In my previous post, I argued that block number formats can be understood geometrically as direction preservers. That argument relied on an idealization: once a block direction had been chosen, its scale could be set optimally as an arbitrary real number.
Real hardware formats do not usually work that way. In many practical schemes, block scales are quantized very coarsely, sometimes all the way down to powers of two. In particular, in the MX specification, all the concrete compliant formats use E8M0 scaling.
So does the directional picture I painted in my last post survive this brutal scaling? Here I will argue, in the first of what I hope will be a short sequence of follow-up blog posts, that it does.
From ideal block scales to quantized block scales
Recall the setup from the earlier post. A vector is partitioned into blocks, 



In the earlier post, I assumed that 
Now let us keep the same mantissa vectors 

It is convenient to define the multiplicative scale error 

Note that, of course, quantizing the block scale does not change the chosen direction of a block at all; it only changes its length. So the only directional distortion comes from the relative rescaling of different blocks.
An exact cosine formula
Let 


Then it can be shown that 
So the effect of scale quantization on direction depends only on how uneven the factors 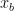
Exponent-only power-of-two scaling
Now consider the coarsest plausible case: each block scale is rounded to the nearest power of two. Then each multiplicative error satisfies ![x_b \in [2^{-1/2},\,2^{1/2}]](https://s0.wp.com/latex.php?latex=x_b+%5Cin+%5B2%5E%7B-1%2F2%7D%2C%5C%2C2%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
So, from our exact cosine formula, we are interested in how small 
![[2^{-1/2},\,2^{1/2}]](https://s0.wp.com/latex.php?latex=%5B2%5E%7B-1%2F2%7D%2C%5C%2C2%5E%7B1%2F2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
A simple inequality shows that the answer depends only on the two extreme values of the interval. If all the block rescaling factors lie in ![[\ell,u]](https://s0.wp.com/latex.php?latex=%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002)

In the power-of-two case we have 



Equivalently, 
So even if every block scale is rounded to the nearest power of two, the resulting vector remains within about 
That is the main result of this post.
One striking feature of the bound is that it does not depend on the dimension of the vector. The reason is that the worst case is already attained by a two-group energy split: some blocks rounded up, others rounded down. Once those two groups exist, adding more blocks or more dimensions does not make the bound worse, as is apparent from the proof below.
20 degrees is less than it sounds
Our everyday intuition may tell us that this angle is not huge, but it’s not that small either. In a sense, that’s true. But angles behave very differently in high-dimensional spaces. In high dimension, most random vectors are almost orthogonal to one another: their angle is close to 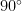
Beyond power-of-two
We’ve analysed power-of-two scaling here for two reasons: because it’s in a sense the crudest possible floating-point rounding, and because it’s commonly used in real hardware designs.
That does not mean it’s optimal. But it does raise two further questions. Firstly, we’ve assumed here that the exponent range is sufficiently wide – what if it’s not? Secondly – and relatedly – how much better can this angular bound get by spending some of the scale bits on greater precision?
My view is that the answer becomes clearer once a tensor-wide high-precision scale is introduced, something NVIDIA has recently done. In that setting, the block scales get relieved of their additional duty to capture global magnitude. This will be the subject of the next post on the topic!
Proofs
Readers not interested in the algebra can safely skip this section.
Cosine formula
Recall that
Then, because the blocks occupy disjoint coordinates, 
Also, 

Therefore 
Now, as per the main blog post, define
Writing 





20 degree bound
Assume that all the multiplicative error factors lie in an interval ![x_b \in [\ell,u]](https://s0.wp.com/latex.php?latex=x_b+%5Cin+%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002)

Let 
Then the cosine is just 
![x_b\in[\ell,u]](https://s0.wp.com/latex.php?latex=x_b%5Cin%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002)

Expanding this gives

Multiplying by

Therefore 
Now the weighted mean 

![\mu\in[\ell,u]](https://s0.wp.com/latex.php?latex=%5Cmu%5Cin%5B%5Cell%2Cu%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Differentiating shows that the minimum occurs at 
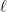

Substituting this value gives

and therefore

So we have proved that
Finally, in the power-of-two case we have

Numerically,

so

 whose coordinates are partitioned into blocks
whose coordinates are partitioned into blocks  .
. is invariant to rescaling of
is invariant to rescaling of  of a vector into its magnitude and direction, but applied locally within blocks.
of a vector into its magnitude and direction, but applied locally within blocks. , then scaling it appropriately produces a good approximation of that block.
, then scaling it appropriately produces a good approximation of that block. . Then
. Then  is the orthogonal projection of
is the orthogonal projection of  .
. .
. , which we can think of as the fraction of the vector’s energy contained in block
, which we can think of as the fraction of the vector’s energy contained in block  .
. represent how much of the vector’s energy lies in each block. Blocks that contain very little energy contribute very little to the final direction. The important consequence is that direction errors do not accumulate catastrophically across blocks. Instead, the overall directional error simply depends on a weighted average of the block direction errors. In other words, if block number formats preserve the directions of individual blocks, they automatically preserve the direction of the entire vector.
represent how much of the vector’s energy lies in each block. Blocks that contain very little energy contribute very little to the final direction. The important consequence is that direction errors do not accumulate catastrophically across blocks. Instead, the overall directional error simply depends on a weighted average of the block direction errors. In other words, if block number formats preserve the directions of individual blocks, they automatically preserve the direction of the entire vector. where
where  is orthogonal to
is orthogonal to  .
. .
. .
. , we obtain
, we obtain .
. .
. .
. , and writing
, and writing .
. , we obtain
, we obtain .
.