Last week I was in Paris attending POPL 2017 and co-located events such as VMCAI. This was my first time at POPL, prompted by acceptance of work with John Wickerson. Here are some highlights and observations from my own, biased, position as an outsider to the programming languages community.
Polyhedral analysis
Due to my prior work with linear programming and polyhedral analysis, the polyhedral talks were particularly interesting to me.
Maréchal presented an approach to condense polyhedral representations through ray tracing, which seems to be of general interest.
While in general, polyhedral methods represent some set as 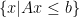


Singh, Püschel, and Vechev presented an interesting method to speed up polyhedral abstract domain computations by partitioning, resulting in a much faster tool.
SMT Solvers
An interesting paper from Jovanović presented a nonlinear integer arithmetic solver which looks genuinely very useful for a broad class of applications.
Heroics with Theorem Provers
Lots of work was presented making use of Coq, some of which seemed fairly heroic to me. Of particular interest, given my work on non-negative polynomials for bounding roundoff error, was a Coq tactic from Martin-Dorel and Roux that allows the use of (necessarily approximate) floating-point computation in ways I’ve not seen before, essentially writing a sum-of-squares polynomial 

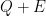
Weak Memory
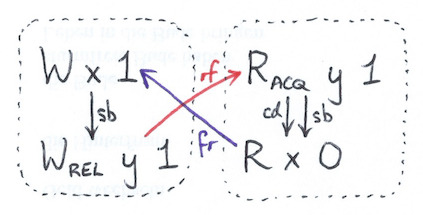
John presented our work on automatically comparing memory models, which seemed to be well received.

Numerics
Chiang et al. presented a paper on rigorous floating-point precision tuning. The idea is simple, but elegant: perform error analysis with individual precisions as symbolic variables and then use a global optimization solver to look for a high-performance implementation. Back in 2001, I did a very similar thing but for a very limited class of algorithm (LTI systems) in fixed-point rather than floating-point and using noise power rather than worst-case instantaneous error as the metric of accuracy. However, the general setting (individual precisions, an explicit optimization) are there, and it is great to see this kind of work now appearing in a very different context.
Cost Analysis
There were a couple of papers [Madhavan et al., Hoffmann et al.] I found particularly interesting on automated cost analysis.
Community differences
As an outsider, I had the opportunity to ponder some interesting cultural differences from which the various research communities I’m involved with could potentially learn.
Mentoring: One of the co-located workshops was PLMW, the Programming Languages Mentoring Workshop. This had talks ranging from “Time management, family, and quality of life” to “Machine learning and programming languages”. Introductory material is mixed with explicitly nontechnical content valuable to early career researchers. Co-locating with the major conference of the field, I would imagine makes it relatively easy to pull in very high quality speakers.
Reproducibility: POPL, amongst other CS conferences, encourages the submission of artifacts. I am a fan of this process. While it doesn’t quite hit the holy grail of research reproducibility, it takes a definite step in this direction.
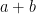 in floating-point arithmetic. Under
in floating-point arithmetic. Under  where
where  is bounded by a constant determined only by the precision of the arithmetic involved. The same goes for any other fundamental operator *, /, etc. Now imagine chaining a whole load of these operations together to get a computation. For straight-line code consisting only of addition and multiplication operators, the result will be polynomial in all your input variables as well as in these error variables
is bounded by a constant determined only by the precision of the arithmetic involved. The same goes for any other fundamental operator *, /, etc. Now imagine chaining a whole load of these operations together to get a computation. For straight-line code consisting only of addition and multiplication operators, the result will be polynomial in all your input variables as well as in these error variables  .
.

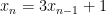 , a multiply and an add must be performed before executing the next iteration. But transforming this to
, a multiply and an add must be performed before executing the next iteration. But transforming this to  gives much more time to execute. Combining this with expression balancing, etc., leads to a wide variety of possible implementations, which our tool can explore automatically while also proving the numerical properties of the transformed code. This latter point makes it quite unlike so-called “unsafe” optimisations commonly used in compilers such as
gives much more time to execute. Combining this with expression balancing, etc., leads to a wide variety of possible implementations, which our tool can explore automatically while also proving the numerical properties of the transformed code. This latter point makes it quite unlike so-called “unsafe” optimisations commonly used in compilers such as 