Over the second half of this week, I’ve been attending the SIAM Computational Science and Engineering conference in Spokane, Washington – a short flight north (and a radical change in weather) from my earlier conference in California this week.

This was my first SIAM conference. I was kindly invited to speak on the topic of floating-point error analysis by Pierre Blanchard, Nick Higham and Theo Mary. I very much enjoyed the sessions they organised and indeed the CSE conference, which I hope to be able to attend more regularly from now on.
My own talk was entitled Approximate Arithmetic – A Hardware perspective. I spoke about the rise of architecture specialisation as driving the need for closer collaboration between computer architects and numerical analysts, about some of our work on automatic error bounds Boland and Constantinides (2011) and Magron, Constantinides and Donaldson (2017), on code refactoring Gao and Constantinides (2015), as well as some of our most recent work on machine learning (I will blog separately about this latter topic over the next couple of months.)
The CSE conference is very large – with 30-40 small parallel sessions happening at any given moment – so I cannot begin to summarise the conference. However, I include some notes below on other talks I found particularly interesting.
Plenary Sessions
I very much enjoyed the plenary presentation by Rachel Ward on Stochastic Gradient Descent (SGD) in Theory and Practice. She introduced the SGD method very nicely, and looked at various assumptions for convergence. She took a particularly illuminating approach, by looking at applying SGD to the simple special case of solving a system of linear equations by minimising 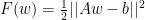
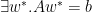
- Needell, Srebro and Ward (2013) on convergence of SGD
- Soudry, Carmon (2016) and Du, Zhai, Poczos, Singh (2019) on the absence of poor local minima
There was also an interesting plenary from Anima Anandkumar on the role of tensors in machine learning. The mathematical structure of tensors and multi-linear algebra are topics I’ve not explored before – mainly because I’ve not seen the need to spend time on them. Anandkumar certainly provided me with motivation to do that!
Floating-Point Error Analysis
Theo Mary from the University of Manchester gave a very good presentation of his work with Nick Higham on probabilistic rounding error analysis, treating numerical roundoff errors as zero-mean independent random variables of arbitrary distribution, making use of Hoeffding’s inequality to a produce a backward error analysis. Their work is described in more detail on their own blog post and – in more depth – in their their very interesting paper. It’s a really exciting and useful direction, I think, given the greater emphasis on average-case performance from modern applications, together with both very large data sets and very low precision computation, the combination of which renders many worst-case analyses meaningless. In a similar vein, Ilse Ipsen also presented a very interesting approach: a forward error analysis, more specialised in that she only looked at inner products, but also without the assumption of independence, making use of Azuma’s inequality. The paper on this topic has not yet been finished, but I certainly look forward to reading it in due course!
Reducing Communication Costs
There were a number of interesting talks on mitigating communication costs. Lawrence Livermore National Labs presented several papers relating to the ZFP format they’ve recently proposed for (lossily) compressed floating-point vectors, at a mini-symposium organised by Alyson Fox, Jeffrey Hittinger, and James Diffenderfer. Diffenderfer’s talk developed a bound on the norm-wise relative error of vectors reconstructed from ZFP; Alyson Fox’s talk then extended this to the setting of iterative methods, noting as future work their interest in probabilistic analyses. In the same session, Nick Higham gave a crystal clear and well-motivated talk on his recent work with Srikara Pranesh and Mawussi Zunon – slides and paper are available. This work extends the applicability of Nick’s earlier work with Erin Carson to cases that would have over- or under-flowed, or led to subnormal numbers, without the scaling technique developed and analysed here. They use matrix equilibration – this reminded me of some work I did with my former PhD student Juan Jerez and colleague Eric Kerrigan, but in our case for a different algorithm kernel and targeting fixed-point arithmetic, where making use of the full dynamic range is particularly important. The Higham, Pranesh and Zunon results are both interesting and practically very useful.
In a different session, Hartwig Anzt spoke about the work he and others have been doing to explicitly decouple storage precision from compute precision in sparse linear algebra. The idea is simple but effective: take the high-order bits of the mantissa (and the sign / exponent) and store them in one chunk of data and – separately – store the low-order bits in another chunk. Perform all arithmetic in high precision (because it’s not the computation that’s the bottleneck), but convert low-precision stored data to high precision on the fly at data load (e.g. by packing low-order bits with zeros.) Then, at run-time, decide whether to load the full-precision data or only the low-precision data, based on current estimates of convergence. This approach could also make a good case study application for the run-time adaptation methodology we developed with U. Southampton in the PRiME project.
A Reflection
Beyond the technical talks, there were two things that stood out for me since I’m new to the conference. Firstly, there were many more women than in the typical engineering conferences I attend. I don’t know whether the statistics on maths versus engineering are in line with this observation, but clearly maths is doing something right from which we could learn. Secondly, there were clear sessions devoted to community building: mentoring sessions, tutorials for new research students, SIAM student chapter presentations, early career panels, presentations on funding programmes, diversity and inclusion sessions, a session on helping people improve their CV, an explicit careers fair, etc. Partly this may simply reflect the size of the conference, but even so, this seems to be something SIAM does particularly well.
