This book, The Learning Powered School, subtitled Pioneering 21st Century Education, by Claxton, Chambers, Powell and Lucas, is the latest in a series of books to come from the work initiated by Guy Claxton, and described in more detail on the BLP website. I first became aware of BLP through an article in an education magazine, and since found out that one of the teachers at my son’s school has experience with BLP through her own son’s education. This piqued my interest enough to try to find out more.
The key idea of the book is to reorient schools towards being the places where children develop the mental resources to enjoy challenge and cope with uncertainty and complexity. The concepts of BLP are organised around “the 4 Rs”: resilience, resourcefulness, reflectiveness, and reciprocity, which are discussed throughout the book in terms of learning, teaching, leadership, and engaging with parents.
Part I, “Background Conditions”, explains the basis for BLP in schools in terms of both the motivation and the underlying research.
Firstly, motivation for change is discussed. The authors argue that both national economic success and individual mental health is best served by parents and schools helping children to “discover the ‘joy of the struggle’: the happiness that comes from being rapt in the process, and the quiet pride that comes from making progress on something that matters.” This is, indeed, exactly what I want for my own son. They further argue that schools are no longer the primary source of knowledge for children, who can look things up online if they need to, so schools need to reinvent themselves, not (only) as knowledge providers but as developers of learning habits. I liked the suggestion that “if we do not find things to teach children in school that cannot be learned from a machine, we should not be surprised if they come to treat their schooling as a series of irritating interruptions to their education.”
Secondly, the scientific “stable” from which BLP has emerged is discussed. The authors claim that BLP primarily synthesises themes from Dweck‘s research (showing that if people believe that intelligence is fixed then they are less likely to be resilient in their learning), Gardner (the theory of multiple intelligences), Hattie (emphasis on reflective and evaluative practice for both teachers and pupils), Lave and Wenger (communities of practice, schools as an ‘epistemic apprenticeship’), and Perkins (the learnability of intelligence). I have no direct knowledge of any of these thinkers or their theories, except through the book currently under review. Nevertheless, the idea of school (and university!) as epistemic apprenticeship, and an emphasis on reflective practice ring true with my everyday experience of teaching and learning. The seemingly paradoxical claim that emphasising learning rather attainment in the classroom leads to better attainment is backed up with several references, but also agrees with a recent report on the introduction of Level 6 testing in UK primary schools I have read. The suggestion made by the authors that this is due increased pressure on pupils and more “grade focus” leading to shallow learning.
The book then moves on to discuss BLP teaching in practice. There is a huge number of practical suggestions made. Some that particularly resonated with me included:
- pupils keeping a journal of their own learning experiences
- including focus on learning habits and attitudes in lesson planning as well as traditional focuses on subject matter and assessment
- a “See-Think-Wonder” routine: showing children something, encouraging them to think about what they’ve seen and record what they wonder about
Those involved in school improvement will be used to checklists of “good teaching”. The book provides an interesting spin on this, providing a summary of how traditional “good teaching” can be “turbocharged” in the BLP style, e.g. students answer my questions confidently becomes I encourage students to ask curious questions of me and of each other, I mark regularly with supportive comments and targets becomes my marking poses questions about students’ progress as learners, I am secure and confident in my curriculum knowledge becomes I show students that I too am learning in lessons. Thus, in theory, an epistemic partnership is forged.
There is some discussion of curriculum changes to support BLP, which are broadly what I would expect, and a variety of simple scales to measure pupils’ progress against the BLP objectives to complement more traditional academic attainment. The software Blaze BLP is mentioned, which looks well worth investigating further – everyone likes completing quizzes about themselves, and if this could be used to help schools reflect on pupils’ self-perception of learning, that has the potential to be very useful.
In a similar vein, but for school leadership teams, the Learning Quality Framework looks worth investigating as a methodology for schools to follow when asking themselves questions about how to engage in a philosophy such as BLP. It also provides a “Quality Mark” as evidence of process.
Finally, the book summarizes ideas for engaging parents in the BLP programme, modifying homework to fit BLP objectives and improve resilience, etc.
Overall, I like the focus on:
- an evidence-based approach to learning (though the material in this book is clearly geared towards school leaders rather than researchers, and therefore the evidence-based nature of the material is often asserted rather than demonstrated in the text)
- the idea of creating a culture of enquiry amongst teachers, getting teachers to run their own mini research projects on their class, reporting back, and thinking about how to evidence results, e.g. “if my Year 6 students create their own ‘stuck posters’, will they become more resilient?”
I would strongly recommend this book to the leadership of good schools who already have the basics right. Whether schools choose to adopt the philosophy or not, whether they “buy in” or ultimately reject the claims made, I have no doubt that they will grow as places of learning by actively engaging with the ideas and thinking how they could be put into practice, or indeed whether – and where – they already are.
to the letter
for some key
, and forgetting the modulo arithmetic in play, despite having the wheel in front of them.
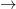 , logical implication. In classical logic, this is a most confusing connective (or at least was to my students when I taught an introductory undergraduate course in the subject long ago). I would give my students examples of true statements such as “George is the Pope” implies “George is Hindu” to emphasise the difference between the material implication of classical logic and our everyday use of the word. It is exactly this discrepancy addressed by Anderson and Belnap’s logic. I was least familiar with the content of this part of the book, therefore the initial sections came as something of a surprise, as I found them rather drawn out and repetitive for my taste, certainly compared to the crisp presentation in Parts 1 and 2. However, things got exciting and much more fast moving by Chapter 8, Natural Deduction, where there are clear philosophical arguments to be had on both sides. In general, I found the discussion very interesting. Clearly a major issue with the line of reasoning given by my Pope/Hindu example above is that of relevance. Relevance might be a slippery notion to formalise, but it is done so here in a conceptually simple way: “in order to derive an implication, there must be a proof of the consequent in which the antecedent was actually used to prove the consequent.” Actually making this work in practice requires a significant amount of baggage, based on tagging
, logical implication. In classical logic, this is a most confusing connective (or at least was to my students when I taught an introductory undergraduate course in the subject long ago). I would give my students examples of true statements such as “George is the Pope” implies “George is Hindu” to emphasise the difference between the material implication of classical logic and our everyday use of the word. It is exactly this discrepancy addressed by Anderson and Belnap’s logic. I was least familiar with the content of this part of the book, therefore the initial sections came as something of a surprise, as I found them rather drawn out and repetitive for my taste, certainly compared to the crisp presentation in Parts 1 and 2. However, things got exciting and much more fast moving by Chapter 8, Natural Deduction, where there are clear philosophical arguments to be had on both sides. In general, I found the discussion very interesting. Clearly a major issue with the line of reasoning given by my Pope/Hindu example above is that of relevance. Relevance might be a slippery notion to formalise, but it is done so here in a conceptually simple way: “in order to derive an implication, there must be a proof of the consequent in which the antecedent was actually used to prove the consequent.” Actually making this work in practice requires a significant amount of baggage, based on tagging 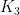 could be manipulated to produce the
could be manipulated to produce the 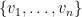 and edge set
and edge set 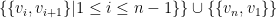 (is there a name for these graphs?). One child completely independently found that for
(is there a name for these graphs?). One child completely independently found that for 