We all know that we have finite resources to accomplish a variety of tasks. Some tasks are easier than others, so we tend to spend less time and energy on them. Yet – when we survey the landscape of traditional neural networks – this observation does not apply to them. Take a convolutional neural network classifying pictures: does it do any less work (floating point operations, perhaps) if the picture is “obviously a cat” than if it’s a “cat hiding in the bushes”? Traditionally, the answer is a clear “no”, because there is no input dependence in the control-flow of the inference algorithm: every single image is processed in exactly the same way and takes exactly the same work.
But there are people who have looked to address this fundamental shortcoming by designing algorithms that put in less work if possible. Chief amongst these techniques is an approach known as “early exit neural networks”. The idea of these networks is that the network itself generates a confidence measure: if it’s confident early on, then it stops computing further and produces an early result.
My student Ben Biggs (jointly advised by Christos Bouganis) has been exploring the implications of bringing FPGAs to automatically accelerate such networks. There exist several good tool flows (e.g. fpgaConvNet, HPIPE) for automatically generating neural network implementations on FPGAs, but to the best of our knowledge, none of them support such dynamic control flow. Until now. Next week at FCCM 2023, Ben will be presenting our paper ATHEENA: A Toolflow for Hardware Early-Exit Network Automation.
The basic idea of ATHEENA is that early exit networks come in chunks, each of which is utilised a certain proportion of the time (e.g. 10% of images are hard to classify, 90% are not). So we make use of an existing neural network generator to generate each chunk, but allocate different FPGA resources to the different parts of the network, in order to maintain a steady throughput with no back pressure build-up points in the inference pipeline.
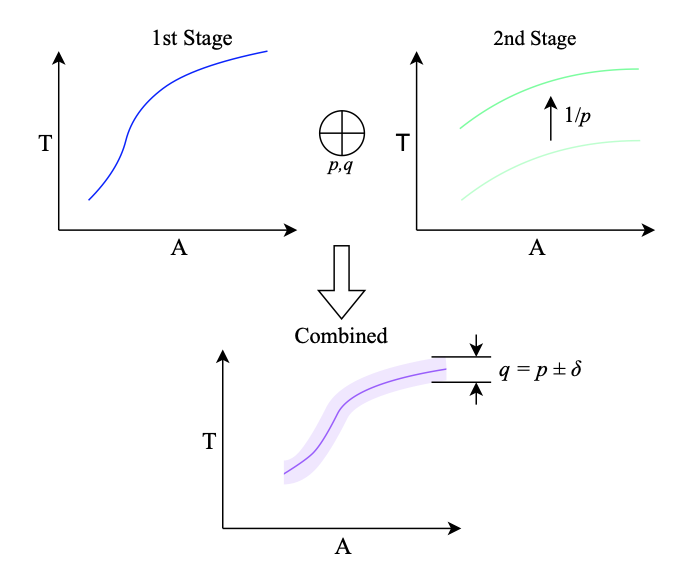
This principle is illustrated below. Imagine that the first stage of a network executes no matter what the input. Then I can create a throughput / area Pareto curve shown on the top left. Equally, I can create a throughput / area Pareto curve for the second stage, and then scale up the throughput achievable by a function of how frequently I actually need to use that stage: if it’s only needed 10% of the time, then I can support a classification rate 10x higher than the nominal throughput of the design returned by a standard DNN generator. By combining these two throughput / area curves for the same nominal throughput, I get an allocation of resources to each part of the network. Of course, if the nominal proportion 

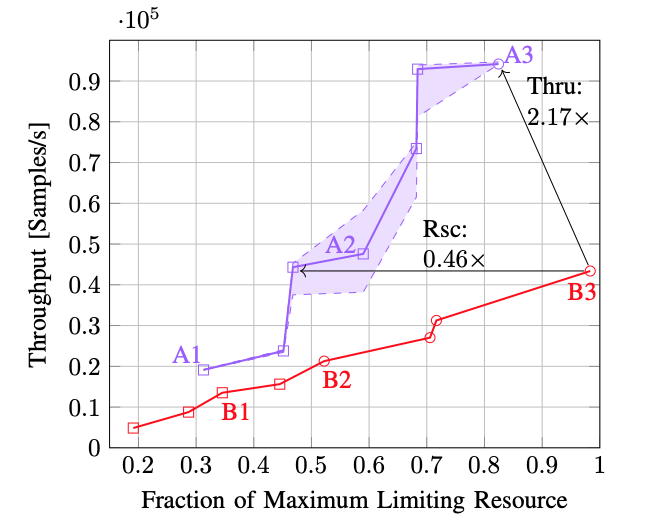
In practice, it turns out that this works really well. The graph below from Ben’s paper shows that on a real example, running on a real FPGA board, he’s able to improve throughput by more than 2x for the same area or reduce area by more than half for the same throughput.
I’m delighted that Ben’s work has been nominated for the best paper prize at FCCM this year and that it has received all three reproducibility badges available: Open Research Objects, Research Objects Reviewed and Results Reproduced, indicating Ben’s commitment to high quality reproducible research in our field.
If you plan to be in Los Angeles next week, come and hear Ben talk about it!
