I’ve just returned from the ACM International Symposium on FPGAs, held – as usual – in sunny Monterey, California. This year I was Finance Chair of the conference, which meant I had less running about to do than the last two years, when I was Programme Chair in 2014 and then General Chair in 2015. I therefore took my time to enjoy the papers presented, which were generally of a high quality. Intel’s acquisition of Altera last year provided an interesting backdrop to the conference, and genuinely seems to have fired the community up, as more and more people outside the FPGA “usual suspects” are becoming very interested in the potential for this technology.
Below, I provide my impressions of the highlights of the conference, which necessarily form a very biased view based on what I find particularly interesting.
Architectures and Low-Level CAD
There were a couple of very interesting papers from Altera on their Stratix 10 device. These devices come with customisable clock trees, allowing you to keep the clock distribution local to your clock regions. The results showed that for regions consisting of fewer than 1.6M LEs, it was better to use a configurable clock region rather than any fixed clock region, as the latter needs greater margining. In a separate paper, Dave Lewis presented a detailed look at the Stratix 10 pipelined routing architecture, which gave a good insight into industrial architecture exploration. They had explored a range of circuits and tried to identify the maximum retiming performance that could be achieved around loops as a function of the number of pipelining registers they need to insert in the routing muxes. The circuit designs were discussed, but for me the most interesting thing about this innovation is the way it changes the tools: focus can be placed on P&R for loops rather than feed-forward portions of the design in the case that the design can tolerate latency; this is exactly where tools should be focusing effort. The kind of timing feedback to the user also changes significantly, and for the better.
Zgheib et al from Paolo Ienne’s group at EPFL presented their FPRESSO tool available at fpresso.epfl.ch which harnesses standard cell tools to explore FPGA architectures. Their tool is open source, and this paper won the best paper prize (becoming something of a habit for Paolo!). This tool could be an interesting basis for future academic architecture exploration.
Safeen Huda from Jason Anderson’s group at U of T presented an interesting suggestion for how suppress glitches for power reasons in FPGA circuits in the presence of PVT variation.
Davis demonstrated our work on run-time estimation of power on a per-module basis, part of the PRiME project, at the relevant poster session, and I was pleased by the number of people who could see the value in run-time monitors for this purpose.

Nadesh Ramanathan

James Davis
High Level Tools
Gao’s talk from my group on automatic optimisation of numerical code for HLS using expression rewriting was very well received, especially since he has made his tool available online at https://admk.github.io/soap/. We would be delighted to receive feedback on this tool.
Ramanathan’s presentation from my group on the case for work-stealing on FPGAs using atomic memory operations in OpenCL also seemed to generate quite a buzz at the discussion session afterwards.
Applications
There were quite a few application papers this year targeting Convolutional Neural Networks (CNNs), the application of the moment. Both of the full papers in this area (from Tsinghua and from Arizona State) emphasised the need to use low precision fixed-point datapath, an approach I’ve been pushing in the FPGA compute space for the last 15 years or more. This application seems to be particularly suited to the problem, allowing computation with little impact on classification down as low as 8 bits. The work from Tsinghua university also took advantage of an SVD approach to reduce the amount of compute required. I think there’s some promise to combine this with the fixed-point quantization, as first pointed out by Bouganis in his FCCM 2005 paper.
Overlays
The conference was preceded by the OLAF workshop run by John Wawrzynek and Hayden So. I must admit that I am not a huge fan of the idea of a hardware-implemented FPGA overlay architecture. I can definitely see the possible advantages of an overlay architecture as a conceptual device, a kind of intermediate format for FPGA compilation. I find it harder to make a compelling case for implementing that architecture in the actual hardware. However, if overlay architectures make programming FPGAs easier in those hard-to-reach areas (until we’ve caught up with our HLS technology!) and therefore expand the user base, then bring it on! A bit like floating point, in fact!
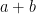



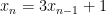 , a multiply and an add must be performed before executing the next iteration. But transforming this to
, a multiply and an add must be performed before executing the next iteration. But transforming this to  gives much more time to execute. Combining this with expression balancing, etc., leads to a wide variety of possible implementations, which our tool can explore automatically while also proving the numerical properties of the transformed code. This latter point makes it quite unlike so-called “unsafe” optimisations commonly used in compilers such as
gives much more time to execute. Combining this with expression balancing, etc., leads to a wide variety of possible implementations, which our tool can explore automatically while also proving the numerical properties of the transformed code. This latter point makes it quite unlike so-called “unsafe” optimisations commonly used in compilers such as 