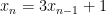On Tuesday, my PhD student Xitong Gao will present our work (joint with John Wickerson) on Automatically Optimizing the Latency, Area, and Accuracy of C Programs for High-Level Synthesis at the ACM International Symposium on Field-Programmable Gate Arrays.
Our starting point for this work is that people often want to express their algorithms in terms of real numbers, but then want to have an implementation is some finite precision arithmetic on an FPGA after passing the results through a High-Level Synthesis tool.
One of the key limiting factors of the performance of an algorithm is the ability of the HLS tool to pipeline loops in the design in order to maximise throughput. It turns out that numerical properties of real numbers can come to the rescue!
It’s a well known (but often forgotten) fact that computer-represented numbers are not – in fact are very far from – real numbers. In particular, the main equivalence properties that the real numbers exhibit: closure, associativity, commutativity, distributivity, etc. simply do not apply for a large number of practically used data representations.
In our paper we take account of this discrepancy by automatically refactoring code to make it run faster (while tracking area and accuracy too). As a trivial example for the recurrence