everywhere – and have even made some small forays [1,2] into harnessing its power for hardware design. It’s a delight to see computability and algebraic geometry coming together so neatly in this text.
Part I: Basic Development
The authors define a computational model that is very natural for analysis: a computation consists of a control-flow graph consisting of input nodes, computation nodes (polynomial or rational maps), branch nodes (checking for equality or inequality, depending on whether the ring / field being computed over is ordered), and output nodes. For the remainder of this review, I will consider only computation over the reals, though some of the results are more general. Theorems naturally flow from this setting. My favourites: the halting set of a machine is a countable union of semialgebraic sets; there are “small” systems of polynomial inequalities, of low degree, describing behaviour of a machine up to 
Chapter 3 generalises classical results for universal Turing machines, typically expressed in terms of unbounded tapes with binary storage at each location, to the case where an element of an arbitrary ring is stored at each location (imagine a real number stored at each location). Additional shift operations are introduced to deal with moving along the tape. It is shown that operation over unbounded sequences allows for uniformity of algorithm across dimensionality but does not add additional computational power for fixed dimensionality. In finite time we can only explore a finite portion of the tape, so we still retain the semi-algebraic (or countable union of semi-algebraic) sets for the halting sets derived in Chapter 2.
Chapter 4 extends the usual complexity-theoretic classes P and EXP to computation over a ring. Computation over 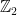

Chapter 5 shows how classical NP, NP-complete and NP-hard definitions carry forward into computation over a general ring. Then, specialising the results to particular rings and particular costs of elementary operations (unit? dependent on size of numbers?), the NP-completeness of various key problems are shown. In particular, it is shown that the classical 3-SAT NP-completeness result can be obtained by working over the ring
Chapter 6 moves on to look specifically at machines over
Part II: Some Geometry of Numerical Algorithms
This part of the book turns to look at specific algorithms such as Newton’s method and a homotopy method for nonlinear optimization. In each case, complexity results are given in terms of the number of basic real arithmetic operations required. Some fun analysis and quite a clear exposition of homotopy methods, which I’ve worked with before in the context of convex optimization, especially when using barrier methods for linear and convex quadratic programming, something I looked at quite carefully when trying to design FPGA-based computer architectures for this purpose.
The chapter on Bézout’s Theorem assumed a rather more thorough grounding in differential topology than I have, and I wasn’t entirely sure how it sat with the rest of the work, as the constructive / algorithmic content of the theorems was less apparent to me.
The final chapters of this part of the book took me back to more familiar territory – first introduced to me by the outstandingly clear encyclopaedic textbook by Nick Higham – the discussion of condition numbers for linear equations and the relationship to the loss of precision induced by solving such systems (roughly, the relative error in the right hand side of 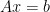

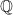
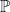
Part III: Complexity Classes over the Reals
After Part II, which was only interesting to me in parts, I started to get excited again by Part III. Lower bounds on the computational complexity of various problem are derived here based on some very interesting ideas. The basic scheme is to bound the number of different connected components in a (semi-)algebraic set in terms of the degree of the polynomials and the number of variables involved. The number of different connected components can then be used to bound the number of steps an (algebraic) machine takes to decide membership of that set.
In Chapter 17, the framework is extended to probabilistic machines, and the standard definition of BPP is extended to computation over an arbitrary ring, giving 
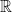

Parallelism – close to my heart – is covered in Chapter 18, through the introduction of complexity classes 

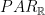
Chapter 22 looks at the relative power of machines over 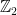


Descriptive Complexity, Chapter 23 is interesting: the descriptive power of (a particular) first order logic extended with fixed point and maximisation operations and of existential second order logic are shown to correspond to a particular subclass of 

Conclusion
Overall, I found this book a little eclectic, especially Part II, reflective of the fact that it has clearly been put together drawing from a variety of different primary sources spanning several decades. This should not be seen as a criticism. The choice of material was wonderful for me – as holiday reading at least! – tangentially touching so many different topics I’ve seen during my career and drawing me in. In places, the development was over an arbitrary ring, in places over