
Robert Chapman, a neurodivergent philosopher, published this book, “Empire of Normality: Neurodiversity and Capitalism“, in 2023. I have been reading this thought-provoking book over the last few weeks, and have a few comments.
A Historical Materialist Approach
The general thesis of Chapman’s book, as I understand it, is that the very concept of “normal human functioning” is intimately bound up with – and emerged from – the economic demands of capitalism. Their book takes the reader on a really interesting journey from ancient to modern views of disease and abnormality, taking in the rise and fall of eugenics, the anti-psychiatry movement and its cooption by neoliberal policymakers, Fordism and post-Fordist production and their impact on mental health, the rise of the neurodiversity movement, and Chapman’s views on neurodiversity and liberation. The book aims to take a historical materialist approach to these questions, emphasising the importance of material economic conditions throughout. I learnt a lot about the history of mental illness, disability, and neurodiversity.
Chapman makes the argument that modern capitalism is harmful to neurotypical and neurodivergent alike, with neurotypical workers facing extreme forms of alienation while neurodivergent potential-workers are often consigned to a “surplus class”. This term appears to be used to denote the idea that such people form a group which can be called on to re-enter the workforce during times of economic growth, akin to the traditional unemployed, but the mechanisms for this to actually happen are not fully drawn out. I’m familiar with the classical concept of a “reserve army of labour”, but not of “surplus class”; late in the book, Chapman cites Adler-Bolton and Vierkant for this concept.
Bodies as Machines, Measurement & Pathology
The metaphor of the body as a machine, and of both neurodiversity and mental illness as corresponding to “broken machines” is criticised heavily throughout the book. Yet I think the metaphor appears to be used in two ways by Chapman, one being machine meaning deterministic device which can be repaired or enhanced with appropriate technical skill, and a different one – machine as a mass-produced device with interchangeable parts and interfaces to the outside world. It is not always clear to me which Chapman is criticising, and I think sometimes arguments against the first view are used rhetorically to support arguments against the second.
There’s a very detailed and interesting discussion on the history of measurement and its link to identifying outlying individuals. What’s less well developed, in my view, is a clear understanding of the potential of clustering of certain traits. To my mind, labels like ADHD have meaning precisely because they define one or more clusters of observable phenomena. These clusters may themselves be very far from the mean, yet identifying such clusters as clusters, rather than as isolated atypical individuals can clearly be helpful. This point arises also much later in the book, where Chapman refers to “autistic customs”, when describing the rise of the neurodiversity movement; the very idea of “customs” seems to only apply to groups of individuals, so this focus on clustering rather than on individuals seems essential to any argument made on this basis, rather than solely around the need to accommodate each unique individual. A reference is made late in the book to Sartre’s notion of ‘serial collectives’, which may hold out a basis for further analysis of this point. “Far from the mean” is also often taken implicitly to correspond to “far below the mean”, and I think the explicit thesis of “the mean is ideal”, explicitly linked to middle-class values by Chapman, is missing a fleshed out discussion of where this leaves “far above the mean” in terms of valuation.
The “pathology paradigm” is introduced as a set of assumptions: that mental and cognitive functioning are individual (whereas, as Chapman convincingly argues, there is a clear social element), that they are based on natural abilities, and that they can be totally ordered (or, as Chapman states it, ‘ranked in ration to a statistical norm across the species’).
Chapman does an excellent job in explaining how modern production leads to separation and sorting by neurotype. The claim made that “increasingly, new forms of domination have less to do with social class, which now, to an extent, is more fluid than in the 19th century, and much more to do with where each of us falls on the new cognitive hierarchies of capitalism” seems weaker if – by domination – it is intended to mean that the separation is self-reinforcing, akin to the traditional Marxist view of capital accumulation. This conclusion is hinted at, but I don’t think the case is strongly made – nor am I sure it is correct.
Chapman’s Marxian argument is strong when utilising the concept of alienation in the “post-Fordist” service economies to argue that some traits that were typically relatively benign became associated with disablement as a result of this economic shift. What is less clear to me is whether the same could be said the other way round: are there traits we can identify that were disabling under a “Fordist” economy but are now relatively benign? I hear elsewhere, for example, much said about shift to home-working benefiting some autistic workers significantly, especially in the software engineering industries. Their linking of disability to capitalism’s historical growth is clear and well argued, though weaker I felt when looking to the future. For example, it is stated that “capitalist logics both produce and require disablement”; here I am unsure whether “require” is meant in the sense of directly flowing from commodification of labour or in the sense of requiring a disabled “surplus class”. I think the argument for the former appears much stronger. Similarly the term “physician class” is used at several points in the text, and I am not completely sure how physicians would constitute a class per se.
I found the discussion of the rise, and revision, of the Diagnostic and Statistical Manual of Mental Disorders (DSM) fascinating, especially the arguments for including – and then removing – homosexuality from the manual (it appeared in DSM-I and DSM-II but was eliminated under DSM-III) on the basis that it did not meet the new criterion that “the disturbance is not only in the relationship between the individual and society”. I also did not know that, according to Chapman, some 25% of the UK population has been prescribed psychotropic medication – a statistic I find extraordinary.
Some Thoughts to be Developed
I think that there is plenty that could be said about what I would describe as the scalarisation of value through the one-dimensional lens of price and how this potentially moves to limit and devalue variety, not only in neurotype but across political economy. The point hinted at here, via ideas around the commodification of labour, but perhaps Chapman or others could be convinced to develop it further.
Given my background in school governance, I was struck by the commentary around differences in development in comparison to one’s age group becoming increasingly salient during the Fordist period. There is, I suspect, a lot more to say also about the shift to ‘teaching-to-the-age’ in the education world, rather than ‘teaching-to-the-individual’, a trend that was in England markedly accelerated by the 2014 national curriculum.
I feel like I need to read more about behaviourism. As someone who has studied the behaviour of dynamical systems, there is a difference between the philosophical approach Chapman ascribes to Watson, “science should focus only on what can objectively be observed”, which strikes me as a call to extensionality, and the conclusions claimed to follow (whether the inference is by Watson or by Chapman, I am not clear due to my ignorance of the field), that behaviour can be usefully directly controlled (e.g. via Applied Behaviour Analysis, an approach with a very bad reputation in the autistic community). The first claim can hold without the second having any validity, in the presence of stateful behaviour.
Looking to the Future
In contrast to the history of neurodiversity, the history of the Soviet Union Chapman provides is weak and doesn’t really seem to follow the materialist approach set out in the earlier subject matter in the book. We are told that not being career politicians contributed to the Bolshevik failure. While much space is given to the ‘state capitalist’ nature of the early Soviet state, the almost absolutely discontinuity between that state and the Stalinist bureaucracy is not discussed, rather we are told that Stalin “gave up on shifting beyond state capitalism [and] simply declared that communism had been achieved”. The idea that Stalin inherited the post-revolutionary state whole seems very odd, and I am also pretty sure he never proclaimed that (full) communism had been achieved.
The arguments Chapman makes for liberation I find less convincing than their materialist analysis of the emergence of neurodiversity as a form of disablement. In particular, there appears to me to be a jump from the well argued case that capitalism brings about groups of disadvantaged neurodiverse, to the less well argued case that such groups can form agents of change by organising in those groups – as Chapman puts it, “neurodivergent workers organising as neurodivergents” and to “empower the surplus as surplus”. Despite the materialist approach taken to historical analysis of neurodiversity and disability, this materialism appears somewhat missing from the calls to “turn[…] everyday comportment and behaviour into forms of resistance” or the statement that “we [disabled] have collective cognitive power … that could be harnessed no less than the collective power of the working class”, or that envisioning the future requires “mass consciousness-raising, critique, and collective imagining”.
Overall
Despite my gripes above, I would recommend this book. I learnt a lot of history, and I think it’s great to see this being approached from a materialist perspective. I also get the sense of Chapman, a neurodivergent philosopher, being determined to live their philosophy, and this is definitely to be celebrated in my book.
 for its inputs
for its inputs  and some learned weight vector
and some learned weight vector 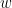 and bias
and bias  , where
, where  is typically a fixed nonlinear function such as a
is typically a fixed nonlinear function such as a  . The Xilinx team noted that if they restrict the length of the vector
. The Xilinx team noted that if they restrict the length of the vector  . In this way, we can tune a knob: turn down to
. In this way, we can tune a knob: turn down to  for minimal expressivity but the smallest number of parameters to train, and recover LogicNets as a special case; turn up
for minimal expressivity but the smallest number of parameters to train, and recover LogicNets as a special case; turn up 
 together with
together with  elements,
elements,  , for
, for  . The numbers represented are (except special values),
. The numbers represented are (except special values),  . This is a very flexible starting point, which is to be welcomed, and there is much to explore under this general hood. In all the examples given, the scalar data types are either floating point or integer/fixed point, but there seems to be nothing in the specification specifically barring other representations, which could of course go far beyond traditional block floating point and more recent block exponent biases.
. This is a very flexible starting point, which is to be welcomed, and there is much to explore under this general hood. In all the examples given, the scalar data types are either floating point or integer/fixed point, but there seems to be nothing in the specification specifically barring other representations, which could of course go far beyond traditional block floating point and more recent block exponent biases.
 denotes the
denotes the  th element of vector
th element of vector  ,
,  denotes the scaling of
denotes the scaling of  (on elements), the (elided) product on scalings and the sum on element products is undefined. The intention, of course, is that we want the dot product to approximate a real dot product, in the sense that
(on elements), the (elided) product on scalings and the sum on element products is undefined. The intention, of course, is that we want the dot product to approximate a real dot product, in the sense that 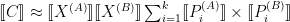 , where the semantic brackets correspond to interpretation in the base scalar types and arithmetic operations are over the reals. But the nature of approximation is left unstated. Note, in particular, that it is not a form of round-to-nearest defined on MX, as hinted at by the statement “The internal precision of the dot product and order of operations is implementation-defined.” This at least suggests that there’s an assumed implementation of the multi-operand summation via two-input additions executed in some (identical?) internal precision in some defined order, though this is a very specific – and rather restrictive – way of performing multi-operand addition in hardware. There’s nothing wrong with having this undefined, of course, but an MX-compliant dot product would need to have a very clear statement of its approximation properties – perhaps something that can be considered for the standard in due course.
, where the semantic brackets correspond to interpretation in the base scalar types and arithmetic operations are over the reals. But the nature of approximation is left unstated. Note, in particular, that it is not a form of round-to-nearest defined on MX, as hinted at by the statement “The internal precision of the dot product and order of operations is implementation-defined.” This at least suggests that there’s an assumed implementation of the multi-operand summation via two-input additions executed in some (identical?) internal precision in some defined order, though this is a very specific – and rather restrictive – way of performing multi-operand addition in hardware. There’s nothing wrong with having this undefined, of course, but an MX-compliant dot product would need to have a very clear statement of its approximation properties – perhaps something that can be considered for the standard in due course.
 and
and  are the
are the  th MX-compliant subvector of
th MX-compliant subvector of  .” Like in the “Dot” definition, the summation notation is also not defined in the specification, and also this definition doesn’t carry the same wording as for “Dot” on internal precision and order, but I am assuming it is intended to. It is left undefined how to form component subvectors. I am assuming that the authors envisaged the vector
.” Like in the “Dot” definition, the summation notation is also not defined in the specification, and also this definition doesn’t carry the same wording as for “Dot” on internal precision and order, but I am assuming it is intended to. It is left undefined how to form component subvectors. I am assuming that the authors envisaged the vector  and
and  are the extracted “close” expressions.
are the extracted “close” expressions.
 can just be replaced by
can just be replaced by  , e.g.
, e.g.  . But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g.
. But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g.  , where I am using math script to denote the value of a variable and teletype script to denote an expression.
, where I am using math script to denote the value of a variable and teletype script to denote an expression. . Now let’s imagine introducing a new operator
. Now let’s imagine introducing a new operator  that takes two expressions, the second of which is interpreted as a Boolean. Let’s give
that takes two expressions, the second of which is interpreted as a Boolean. Let’s give  . In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as
. In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as  . These
. These ![x \in [-1,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , then a classical evaluation of
, then a classical evaluation of  would give me
would give me ![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=ffffff&fg=000000&s=0&c=20201002) , due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite
, due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite  would likely fire, resulting in zero residing in the same e-class as
would likely fire, resulting in zero residing in the same e-class as  . Since the interval associated with
. Since the interval associated with  is
is ![[0,0]](https://s0.wp.com/latex.php?latex=%5B0%2C0%5D&bg=ffffff&fg=000000&s=0&c=20201002) , the same interval will automatically be associated with
, the same interval will automatically be associated with 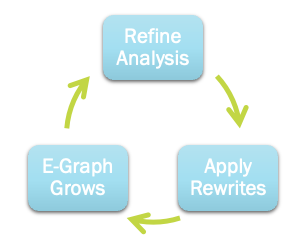

 of ‘hard’ samples I used to characterise the network varies in practice from the actual proportion
of ‘hard’ samples I used to characterise the network varies in practice from the actual proportion  , then I may end up with a somewhat different behaviour, as indicated by the purple region.
, then I may end up with a somewhat different behaviour, as indicated by the purple region.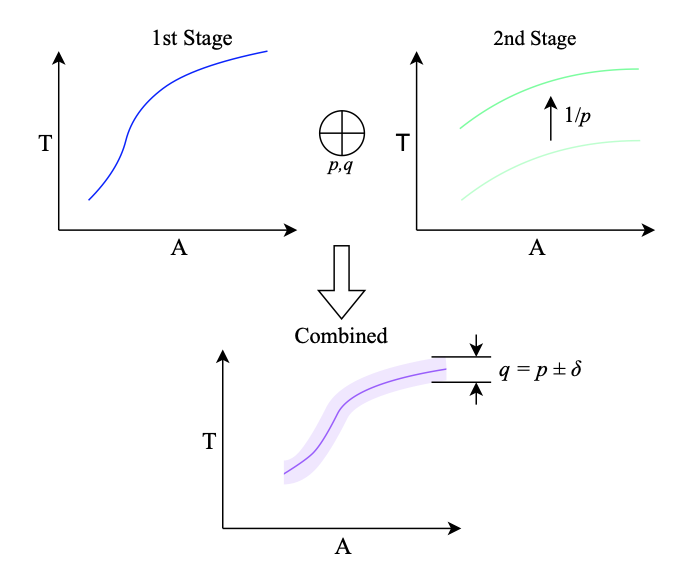
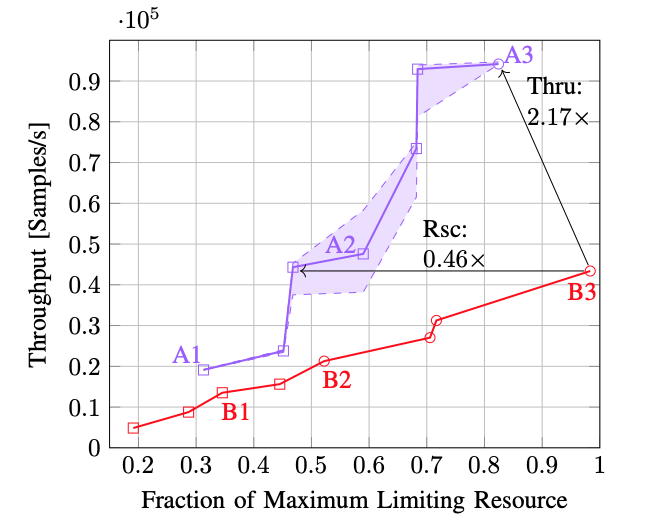

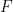 , and if from the proposition that
, and if from the proposition that  falls under the concept
falls under the concept  . Then I read Frege’s definition as:
. Then I read Frege’s definition as: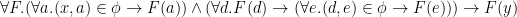
 in the code) indeed (i) contains
in the code) indeed (i) contains 


