On Tuesday, my former PhD student Erwei Wang (now at AMD) will present our recent paper “Logic Shrinkage: Learned FPGA Netlist Sparsity for Efficient Neural Network Inference” at the ACM International Symposium on FPGAs. This is joint work with our collaborator Mohamed Abdelfattah from Cornell Tech as well as James Davis, George-Ilias Stavrou and Peter Y.K. Cheung at Imperial College.
In 2019, I published a paper in Phil. Trans. Royal Soc. A, suggesting that it would be fruitful to explore the possibilities opened up when considering the graph of a Boolean circuit – known as a netlist – as a neural network topology. The same year, in a paper at FCCM 2019 (and then with a follow-up article in IEEE Transactions on Computers), Erwei, James, Peter and I showed how to put some of these ideas into practice by learning the content of the Boolean lookup tables that form the reconfigurable fabric of an FPGA, for a fixed circuit topology.
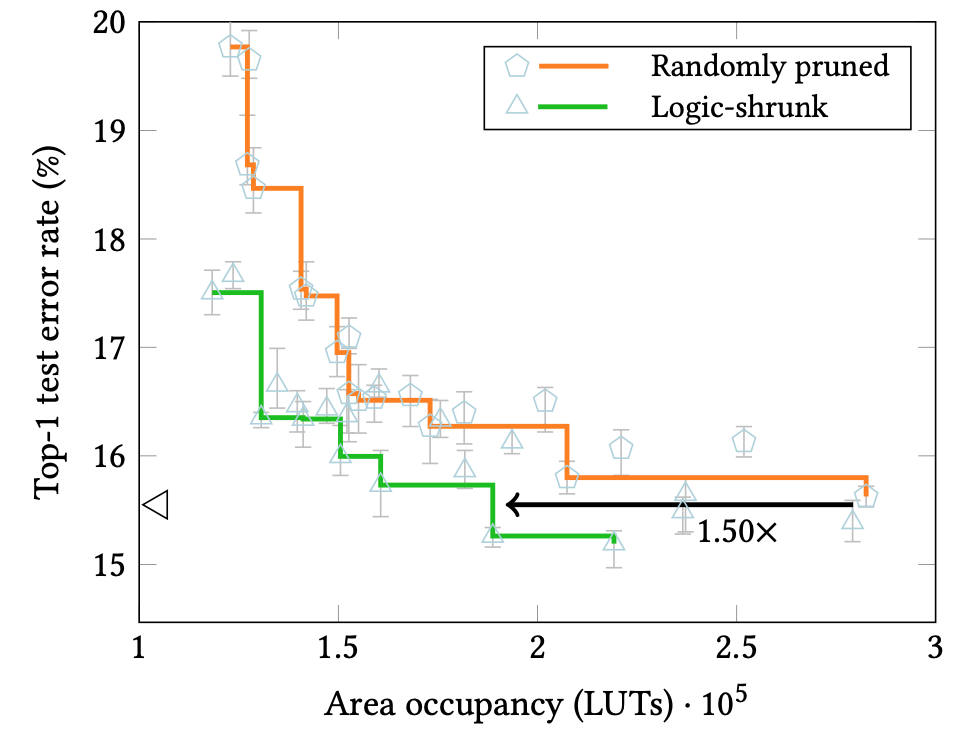
Our new paper takes these ideas significantly further and actually learns the topology itself, by pruning circuit elements. Those working on deep neural networks will be very familiar with the idea of pruning – removing certain components of a network to achieve a more efficient implementation. Our new paper shows how to apply these ideas to prune circuits made of lookup tables, leaving a simplified circuit capable of highly-efficient inference. Such pruning can consist of reducing the number of inputs of each Boolean LUT and, in the limit, removing the LUT completely from the netlist. We show that very significant savings are possible compared to binarising a neural network, pruning that network, and only then mapping it into reconfigurable logic – the standard approach to date.
We have open-sourced our flow, and our paper has been given a number of ACM reproducibility badges. Please try it out at https://github.com/awai54st/Logic-Shrinkage and let us know what you think. And, if you’re attending FPGA next week, reach out and say hello.