This week sees the IEEE International Conference on Field-Programmable Logic and Applications, in Ghent, Belgium. Two of my team are attending to present their research papers on High Level Synthesis and on Run-time Power Estimation. In this post, I briefly summarise the key contributions of these papers.
High-Level Synthesis (HLS) is an important technology, which aims to automatically generate hardware designs from high-level (typically software) descriptions of their behaviour. In a previous blog post, I described some work from my PhD student Junyi Liu (joint with Sam Bayliss) on extending a common paradigm for analysis memory dependences – the polyhedral model – to a parametric version, for efficient pipelining in HLS. This week, Junyi presents an alternative use for the same parametric polyhedral HLS framework: automatic loop tiling (joint work with John Wickerson). Loop tiling is a very common compiler transformation – for example it is often used in matrix-matrix multiplication. The key advantage is to make sure that you only have a small set of data you’re working with at any given moment in time (traditionally for cache, in the FPGA context for embedded scratch-pad memories). The size of this working set can be traded off against the amount of off-chip memory traffic by selection of tile sizes. In a multi-dimensional loop, there are many possible options, and navigating this space is non-trivial. Junyi’s work provides a way to produce an explicit formula for both the memory requirement and the amount of off-chip data traffic required for any given tile size. He can then use nonlinear optimisation techniques to explicitly optimise the traffic subject to any given constraint on buffer size. This work is available as an open-source tool at https://github.com/Junyi-Liu/PolyTSS.
Back in 2016, some work I did with Eddie Hung, James Davis, Josh Levine, Ed Stott and Peter Cheung won the best paper prize at FCCM 2016. We showed that it is possible to use an online (recursive least squares) algorithm to learn the instantaneous power consumption of individual components in an FPGA design, with a view to some kind of run-time manager using this information. The solution worked by monitoring certain signal activity at run-time, but the missing part of the puzzle was which signals to monitor. James’s latest paper, STRIPE, with the same co-authors, answers this question. It turns out that the answer to this problem – as with so many in engineering (and life?) – lies in linear algebra. Golub and Van Loan describe in their classic textbook how QR factorisation can be used to heuristically select a subset of “nearly linearly independent” vectors from a larger set, and it’s this approach that tends to win out when given enough data to work with.
")



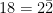 where the bar over a digit indicates a negative digit. But it also has the remarkable property that addition can be performed without inducing carries, leading to the potential for very significant parallelism. I particularly enjoyed that Miloš was able to trace this idea back to the 1700s, in a paper by John Colson, published in the Philosophical Transactions of the Royal Society, entitled
where the bar over a digit indicates a negative digit. But it also has the remarkable property that addition can be performed without inducing carries, leading to the potential for very significant parallelism. I particularly enjoyed that Miloš was able to trace this idea back to the 1700s, in a paper by John Colson, published in the Philosophical Transactions of the Royal Society, entitled






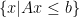 where
where  and
and  are parameters, there are various restricted approaches which more efficiently fix
are parameters, there are various restricted approaches which more efficiently fix  as
as  and showing that
and showing that 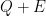 is positive semidefinite for some small
is positive semidefinite for some small 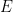 .
.