I’m very excited to share that my PhD student, He Li, will tomorrow be presenting his paper ARCHITECT: Arbitrary-precision Constant-hardware Iterative Compute at the IEEE International Conference on Field-Programmable Technology 2017 (joint work also with James Davis and John Wickerson.)
Anyone who has done any numerical computation will sooner or later encounter a loop like this:
while( P(x) ) x = f(x);
Where 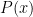


How do people tend to implement such loops? They approximate them by using a finite precision number system like floating point instead of reals.
OK, let’s say you’ve done your implementation. You run for 1000 iterations and still the loop hasn’t quit. Is that because you need to run for a few more iterations? Or is it because you computed in single precision instead of double precision? (Or double instead of quad, etc.) Do you have to throw away all your computation, go back to the first iteration, and try again in a higher precision? Often we just don’t know.
He’s paper solves this problem. As time progresses, we increase both the iteration and the accuracy to which a given iterate is known, snaking through the two-dimensional iteration / precision space, linearising two countably infinite dimensions into the single countably infinite dimension of time (clock cycle) using a trick due to Cantor.

This is the essence of our contribution.
To make it work in practice, efficiently in hardware, requires some tricks. For a start, we need to be able to support arbitrary precision arithmetic on finite computational hardware (only memory space growing with precision, not compute hardware). Secondly, we need to compute from most-significant to least-significant digit, iteratively refining our computation as we proceed. This form of computation is not supported naturally by standard binary arithmetic, but is supported by redundant arithmetic. We make use of online arithmetic to enable this transformation.
So now you don’t need to worry – rounding error will not stop you getting your answer. There’s an FPGA design for that.

2 thoughts on “Iterating Exactly”