My PhD student Erwei Wang, various collaborators and I have recently published a detailed survey article on this topic: Deep Neural Network Approximation for Custom Hardware: Where We’ve Been, Where We’re Going, to appear in ACM CSUR. In this post, I will informally explain my personal view of the role of approximation in supervised learning (classification), and how this links to the very active topic of DNN accelerator design in hardware.
We can think of a DNN as a graph , where nodes perform computations and edges carry data. This graph can be interpreted (executed) as a function mapping input data to output data. The quality of this DNN is typically judged by a loss function . Let’s think about the supervised learning case: we typically evaluate the DNN on a set of test input data points and their corresponding desired output , and compute the mean loss:
Now let’s think about approximation. We can define the approximation problem as – starting with – coming up with a new graph , such that can be somehow much more efficiently implemented than , and yet is not significantly greater than – if at all. All the main methods for approximating NNs such as quantisation of activations and weights and sparsity – structured and unstructured – can be viewed in this way.
There are a couple of interesting differences here to the different problem – often studied in approximate computing, or lossy synthesis – of approximating the original function . In this latter setting, we can define a distance between and (perhaps worst case or average case difference over the input data set), and our goal is to find a that keeps this distance bounded while improving the performance, power consumption, or area of the implementation. But in the deep learning setting, even the original network is imperfect, i.e. . In fact, we’re not really interested in keeping the distance between and bounded – we’re actually interested bounding the distance between and some oracle function defining the perfect classification behaviour. This means that there is a lot more room for approximation techniques. It also means that may even improve compared to , as sometimes seen – for example – through the implicit regularisation behaviour of rounding error in quantised networks. Secondly, we don’t even have access to the oracle function, only to a sample (the training set.) These features combine to make the DNN setting an ideal playground for novel approximation techniques, and I expect to see many such ideas emerging over the next few years, driven by the push to embed deep learning into edge devices.
I hope that the paper we’ve just published in ACM CSUR serves as a useful reference point for where we are at the moment with techniques that simultaneously affect classification performance (accuracy / loss) and computational performance (energy, throughput, area). These are currently mainly based around quantisation of the datatypes in (fixed point, binarisation, ternarisation, block floating point, etc.) topological changes to the network (pruning) and re-parametrisation of the network (weight sharing, low-rank factorisation, circulant matrices) as well as approximation of nonlinear activation functions. My view is that this is scratching the surface of the problem – expect to see many more developments in this area and consequent rapid changes in hardware architectures for neural networks!


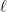


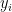

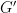
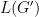
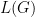
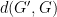

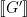

One thought on “Neural Networks, Approximation and Hardware”