Readers of this blog will know that beyond my “day job”, I am interested in early mathematics education. Partly due to my outreach work with primary schools, I became aware of several tools that are used by primary (elementary) school teachers to help children grasp the structures present in arithmetic. The first of these, Cuisenaire Rods, have a long history and have recently come back in vogue in education. They consist of coloured plastic or wooden rods that can be physically manipulated by children. The second, usually known in this country as the Singapore Bar Model, is a form of drawing used to illustrate and guide the solution to “word problems”, including basic algebra. Through many discussions with my colleague, Charlotte Neale, I have come to appreciate the role these tools – and many other physical pieces of equipment, known in the education world as manipulatives – can play in helping children get to grips with arithmetic.
Cuisenaire and Bar Models have intrigued me, and I spent a considerable portion of my Easter holiday trying to nail down exactly what arithmetic formulae correspond to the juxtaposition of these concrete and pictorial representations. After many discussions with Charlotte, I’m pleased to say that we will be presenting our findings at the BSRLM Summer Conference on the 9th June in Swansea. Presenting at an education conference is a first for me, so I’m rather excited, and very much looking forward to finding out how the work is received.
In this post, I’ll give a brief overview of the main features of the approach we’ve taken from my (non educationalist!) perspective.
Firstly, to enable a formal study of these structures, we needed to formally define how such rods and diagrams are composed.
Cuisenaire Rods
These rods come in all multiples up to 10 of a single unit length, and are colour coded. To keep things simple, we’ve focused only on horizontal composition of rods (interpreted as addition) to form terms, as shown in an example below.

In early primary school, the main relationships being explored relating to horizontal composition are equality and inequality. For example, the figure below shows that black > red + purple, because of the overhanging top-right edge.

With this in mind, we can interpret any such sentence in Cuisenaire rods as an equivalent sentence in (first order) arithmetic. After having done so, we can easily prove mathematically that all such sentences are true. Expressibility and truth coincide for this Cuisenaire syntax! Note that this is very different to the usual abstract syntax for expressing number facts: although 4 = 2 + 1 is false, we can still write it down. This is one reason – we believe – they are so heavily used in early years education: truths are built through play. We only need to know syntactic rules for composition and we can make many interesting number sentences.
From an abstract algebraic perspective, closure and associativity of composition naturally arise, and so long as children are comfortable with conservation of length under translation, commutativity is also apparent. Additive inverses and identity are not so naturally expressed, resulting in an Abelian semigroup structure, which also carries over to our next tool, the bar model.
Bar Models
Our investigations suggest that bar models – example for 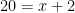 pictured below – are rarely precisely defined in the literature, so one of our tasks was to come up with a precise definition of bar model syntax.
pictured below – are rarely precisely defined in the literature, so one of our tasks was to come up with a precise definition of bar model syntax.
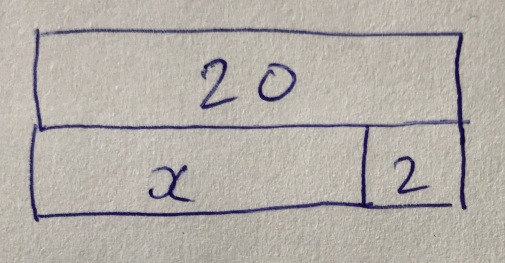
We have made the observation that there seem to be a variety of practices here. The most obvious one, for small numbers drawn on squared paper, is to retain the proportionality of Cuisenaire. These ‘proportional bar models’ (our term) inherit the same expressibility / truth relationship as Cuisenaire structures, of course, but now numerals can exceed 10 – at the cost of decimal numeration being a prerequisite for their use. However, proportionality precludes the presence of ‘unknowns’ – variables – which is where bar models are heavily used in the latter stages of primary schools and in some secondary schools.
At the other extreme, we could remove the semantic content of bar length, leaving only abutment and the alignment of the right-hand edges as denoting meaning – a type of bar model we refer to as a `topological bar model’. These are very expressive – they correspond to Presburger arithmetic without induction. It now becomes possible to express false statements (e.g. the trivial one below, stating that 1 = 2).
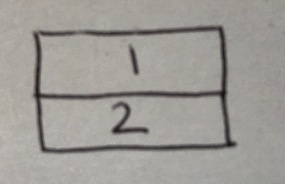
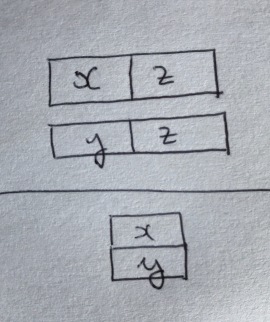
As a result, we must be mathematically precise about valid rules of inference and axiom schemata for this type of model, for example the rule of inference below. Note that due to the inexpressibility of implication in the bar model, many more rules of inference are required than in a standard first-order treatment of arithmetic.
The topological bar model also opens the door to many different mistakes, arising when children apply geometric insight to a topological structure.
In practice, it seems that teachers in the classroom informally use some kind of mid-way point between these two syntaxes, which we call an `order-preserving’ bar model: the aim is for relative sizes of values to be represented, ensuring that larger bars are interpreted as larger numbers. However, this approach is not compositional. Issues arising from this can be seen when trying to model, for example,  . The positive integral solutions are either
. The positive integral solutions are either 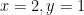 leading to
leading to  or
or 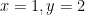 , leading to
, leading to  .
.
Other Graphical Tools and Manipulatives
As part of our work, we identify certain missing elements from first-order arithmetic in the tools studied to date. It would be great if further work could be done to consider drawings and manipulatives that could help plug these gaps. They include:
- Multiplication in bar models. While we can understand
 , for example, as a shorthand for
, for example, as a shorthand for  , there is no way to express
, there is no way to express 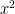
- Disjunction and negation. While placing two bar models side-by-side seems like a natural way of expressing conjunction, there is no natural way of expressing disjunction / negation. Perhaps a variation on Pierce’s notation could be of interest?
- We can consider variables in a bar model as implicitly existentially quantified. There is no way of expressing universal quantification.
- As noted above, these tools capture an Abelian semigroup structure. We’re aware of some manipulatives, such as Algebra Tiles, which aim to also capture additive inverses, though we’ve not explored these in any depth.
- We have only discussed one use of Cuisenaire rods – there are many others – as the recent ATM book by Ollerton, Williams and Gregg makes clear, many of which we feel could also benefit from analysis using our approach.
- There are also many more manipulatives than Cuisenaire, as Griffiths, Back and Gifford describe in detail in their book, and it would be of great interest to compare and contrast these from a formal perspective.
- At this stage, we have avoided introducing a monus into our algebra of bar models, but this is a natural next step when considering the algebraic structure of so-called comparative bar models.
- My colleague Dan Ghica alerted me to the computer game DragonBox Algebra 5+, which we can consider as a sophisticated form of virtual manipulative incorporating rules of inference. It would be very interesting to study similar virtual manipulatives in a classroom setting.
An Exciting Starting Point
Charlotte and I hope that attendees at the BSRLM conference – and readers of this blog – are as excited as we are about our idea of the potential for using the tools of mathematical logic and abstract algebra to understand more about early learning of arithmetic. We hope our work will stimulate some others to work with us to develop and broaden this research further.
Acknowledgement
I would like to acknowledge Dan Ghica for reading this blog post from a semanticist’s perspective before it went up, for reminding me about DragonBox, and for pointing out food for further thought. Any errors remain mine.


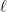


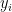

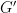
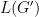
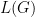
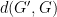

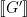
 , where
, where  . An interesting challenge is to produce another function
. An interesting challenge is to produce another function  with a ternary output
with a ternary output  bearing a close resemblance to
bearing a close resemblance to  . We can make the idea of bearing a close resemblance precise in the following way: if
. We can make the idea of bearing a close resemblance precise in the following way: if  declares a value true (false), then so must
declares a value true (false), then so must  and
and  (1)
(1) , is small in some sense, e.g. if
, is small in some sense, e.g. if 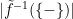 is small.
is small. subject to
subject to  and (1),
and (1), represents the cost (energy, area, latency) of implementing a function. One application area for this kind of investigation is in computer graphics. It is often the case that, when rendering a scene, an algorithm first needs to decide which components of the scene will definitely not be visible, and therefore need not be considered further. Should this part of the graphics pipeline make a mistake by deciding a component may be visible when it is actually invisible, little harm is done – more computation is required downstream in the graphics pipelining, costing energy and time, but not a reduced quality rendering. On the other hand, if it makes a mistake by deciding that a component is invisible when it is actually visible, this may cause a significant visual artefact in the rendered scene.
represents the cost (energy, area, latency) of implementing a function. One application area for this kind of investigation is in computer graphics. It is often the case that, when rendering a scene, an algorithm first needs to decide which components of the scene will definitely not be visible, and therefore need not be considered further. Should this part of the graphics pipeline make a mistake by deciding a component may be visible when it is actually invisible, little harm is done – more computation is required downstream in the graphics pipelining, costing energy and time, but not a reduced quality rendering. On the other hand, if it makes a mistake by deciding that a component is invisible when it is actually visible, this may cause a significant visual artefact in the rendered scene. , each produced by using
, each produced by using  . In this way we get a family of approximate computing hardware IP blocks, all of which guarantee that, when given a ray and a bounding box, if the IP reports no intersection between the two, then there is provably no intersection. Yet each family member operates at a different precision, requiring different circuit area, trading off against the rate of `false positives’. Georgios wrote
. In this way we get a family of approximate computing hardware IP blocks, all of which guarantee that, when given a ray and a bounding box, if the IP reports no intersection between the two, then there is provably no intersection. Yet each family member operates at a different precision, requiring different circuit area, trading off against the rate of `false positives’. Georgios wrote 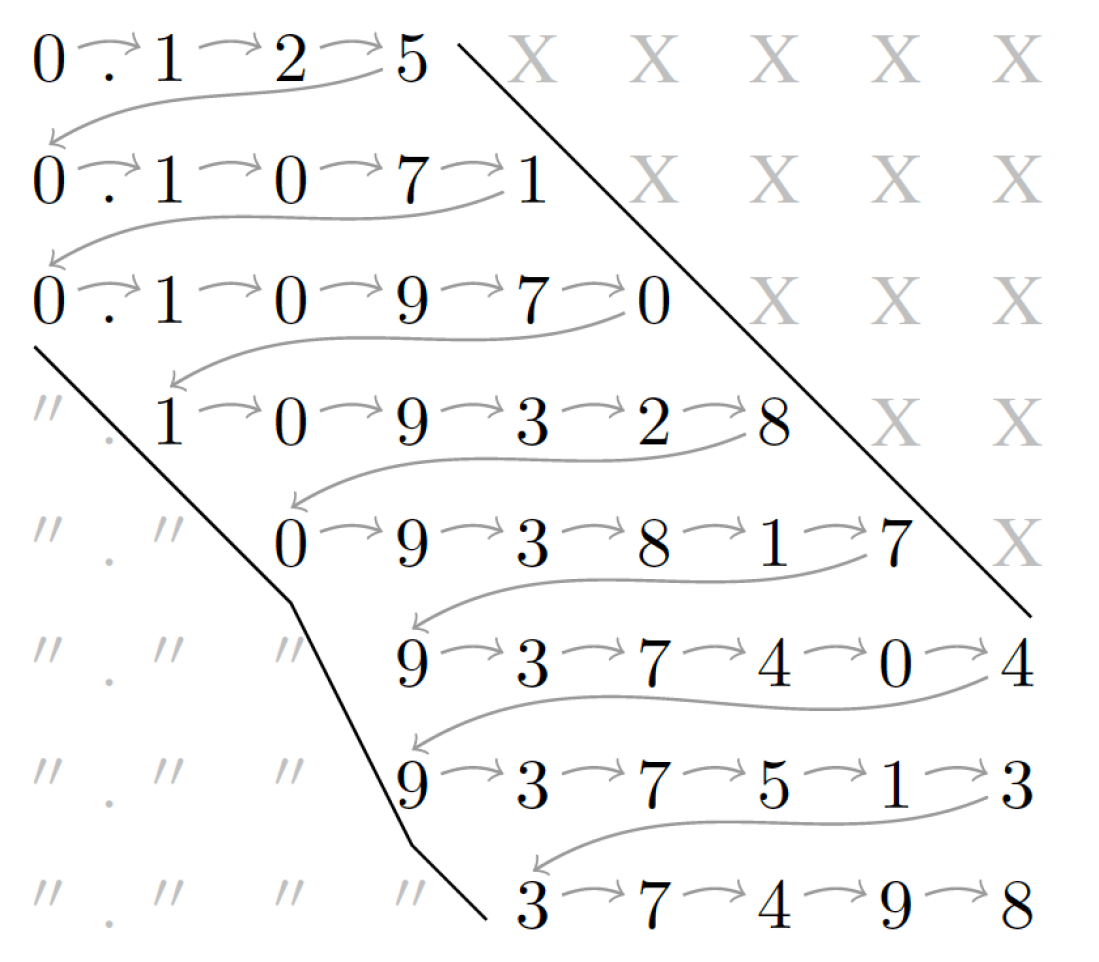
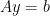 where
where  is a matrix of a special structure formed from constants
is a matrix of a special structure formed from constants 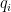 together with variable
together with variable  :
: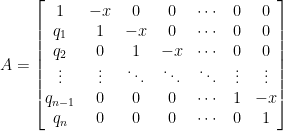
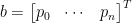 , then it turns out that the first element of the solution vector is the rational function
, then it turns out that the first element of the solution vector is the rational function  .
.
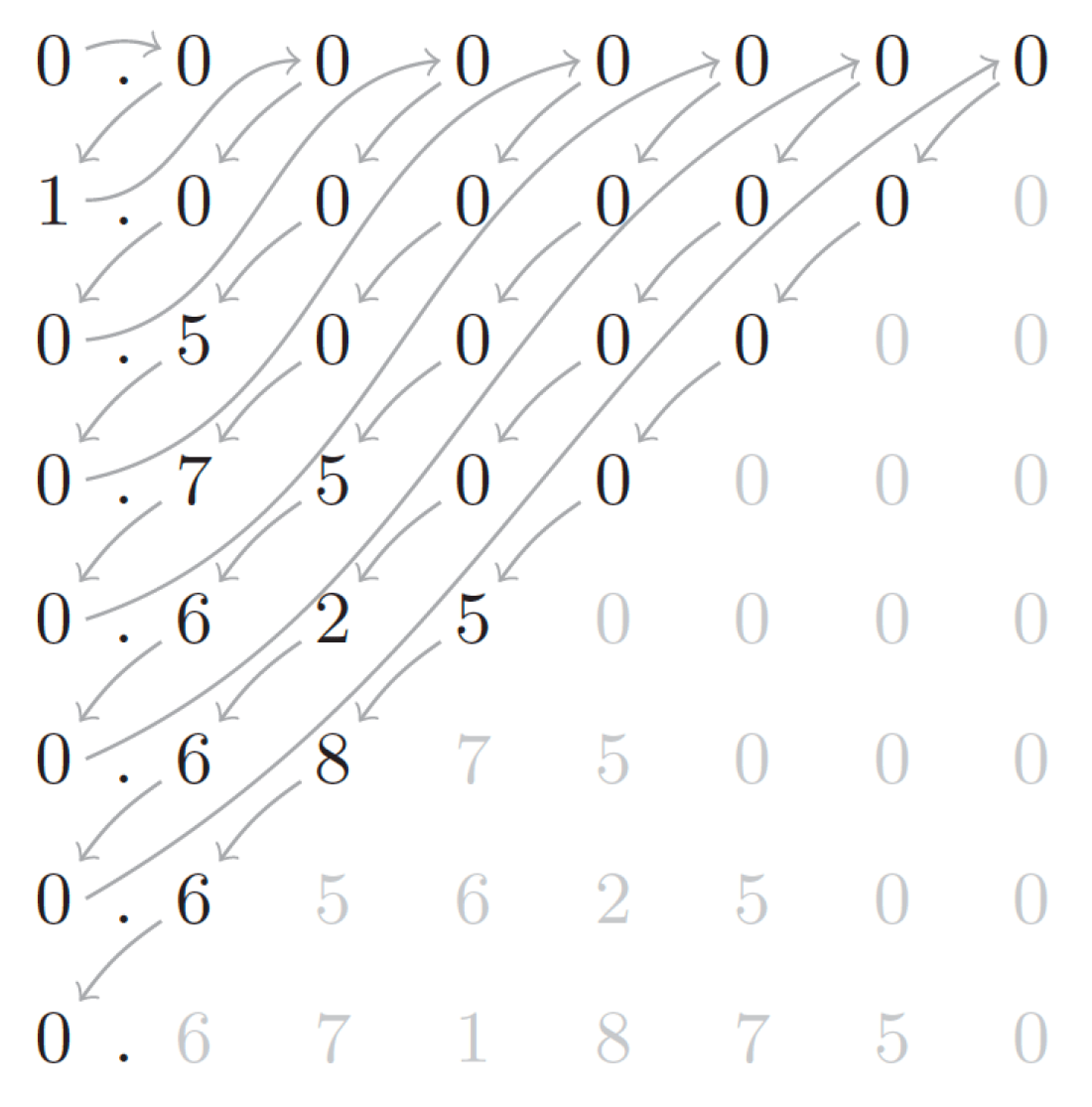
 denotes a predicate determining when the loop will exit,
denotes a predicate determining when the loop will exit, 
