This is the third post in a sequence relating to the geometry of block number formats as angle preservers. In my previous post, I argued that block number formats remain direction preservers even when their block scales are quantised all the way down to powers of two, as is common in some number representations like the MX concrete formats. The main result there was that exponent-only block scaling perturbs direction by at most about 
But that doesn’t mean power-of-two scaling is optimal. If we have a fixed budget of bits for representing block scales, how should we spend them? Specifically, should we spend them on exponent range, or on significand precision?
This post argues that the answer becomes much clearer once a high-precision tensor-wide scale is introduced, which is exactly the kind of two-level scaling used in NVIDIA’s NVFP4 format. In NVFP4, 4-bit E2M1 values are combined with an FP8 E4M3 scale for each 16-value micro-block and a second-level FP32 scale for the tensor.
With such a tensor-wide scale, the block scales are relieved of their duty to try to capture the global magnitude of the tensor. Instead, we can ask a more focused task of them: reconstruct the relative amplitudes of the blocks, so that the global direction of the represented vector is preserved.
Since drafting this post, Bardia Zadeh and I have also written Direction-Preserving Number Representations, which I blogged about separately. That paper studies the related question of what directions can be obtained when each coordinate of a vector is drawn from a finite scalar alphabet. This post is about block scales rather than scalar elements, but the same product-structured geometry reappears one level higher.
I will argue in this post that once we look at the problem that way, precision in the block scales starts to matter much more. This leads to a rough rule of thumb for the relationship between block scale formats and vector lengths.
What a tensor-wide scale changes
Suppose, as per my previous posts, that each block is represented as 


Now suppose that the final represented tensor has the form

where
is the high-precision tensor-wide scale,
is the low-precision per-block scale, and
denotes direct sum (block concatenation).
Of course, the tensor-wide scale
In other words, once a tensor-wide scale is present, the block scales stop answering the question “how large is this tensor?” and instead answer the question “how do the blocks compare with one another?”
Exact scale-only cosine factor
Let 

Write

Then the represented block is simply

So scale quantisation does not change any chosen block direction, it only rescales the ideal projected blocks.
Define

so that 

Then, exactly as in the previous post, we have

This says that directional distortion from block-scale quantisation depends only on how uneven the multiplicative scale errors 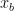
If all blocks were rescaled by the same factor, direction would be unchanged.
Two jobs for two different kinds of bits
A block-scale format does two things.
First, its exponent bits determine what range of relative block scales can be represented without clipping or underflow.
Second, its significand bits determine how accurately the in-range scales are represented.
So there are really two error sources:
- tail loss, from blocks whose scales fall outside range;
- in-range uneven rescaling, from finite precision within range.
The interesting question is how these trade off when the total number of scale bits is fixed.
A conservative scale-only view for fixed 
Suppose the tensor is divided into
If we want a format-level guarantee, a natural scale-only question is:
for a given number of blocks
I am deliberately saying “scale-only” here because this is not a claim about the globally optimal scalar alphabet (a problem Bardia and I cover in our preprint, linked to above), nor about the full problem of choosing the mantissa vectors. It is a conservative model of the additional angular error introduced after the block directions have already been chosen.
To make this concrete, let
be the number of exponent bits,
be the significand precision in bits, and
be the total scale-field width.
Now make one simplifying assumption: the mantissa vectors used in different blocks all have the same norm. Under that assumption, projected block energy is proportional to the square of the ideal block scale. This lets us reason directly in terms of the block scales themselves.
If the exponent field is too narrow, then very small relative block scales may underflow to zero after tensor-wide normalisation. In the worst case, one block survives at unit scale and the remaining 
If the smallest representable normalised scale is 

Here 
If, on the other hand, the surviving blocks remain in range but the scale precision is limited, then the remaining error comes from uneven in-range rescaling. Suppose the multiplicative scale errors for the surviving blocks satisfy

Then the interval argument from the previous post gives

In the common symmetric relative-error model, 


Putting the clipping and in-range effects together gives the conservative scale-only bound

In the symmetric relative-error model, this simplifies to

This is the key scale-only design inequality.
What this says about exponent bits
The first striking feature is that exponent bits only need to control the low-energy tail.
To make clipping negligible, it is enough to ensure that

Now the dynamic range of a floating-point-like scale grows extremely quickly with exponent width. A format-dependent way to write this is

where 
Substituting into the clipping condition gives

Solving this roughly gives

The important point is the growth law. The number of exponent bits needed to control relative-tail clipping grows only like 
That is a very slow growth law: once
What this says about significand bits
Once clipping is under control, the remaining scale error is dominated by in-range relative precision. That is the role of the significand.
In the symmetric relative-error model, the scale-only cosine contribution is
Equivalently, the angular contribution is at most

If a

where 


Equivalently,

So once the exponent field is “good enough”, every additional scale bit is more profitably spent on significand precision than on more dynamic range. This is the central conclusion of the scale-only model.
A simple rule of thumb
The previous discussion suggests the following design rule.
Use just enough exponent bits to make clipping of important blocks negligible. Spend the rest on significand precision.
For a tensor with 

Here 
exponent bits become sufficient very quickly; significand bits keep helping.
What this means for modern designs
This way of looking at the problem helps explain why a format that combines
- a high-precision tensor-wide scale, and
- a more precise block-scale format
looks like a very sensible design.
The tensor-wide scale deals with global magnitude. That leaves the block scales free to focus on preserving the relative block amplitudes that determine global direction.
This is exactly the tradeoff that makes NVFP4 interesting. Compared with exponent-only scaling, E4M3 block scales spend some representational power on non-power-of-two precision. The second-level FP32 tensor scale then compensates for the reduced range of the more precise E4M3 block-scale format.
There is also a useful connection with Bardia’s preprint. That paper studies the scalar alphabet inside a block, and finds that for 4-bit alphabets at the NVFP4 micro-block dimension 
So the two messages reinforce one another:
- inside a micro-block, E2M1 is a surprisingly good product-structured scalar alphabet for direction preservation;
- across micro-blocks, a tensor-wide scale makes the relative block-scale problem more important, so non-power-of-two block-scale precision becomes valuable.
From the perspective of directional reconstruction, that seems like a very good bargain.
Conclusion
The previous post showed that even exponent-only block scaling preserves direction surprisingly well.
This post goes a step further. Once a tensor-wide high-precision scale is available, the main question is no longer whether coarse block scaling is robust enough. Instead, we should ask whether the block scales are making the best possible use of their bits.
From the point of view of reconstructing global direction,
- exponent bits protect against clipping of low-energy tail blocks;
- significand bits improve the relative amplitudes of all the important in-range blocks.
Since exponent range grows very quickly with exponent width, only a modest number of exponent bits is needed before clipping becomes a secondary issue. After that, precision matters more.
This is a scale-only argument. It assumes the block directions have already been chosen, and studies the additional directional error caused by quantising the relative block amplitudes.
Proof sketch of the conservative scale-only bound
Readers not interested in the algebra can safely skip this section.
Assume equal mantissa norms across blocks, so that ideal projected block energy is proportional to the square of the ideal block scale.
Let
First, let 

so

Second, form the final represented vector

then the interval bound from the previous post gives
In the symmetric relative-error model,
Now write 



Therefore
In the symmetric relative-error model, this is
 . For example,
. For example,  , then the unscaled vectors we can represent are the product set
, then the unscaled vectors we can represent are the product set 


 , how close is the nearest direction obtainable from the alphabet
, how close is the nearest direction obtainable from the alphabet  is better.
is better.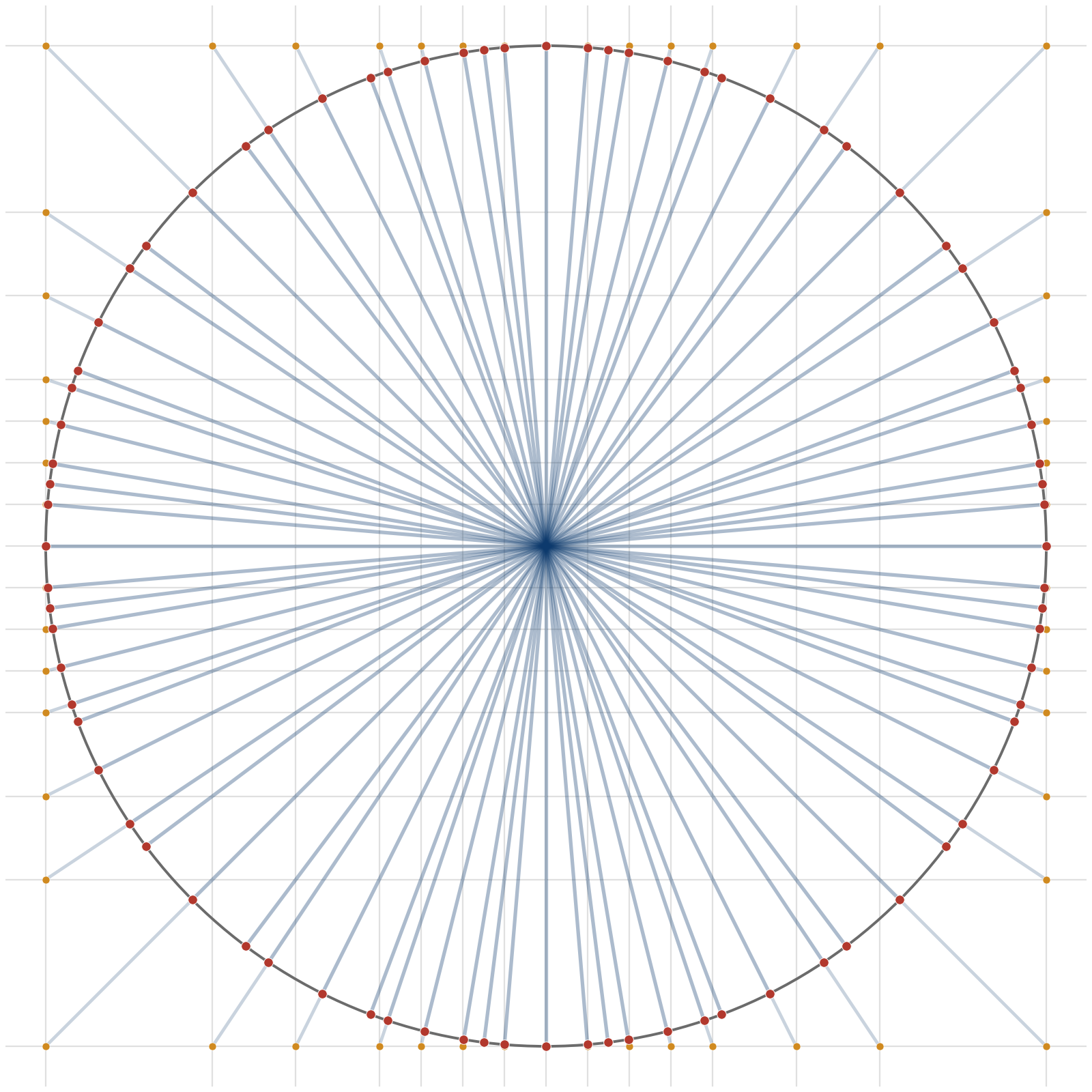
 elements. The definition
elements. The definition 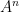 . The quantity
. The quantity  points.
points. 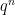 raw vectors, those vectors are not arbitrary. They arise from independent coordinate choices from the same scalar alphabet. Meanwhile, a spherical code with
raw vectors, those vectors are not arbitrary. They arise from independent coordinate choices from the same scalar alphabet. Meanwhile, a spherical code with 

 is the smaller of the number of positive and negative nonzero values in
is the smaller of the number of positive and negative nonzero values in 
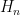 grows like
grows like  , this bound tends towards
, this bound tends towards 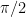 for any fixed alphabet. In plain language: in sufficiently high dimension, every fixed scalar alphabet has some direction that it represents very badly.
for any fixed alphabet. In plain language: in sufficiently high dimension, every fixed scalar alphabet has some direction that it represents very badly.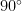 in high dimension (see above), it is more informative when comparing product codes to look at a normalised quantity such as:
in high dimension (see above), it is more informative when comparing product codes to look at a normalised quantity such as:
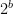 -element scalar alphabet. The quantity normBestFpCos n b is the corresponding floating-point quantity, optimised over valid splits of exponent and mantissa bits. The constants arbConst b and fpConst b are the two asymptotic constants being compared.
-element scalar alphabet. The quantity normBestFpCos n b is the corresponding floating-point quantity, optimised over valid splits of exponent and mantissa bits. The constants arbConst b and fpConst b are the two asymptotic constants being compared. , arbitrary scalar alphabets can do strictly better than the floating-point family in this asymptotic directional metric.
, arbitrary scalar alphabets can do strictly better than the floating-point family in this asymptotic directional metric.

