Ever since primary (elementary) school, we’ve known that multiplying an integer by 10 is easy. No need for the long written calculations we churn through when doing multiplication by hand. Just stick an extra zero on the end, and we’re done. Multiplication is (relatively) hard, concatenation of digits is easy. And yet, in this case, they’re equivalent in terms of the operation they perform.
Similar equivalences abound in the design of digital hardware for arithmetic computation, and my PhD student Sam Coward (jointly supervised by Theo Drane from Intel) has been devising ways to automatically take advantage of such equivalences to make Intel hardware smaller and more efficient. He will be presenting our work on this topic at the main computer arithmetic conference, ARITH, next week. The conference will be online, and registration is free: https://arith2022.arithsymposium.org.
Let’s explore this example from our early school years a bit more. I’ll use Verilog notation 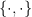
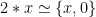



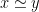


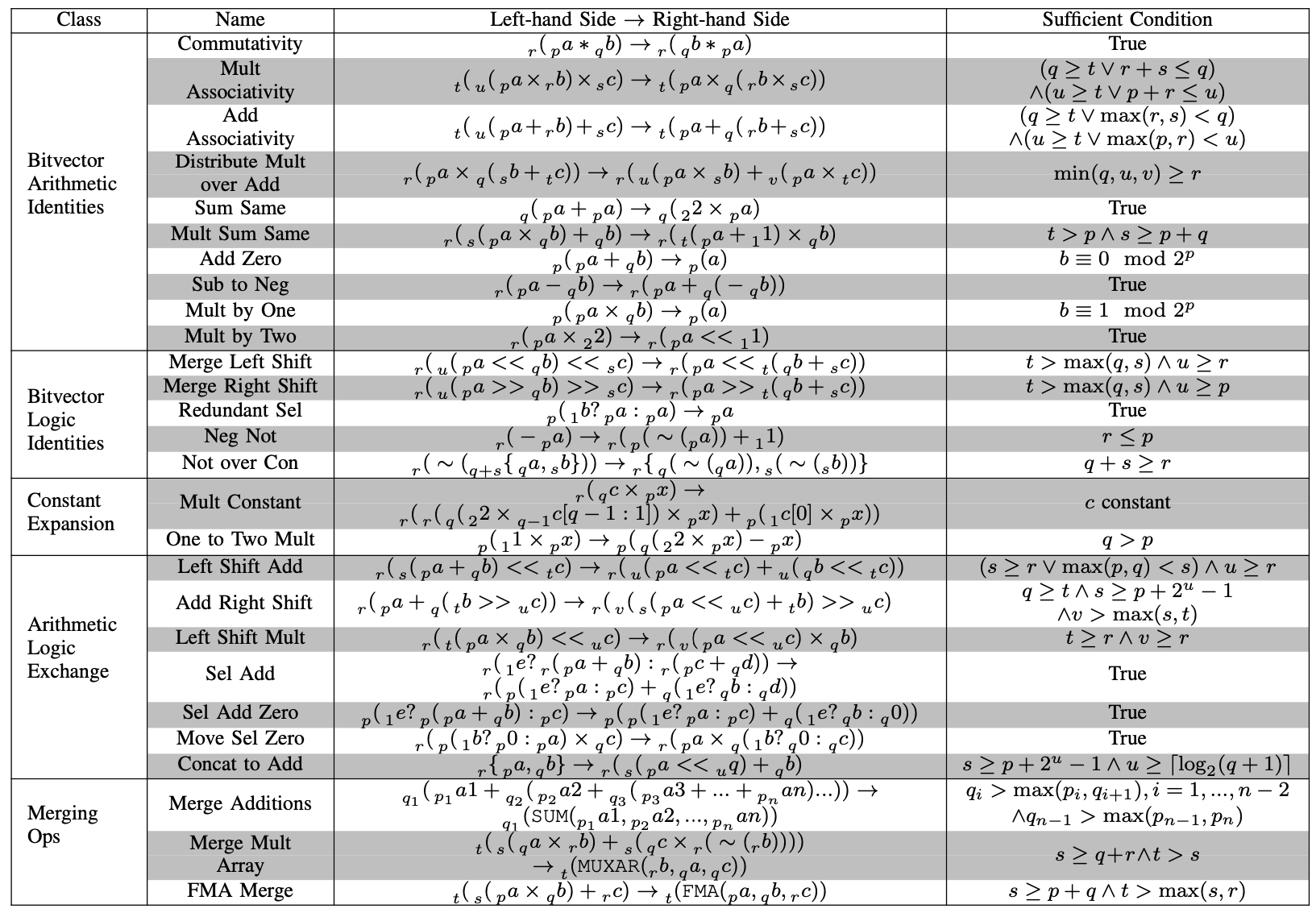
Our colleagues Willsey, Nandi, Wang, Flat, Tatlock and Panchekha recently published egg, a wonderful open source library for building and exploring data structures known as ‘e-graphs’, specifically designed to capture these relations on expressions. Sam, Theo and I have developed a set of ‘rewrites’ capturing some of the important intuition that Intel designers apply manually, and encoded these for use within egg. To give you a flavour of these rewrites, here’s the table from Sam’s paper; you can see the example we started with is hiding in there by the name ‘Mult by Two’. The subscripts are used to indicate how many digits we’re dealing with; not all these rules are true for arbitrarily-sized integers, and Sam has gone to some lengths to discover simple rules – listed here as ‘sufficient condition’ – for when they can be applied. This is really important in hardware, where we can use as few or as many bits as the job requires.
You can imagine that, when you have this many equivalences, they all interact and you can very quickly build up a very large set of possible equivalent expressions. e-graphs help us to compactly represent this large set.
Once our tool has spent enough time building such a representation of equivalences, we need to extract an efficient implementation as a hardware implementation. This is actually a hard problem itself, because common subexpressions change the hardware cost. For example if I’m calculating 
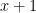
So, does it generate good circuits? It certainly does! The graph below shows the possible circuit area and performance achievable before (blue) and after (orange) the application of our tool flow before standard logic synthesis tools. For this example, silicon area can be reduced by up to around 70% – a very significant saving.
I’ve really enjoyed working on this topic with Sam and Theo. Lots more exciting content to follow. In the meantime, please tune in to hear Sam talk about it next week.

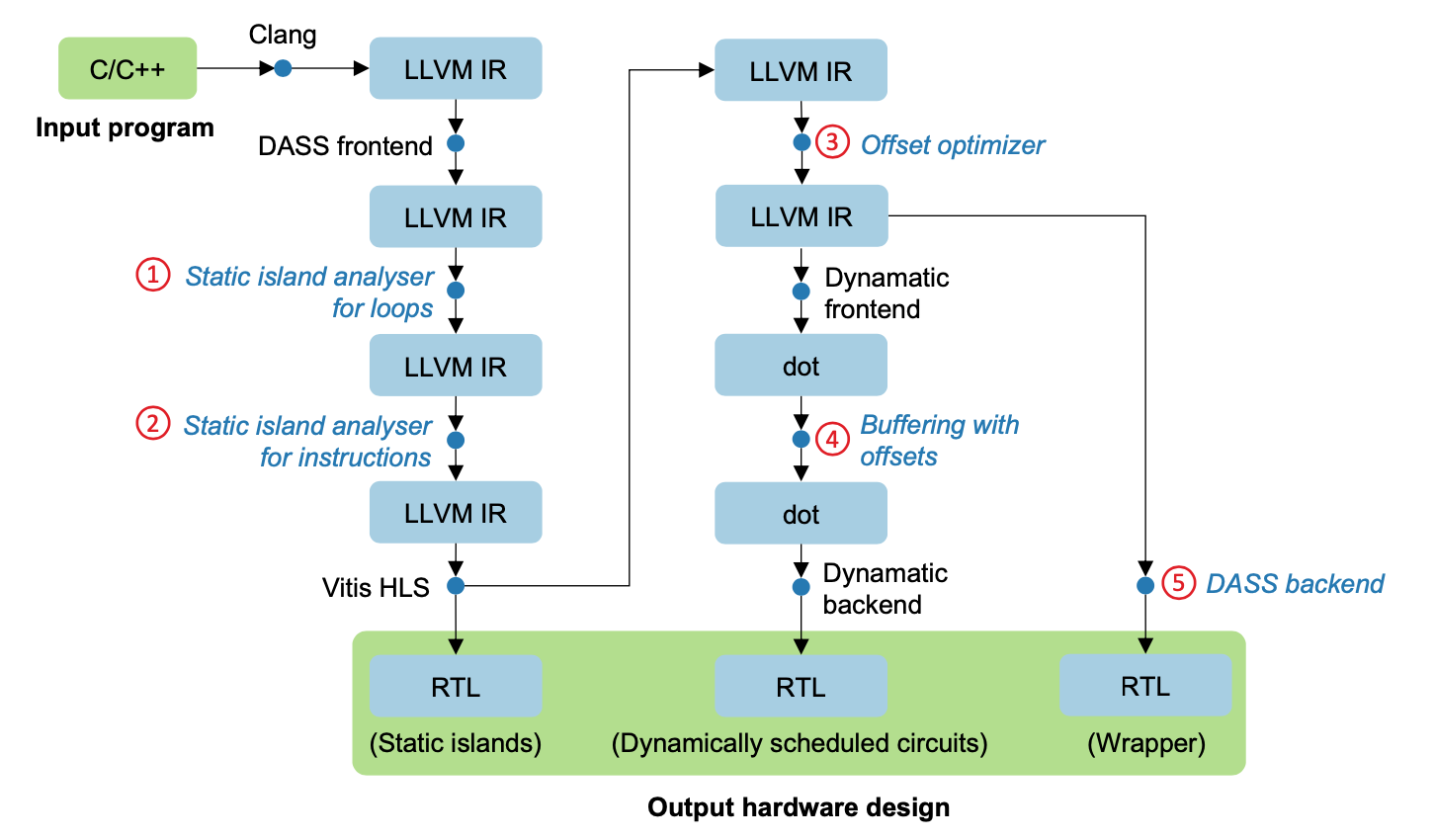
![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Clearly their sum is in the range
. Clearly their sum is in the range ![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=ffffff&fg=000000&s=0&c=20201002) . But what if we knew, a priori, that these two variables were related somehow? For example in the expression
. But what if we knew, a priori, that these two variables were related somehow? For example in the expression 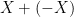 , which is clearly always zero. Ideally, an automated system should be able to produce a tighter result that
, which is clearly always zero. Ideally, an automated system should be able to produce a tighter result that 
