This summer, I decided to read something about Model Theory. Aware of my limited time, I decided to aim for a slim volume as a guide, so went for An Invitation to Model Theory by Jonathan Kirby.
Here I collect some notes I made while reading Kirby, completely biased to my own interests. Definitions and theorems largely follow the book, but have often been tweaked by me to make my notes more self-contained. I’ve also tried to ‘sloganise’ each of the originally-unnamed theorems in a way that helps me grasp their essence. Additional commentary around the definitions and theorems is mine, and I’ve added a couple of extra definitions to make things easier for me to read back in the future. Of course there is some risk that I’ve introduced errors or lack of clarity, in which case I’m sure the fault lies with me not with the book – please do reach out if you spot anything.
What this post will discuss
We will look at defining basic syntactical objects, terms and formulas, and their interpretations (all in first-order logic). We will look at ideas relating to whether mathematical structures can be distinguished via the truth of formal sentences, including embedding of one structure inside another. We will look at results guaranteeing the existence of structures (especially infinite structures) satisfying sets of such sentences. Turning this around, we’ll also look at some results on which structures can be axiomatised by such sets of sentences. We will consider the extent to which one can define a subset using first-order sentences and the relationship to quantifier elimination (see also my post including algorithms for quantifier elimination). Finally, we will look at the idea of ‘how uniquely’ mathematical structures can be described in this way.
What this post will not discuss
I have purposely not given proofs or examples. Kirby’s book of course has (most) proofs and is rich in examples, through which much of the material is developed. This means I have not discussed some really interesting results on, say, algebraically closed fields, on which Kirby spends considerable time. Those interested in how to apply some of these ideas would do well to consult the book. In addition, I have avoided the topic of types in this simple set of notes, which Kirby highlights as a “central concept in model theory”, despite the interesting results they enable later in the book, e.g. saturated models. The exception is that I included a simplified version of the Ryll-Nardzewski theorem at the end of this post (the proof given uses types) because this particular part of the theorem may be of use to me in the future and can be stated without recourse to types.
I hope to do a later blog post with some of the material using types in due course.
Languages and Structures
Definition (Language). A language  consists of a set of relation symbols, a set of function symbols, a set of constant symbols and, for each relation and function symbol, a positive number known as its arity. The set of all these symbols is denoted
consists of a set of relation symbols, a set of function symbols, a set of constant symbols and, for each relation and function symbol, a positive number known as its arity. The set of all these symbols is denoted 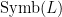 .
.
Definition (–structure). An -structure 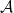 consists of a set
consists of a set  called its domain, together with interpretations of the symbols in : for each relation symbol
called its domain, together with interpretations of the symbols in : for each relation symbol  of arity
of arity  , a subset
, a subset  of
of 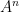 ; for each function symbol
; for each function symbol  of arity , a function
of arity , a function  ; for each constant symbol
; for each constant symbol  , a value
, a value  .
.
Definition (Embedding). Let and  be -structures. An embedding of into is an injection
be -structures. An embedding of into is an injection 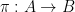 s.t.: for all relation symbols of and all
s.t.: for all relation symbols of and all  ,
, 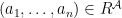 iff
iff 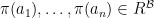 ; for all function symbols of and all ,
; for all function symbols of and all , 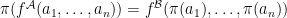 ; for all constant symbols of ,
; for all constant symbols of ,  .
.
Definition (Isomorphism). An embedding  is an isomorphism iff there is an embedding
is an isomorphism iff there is an embedding  s.t.
s.t.  is the identity on and
is the identity on and  is the identity on .
is the identity on .
Definition (Automorphism). An automorphism is an isomorphism from a structure to itself.
Terms, Formulas and their Models
Definition (–term). The set of terms of the language is defined recursively as follows: every variable is a term; every constant symbol of is a term; if is a function symbol of of arity and 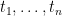 are terms of , then
are terms of , then 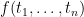 is a term; only something built from the preceding clauses in finitely many steps is a term.
is a term; only something built from the preceding clauses in finitely many steps is a term.
Definition (–formula). The set of formulas of is defined recursively as follows: if  and
and 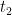 are terms, then
are terms, then  is a formula; if
is a formula; if  are terms and is a relation symbol of of arity , then
are terms and is a relation symbol of of arity , then  is a formula; if
is a formula; if 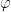 and
and 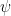 are formulas, then
are formulas, then  and
and 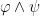 are formulas; if is a formula and
are formulas; if is a formula and  is a variable, then
is a variable, then ![\exists x[\varphi]](https://s0.wp.com/latex.php?latex=%5Cexists+x%5B%5Cvarphi%5D&bg=ffffff&fg=000000&s=0&c=20201002) is a formula; only something built from the preceding four clauses in finitely many steps is a formula. We will write
is a formula; only something built from the preceding four clauses in finitely many steps is a formula. We will write 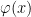 for a formula with free variables
for a formula with free variables 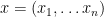 in some defined order.
in some defined order.
Definition (–sentence). An -sentence is a -formula with no free variables.
Definition (Atomic formula). Formulas of the form  for some -terms
for some -terms 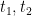 or of the form
or of the form  for some relation symbol and terms
for some relation symbol and terms  are atomic formulas.
are atomic formulas.
Definition (Interpretation of terms). Let be an -structure,  be a term of , and
be a term of , and  be a list of variables including all those appearing in . The interpretation of , written
be a list of variables including all those appearing in . The interpretation of , written  is a function from
is a function from  to defined by: if is a constant symbol then
to defined by: if is a constant symbol then 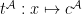 ; if is
; if is  then
then 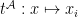 ; if is
; if is 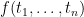 then
then 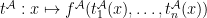 .
.
Definition (Interpretation of formulas). We define  (read
(read 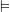 as ‘models’) recursively as:
as ‘models’) recursively as:  iff
iff  ;
; 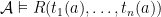 iff
iff 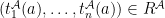 ;
;  iff
iff  ;
; 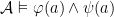 iff
iff 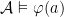 and
and  ;
; ![\mathcal{A} \vDash \exists x[\varphi(x,a)]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BA%7D+%5CvDash+%5Cexists+x%5B%5Cvarphi%28x%2Ca%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) iff there is some
iff there is some  s.t.
s.t.  .
.
Definition (–sentence). An -sentence is a -formula with no free variables.
Definition (Models of sentences). For a sentence , if 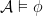 we say is a model of . For a set of sentences
we say is a model of . For a set of sentences  , we say that is a model of (
, we say that is a model of (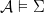 ) iff it is a model of all sentences in .
) iff it is a model of all sentences in .
Definition (Entailment). Let be a set of -sentences and be an -sentence. entails , written  if every model of is also a model of .
if every model of is also a model of .
Note that I am using the notation for entailment used by Kirby’s book, for consistency, but computer scientist readers of my blog will want to note that this symbol is commonly also used for (the more restricted, assuming sound) ‘proves’ relation for a formal deductive system.
Definition (Deductively closed). A set of -sentences is deductively closed iff, for every -sentence  , if
, if 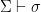 then
then  .
.
(Again note no formal deduction in play here.)
Definition (Satisfiable). A set of sentences is satisfiable iff there exists some -structure such that .
Definition (Complete). A set of -sentences is complete if, for every -sentence , either or  .
.
Definition (Theory). A theory is a satisfiable and deductively closed set of -sentences.
Definition (Theory of a structure). The theory of an -structure , denoted  is the set of all -sentences which are true in .
is the set of all -sentences which are true in .
Elementary Equivalence
It’s clearly interesting to know whether structures can be distinguished by sentences:
Definition (Elementary equivalence). Two -structures and are elementarily equivalent, denoted 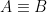 iff for every -sentence ,
iff for every -sentence , 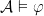 iff
iff 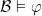 .
.
Compactness
Theorem (Compactness). Let be a set of -sentences. If every finite subset of has a model then has a model.
A huge amount of excitement flows from the compactness theorem, including many of the results that follow.
Proposition (Elementarily-equivalent non-isomorphic structures). Let be any infinite -structure. Then there is another -structure which is elementarily equivalent to but not isomorphic to it.
And so, via this route, we get wonderful non-standard models. As we will see in a moment, via the Löwenheim-Skolem theorems, there are actually many such structures.
Axiomatisable Classes
Definition (Axiomatisable class). If is a set of -sentences then denote by 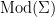 the class of all -structures which are models of . The class is axiomatised by and is and axiomatisable class. The class is finitely axiomatised if it is axiomatised by a finite set of sentences.
the class of all -structures which are models of . The class is axiomatised by and is and axiomatisable class. The class is finitely axiomatised if it is axiomatised by a finite set of sentences.
By compactness, we can’t capture arbitrarily sized, but finite, models (e.g. the class of all finite groups):
Proposition (Large models for axiomatisable classes ensures infinite models). Let  be an axiomatisable class with arbitrarily large finite models (i.e. for every
be an axiomatisable class with arbitrarily large finite models (i.e. for every 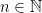 there is a model
there is a model  whose domain is finite and of size at least ). Then also contains an infinite model.
whose domain is finite and of size at least ). Then also contains an infinite model.
If we can finitely axiomatise a class, then if we know we can axiomatise it by some (possibly infinite set of) sentences, then it suffices to choose an appropriate finite subset of those sentences:
Proposition (Finite subsets of sentences axiomatise). If  and is finitely axiomatisable, then it is axiomatised by a finite subset of .
and is finitely axiomatisable, then it is axiomatised by a finite subset of .
Cardinality of Languages
Definition (Language cardinality). We will write  for the cardinality of language , which we define to be the cardinality of the set of all -formulas containing only countably many variables.
for the cardinality of language , which we define to be the cardinality of the set of all -formulas containing only countably many variables.
Unsurprisingly, given this definition, the language cardinality is countable if the set of symbols is countable, otherwise it’s the same cardinality as the set of symbols:
Proposition (Language cardinality).  .
.
Substructures/Extensions and Elementary Substructures/Extensions
Definition (Substructure). Let and be -structures, and suppose  . is a substructure of iff the inclusion of into is an embedding.
. is a substructure of iff the inclusion of into is an embedding.
An example of a substructure would be the naturals as a substructure of the integers, with the language consisting of the 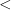 relation and
relation and  ; clearly the inclusion map is an embedding.
; clearly the inclusion map is an embedding.
Lemma (Substructures preserve quantifier-free formulas). If 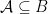 , is a quantifier-free formula and
, is a quantifier-free formula and 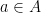 , then iff
, then iff  .
.
Taking the same example, we can see why a stronger notion than substructure is required in order to preserve formulas with quantifiers. For example ![\exists x[ x < 0 ]](https://s0.wp.com/latex.php?latex=%5Cexists+x%5B+x+%3C+0+%5D&bg=ffffff&fg=000000&s=0&c=20201002) clearly has a model in the integers but not in the naturals.
clearly has a model in the integers but not in the naturals.
Definition (Elementary substructure/extension). is an elementary substructure of (and is an elementary extension of , written  , iff and, for each formula and each
, iff and, for each formula and each  , iff .
, iff .
The Tarski-Vaught test is a test for whether a substructure is elementary. The essence of the test is to check whether we can always find an element in the potential substructure that could replace the equivalent element in the superstructure in a formula containing just one variable ranging over the superstructure domain:
Lemma (Tarski-Vaught test). Let 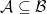 be an -substructure and for every -formula
be an -substructure and for every -formula 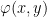 and every
and every  and
and 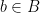 such that
such that  , there is
, there is  such that
such that 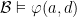 . Then .
. Then .
The Downward Löwenheim-Skolem theorem guarantees the existence of ‘small’ elementary substructures built from the base of an arbitrary subset of the domain of of the elementary extension:
Theorem (Downward Löwenheim-Skolem theorem). Let be an -structure and  . Then there exists an elementary substructure
. Then there exists an elementary substructure  such that
such that  and
and 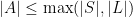 .
.
While the Upward Löwenheim-Skolem theorem gives us a tower of models elementarily extending any infinite model:
Theorem (Upward Löwenheim-Skolem theorem). For any infinite -structure and any cardinal  , there exists an -structure of cardinality equal to
, there exists an -structure of cardinality equal to  such that .
such that .
Definable Sets
Definition (Definable set). In an -structure , a subset  of is said to be a definable set if there is an -formula
of is said to be a definable set if there is an -formula 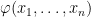 s.t.
s.t.  .
.
One way to show that a set is undefinable is to find an automorphism not preserving the set:
Theorem (Preservation of definability). If  is a definable set and
is a definable set and  is an automorphism of then
is an automorphism of then 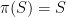 .
.
Notation ( ). We will write
). We will write  for the set of all definable subsets of .
for the set of all definable subsets of .
Quantifier Elimination
Quantifier elimination is a useful way to get a grip on which sets are definable.
Definition (Quantifier elimination for structures). An -structure has quantifier elimination iff for every  , every definable subset of is defined by a quantifier-free -formula.
, every definable subset of is defined by a quantifier-free -formula.
Definition (Quantifier elimination for theories). An -theory  has quantifier elimination iff for every , for every -formula
has quantifier elimination iff for every , for every -formula  , there is a quantifier-free -formula
, there is a quantifier-free -formula  such that
such that ![T \vdash \forall x [\varphi(x) \leftrightarrow \theta(x)]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cforall+x+%5B%5Cvarphi%28x%29+%5Cleftrightarrow+%5Ctheta%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
These semantic and syntactic views line up:
Lemma (Structures and their theories are equivalent w.r.t. quantifier elimination). Let be an -structure. Then has quantifier elimination iff has quantifier elimination.
Substructure Completeness
One way to show that a theory has quantifier elimination is via substructure completeness, a weaker notion than completeness.
Notation ( ). Given an -structure , define a new language
). Given an -structure , define a new language  by adding a new distinct constant symbol
by adding a new distinct constant symbol  for every . is the -structure obtained by interpreting each constant symbol as
for every . is the -structure obtained by interpreting each constant symbol as  , with all other interpretations remaining as in .
, with all other interpretations remaining as in .
Definition (Diagram). The diagram  of a -structure is the set of all atomic -sentences and negations of atomic -sentences which are true in .
of a -structure is the set of all atomic -sentences and negations of atomic -sentences which are true in .
Definition (Substructure complete). A -theory is substructure complete if, whenever is a substructure of a model of , the theory  is a complete -theory.
is a complete -theory.
Proposition (Substructure completeness is equivalent to quantifier elimination). Let be a -theory. Then is substructure complete iff has quantifier elimination.
Principal Formulas
Notation. Given an -structure and an -formula with free variables, we will write  for
for 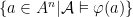 .
.
Definition (Principal formula). Let be a complete -theory. A principal formula w.r.t. is a formula 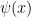 such that: (i)
such that: (i) ![T \vdash \exists x [\psi(x)]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cexists+x+%5B%5Cpsi%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) , (ii) for every -formula with the same tuple of free variables, either
, (ii) for every -formula with the same tuple of free variables, either ![T \vdash \forall x[ \psi(x) \to \varphi(x) ]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cforall+x%5B+%5Cpsi%28x%29+%5Cto+%5Cvarphi%28x%29+%5D&bg=ffffff&fg=000000&s=0&c=20201002) or
or ![T \vdash \forall x[ \psi(x) \to \neg \varphi(x)]](https://s0.wp.com/latex.php?latex=T+%5Cvdash+%5Cforall+x%5B+%5Cpsi%28x%29+%5Cto+%5Cneg+%5Cvarphi%28x%29%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Another way to get a good handle on the definable sets of a -structure is via their principal formulas, especially if there are only finitely many.
Proposition (Definable sets from principal formulas). Let 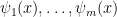 be principal formulas in variables for the (complete) theory , defining distinct subsets of . Also let these formulas cover , i.e.
be principal formulas in variables for the (complete) theory , defining distinct subsets of . Also let these formulas cover , i.e.  . Then every definable set in is a union of some of the sets
. Then every definable set in is a union of some of the sets  , and
, and 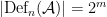 .
.
Categoricity
Bearing in mind the upward and downward Löwenheim-Skolem theorems, what’s the appropriate definition of a model that’s ‘effectively defined’ by a theory?
Definition (Categorical). A theory is -categorical iff there is a model of of cardinality and any two models of cardinality are isomorphic.
It turns out that categoricity can give us completeness:
Lemma (Łos-Vaught test). If an -theory is -categorical for some  and has no finite models, then is complete.
and has no finite models, then is complete.
How do we know whether a theory is categorical? We have a a special case for countably categorical (i.e.  -categorical) theories. It turns out that countably categorical complete theories are exactly those whose models have only finitely many definable subsets for each fixed dimension:
-categorical) theories. It turns out that countably categorical complete theories are exactly those whose models have only finitely many definable subsets for each fixed dimension:
Theorem (Ryll-Nardzewski theorem). Let be a complete -theory with an infinite model and with countable. Then is countably categorical iff for all  , is finite.
, is finite.
(Note to reader: the version of this theorem presented in Kirby instead links countable categoricity to the finiteness of Lindenbaum algebras, which I have avoided discussing in this blog post. But Lindenbaum algebras are isomorphic to algebras of definable sets for complete theories (see Kirby Lemma 20.3), so I have stated as above here. I have also eliminated elements of the full theorem presented, to make the presentation here self-contained.)
So how about the book? Would I recommend it to others?
From my perspective as an “informed outsider” to model theory, Kirby’s book was accessible. It’s brief – as the title says, it’s an invitation to model theory – and I think it does that job well. If you’re comfortable (or indeed enjoy) seeing material presented in a variety of ways, sometimes through example that generalises later in the book, sometimes through application, sometimes in its general form first, then you will probably enjoy the presentation – as I did. I felt the book falls a little short of a self-study guide, though, primarily because it doesn’t include worked answers to any of the exercises; this would be a welcome addition. This point is particularly relevant to Chapter 16, which (unlike other chapters in the book) takes the form of a ‘guided exercise’ to applying the ideas of the preceding chapters to the study of a particular structure.
Overall, I would definitely recommend to other outsiders wanting to catch a glimpse of what Model Theory is all about.



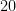
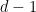




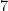
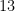
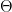 .
. . Thus we obtain
. Thus we obtain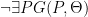 .
.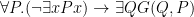 .
.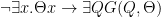 via universal instantiation. Then using Premise 1 and modus tollens, one obtains
via universal instantiation. Then using Premise 1 and modus tollens, one obtains 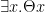 .
.  to denote the interpretation of a formula
to denote the interpretation of a formula  in a model, and I will use
in a model, and I will use  to denote the false predicate, i.e.
to denote the false predicate, i.e.  is false for all
is false for all 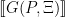 true for any predicate
true for any predicate  with different interpretation to
with different interpretation to  false for all other predicate pairs, and (M3)
false for all other predicate pairs, and (M3)  true for all
true for all  from
from  onto a specific relation on
onto a specific relation on  . Then the relation in question is
. Then the relation in question is  . We also require
. We also require 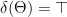 and
and  . Another way of saying this is that any relation
. Another way of saying this is that any relation  .
. , assume the antecedent
, assume the antecedent  . Then the third conjunct enforces
. Then the third conjunct enforces  , which directly contradicts the second conjunct.
, which directly contradicts the second conjunct.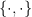 to denote a function taking two bit vectors and concatenating them together. Of course the ‘multiplication by 10 is easy’ becomes ‘multiplication by 2 is easy’ in binary. Putting this together, we can write
to denote a function taking two bit vectors and concatenating them together. Of course the ‘multiplication by 10 is easy’ becomes ‘multiplication by 2 is easy’ in binary. Putting this together, we can write 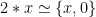 , meaning that multiplication by two is the same as concatenation with a zero. But what does ‘the same as’ actually mean here? Clearly they are not the same expression syntactically and one is cheap to compute whereas one is expensive. What we mean is that no matter which value of
, meaning that multiplication by two is the same as concatenation with a zero. But what does ‘the same as’ actually mean here? Clearly they are not the same expression syntactically and one is cheap to compute whereas one is expensive. What we mean is that no matter which value of  rather than
rather than  .
. 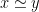 then it necessarily follows that
then it necessarily follows that  for every function symbol
for every function symbol 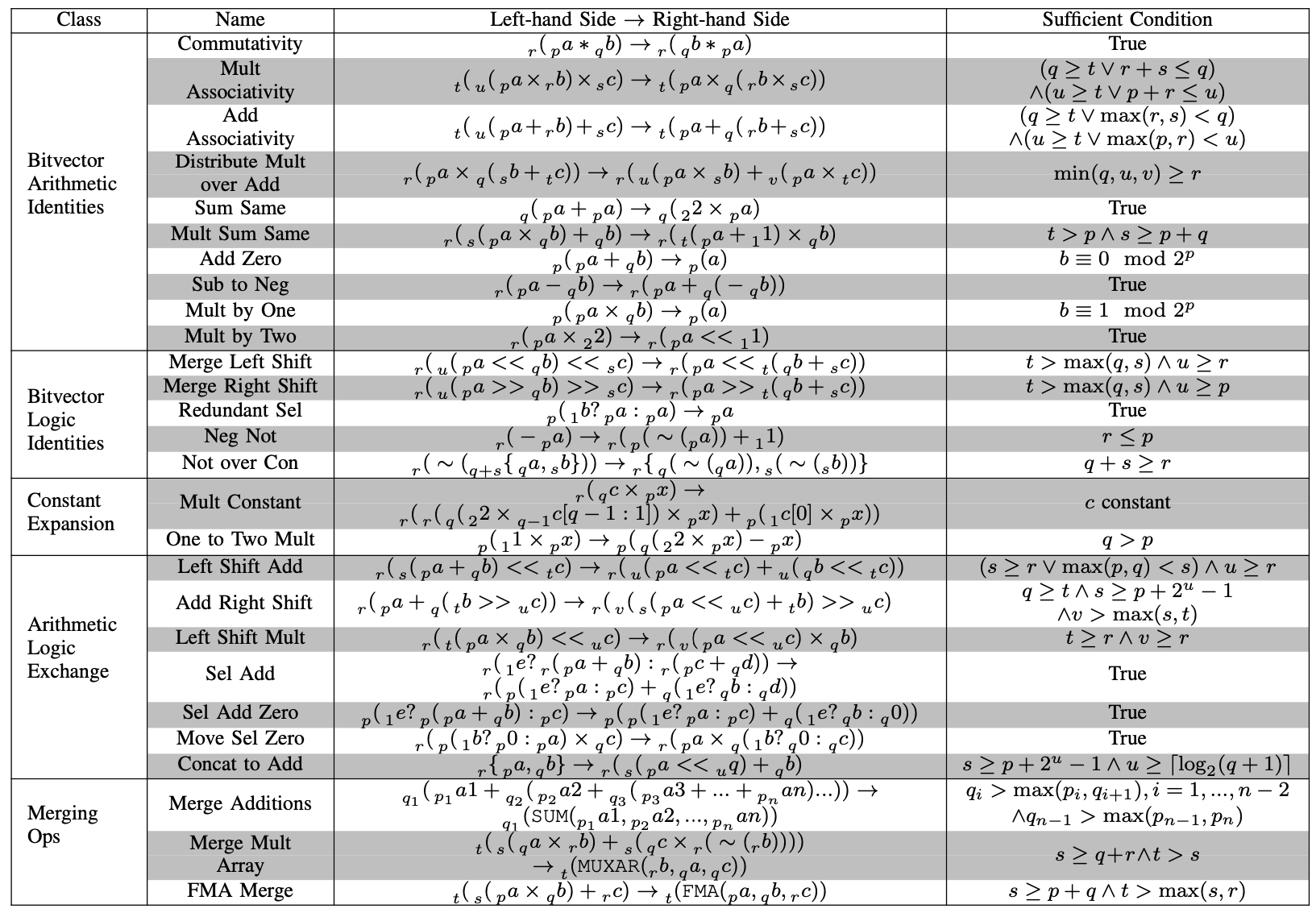
 then I wouldn’t bother to calculate
then I wouldn’t bother to calculate 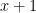 twice. We describe in our paper how we address this problem via an optimisation formulation. Our tool solves this optimisation and produces synthesisable Verilog code for the resulting circuit.
twice. We describe in our paper how we address this problem via an optimisation formulation. Our tool solves this optimisation and produces synthesisable Verilog code for the resulting circuit.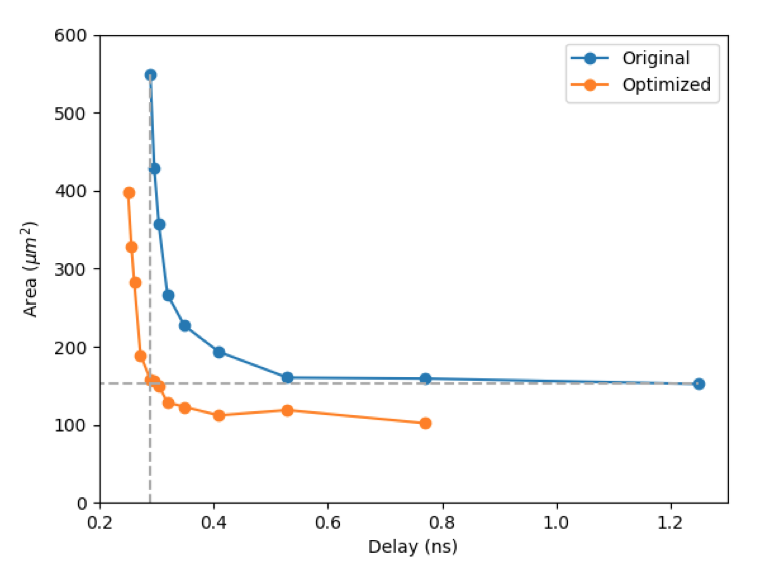

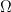 and
and  are used.
are used. 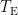
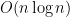





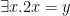 ). However, adding an additional countable set of predicates capturing divisibility (one per divisor) together with an appropriate axiom leads to a version admitting quantifier elimination as per this table.
). However, adding an additional countable set of predicates capturing divisibility (one per divisor) together with an appropriate axiom leads to a version admitting quantifier elimination as per this table.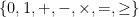 (with
(with  unary) and axioms corresponding to those of a
unary) and axioms corresponding to those of a 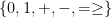 (again with
(again with 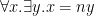 for every positive integer
for every positive integer ![\{\cdot[\cdot], \cdot\langle\cdot\vartriangleleft\cdot\rangle, =\}](https://s0.wp.com/latex.php?latex=%5C%7B%5Ccdot%5B%5Ccdot%5D%2C+%5Ccdot%5Clangle%5Ccdot%5Cvartriangleleft%5Ccdot%5Crangle%2C+%3D%5C%7D&bg=ffffff&fg=000000&s=0&c=20201002) , with the first two symbols denoting a binary and ternary function (respectively) for accessing and modifying array elements; arrays are
, with the first two symbols denoting a binary and ternary function (respectively) for accessing and modifying array elements; arrays are