This week, I attended the Design, Automation & Test in Europe (DATE) conference in Florence, Italy. DATE is a large conference, which I have attended irregularly since I was a PhD student. This year, the general chair was a long-standing colleague from the FPGA community, Jürgen Teich.
Readers can find a summary of some of the talks I found most interesting below.
On Tuesday, my colleague Martin Trefzer chaired a session on Computational and Resource-efficiency in Quantum and Approximate Computing. The work by Sekanina was interesting, using information on data distribution to drive the construction of approximate circuits. Circuits are constructed from the baseline using a technique called Cartesian Genetic Programming. I have recently been collaborating with Ilaria Scarabottolo and others from Laura Pozzi‘s group on a related problem – see our DAC 2019 paper (to appear) for details – so this was of particular interest.
On Wednesday, I chaired a session When Approximation Meets Dependability, together with my colleague Rishad Shafik. Ioannis Tsiokanos from Queen’s University Belfast presented an interesting approach that dynamically truncates precision in order to avoid timing violations. This is interestingly complementary to the approach I developed with my former PhD student Kan Shi where we first simply allowed timing violations [FCCM 2013], and secondly redesigned data representation based on Ercegovac‘s online arithmetic, so that timing violations caused low-magnitude error [DAC 2014].
David Pellerin from Amazon gave an interesting keynote address which very heavily emphasised Amazon’s F1 FPGA offering, which was – of course – music to my ears.
On Thursday morning, I attended the session Architectures for Emerging Machine Learning Techniques. Interestingly, there was a paper there making use of Gustafson’s posits within hardware-accelerated deep learning, a technique they dub Deep Positron.
The highlight talk for me was Ed Lee‘s Thursday keynote, A Fundamental Look at Models and Intelligence. Although I’ve been aware of Lee’s work, especially on Ptolemy, since I did my own PhD, I don’t think I’ve ever had the pleasure of hearing him lecture before. It was insightful and entertaining. A central theme of the talk was that models mean two different things for scientists and engineers: a scientist builds a model to correspond closely to a ‘thing’; an engineer builds a ‘thing’ to correspond closely to a model. He used dichotomy to illuminate some of the differences we see between neuroscience-inspired artificial intelligence and the kind of AI we see as very popular at the moment, such as deep learning. Lee’s general-readership book Plato and the Nerd – which has been on my “to read” list since my colleague and friend Steve Neuendorffer mentioned it to me a few years ago – has just climbed several notches up that list!
On Thursday afternoon, I attended the session on The Art of Synthesizing Logic. My favourite talk in this session was from Heinz Reiner, who presented a collaboration between EPFL and UC Berkeley on Boolean rewriting for logic synthesis, in which exact synthesis methods are used to replace circuit cuts, rather than resorting to a pre-computed database of optimal function implementations. During the talk, Reiner also pointed the audience to an impressive-looking GitHub repo, featuring what looks like some very useful tools.
Friday is always workshop day at DATE, featuring a number of satellite workshops. I attended the workshop entitled Quo Vadis, Logic Synthesis?, organised by Tiziano Villa and Luca Carloni. This was a one-off workshop in celebration of the 35th anniversary of the publication of the influential Espresso book on two-level logic minimisation.
Villa talked the audience through the history of logic synthesis, starting with the Quine-McCluskey method.
My favourite talk in this workshop was from Jordi Cortadella, who spoke about a method for synthesising Boolean relations. This is the problem of synthesising a the cheapest implementation of a function 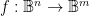



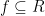
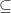
Soeken also presented a very interesting summary of three uses of SAT within logic synthesis, namely Schmitt’s ASP-DAC paper on SAT-based LUT mapping, Eén’s paper on using logic synthesis for efficient SAT (rather than SAT for efficient logic synthesis) and Haaswijk‘s recent PhD on making exact logic synthesis more scalable by providing partial topological information – a topic that interestingly has some echoes in work I’m soon to present at the Royal Society.
The workshop was an enjoyable way to end DATE, and I was disappointed to have to leave half-way through – there may well have been other interesting talks presented in the afternoon.
