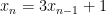This week sees the IEEE International Symposium on Field-Programmable Custom Computing Machines hosted in Vancouver, BC, Canada. I have sent my PhD student, Junyi Liu, who is presenting some work we’ve done together with my former research fellow, now a member of staff at Xilinx, Sam Bayliss.
Junyi and I are interested in memory accesses about which we know something at compile time, but not quite enough to be able to have a complete picture of what they’ll be at run time. This means that existing analyses of code containing these accesses will typically result in suboptimal behaviour at run time.
The case we study in this paper is that of affine loop nests containing memory accesses whose addresses involve indeterminate variables that do not change value as the loop executes. The value of these variables can completely change the dependence structure of the loop, meaning that for some values, the loop can be highly pipelined and run extremely fast whereas for other values, the loop must run very slowly. We give the trivial example below in the paper:
for( int i=LB; i<=UB; i++ )
A[i] = A[i+m] + 1;
The variable m does not change as the loop executes. For some values of m, each iteration of the loop must start execution when the previous one finishes. For other values of m, we can pipeline the loop so that iterations overlap in time. So how to discover this and take advantage of it automatically?
We present an approach based on an extension of the polyhedral model to parametric polyhedra, where the parameters are these parameters, like m, unknown at compile time. My former PhD student Qiang Liu (no relation), colleague Kostas Masselos and I were some of the first people to bring the polyhedral model to FPGA-based computation in our FCCM 2007 paper (Qiang is now an associate professor at Tianjin University) but to the best of my knowledge, parametric polyhedra are relatively understudied in this area.
The basic idea of this new work is simple: use static analysis to identify regions of the parameter space where you can run the loop fast, and synthesise light-weight detectors of these regions for runtime checks on entry to the loop nest. Since my original work with the polyhedral model, high level synthesis has become a commercial reality, so we build on top of Xilinx VivadoHLS, implementing our tool as a source-to-source transformation engine. This automatically inserts the appropriate VivadoHLS pragmas as well as the extra code for the runtime checks.
The results are very promising: some of our benchmarks show a 10x speedup in initiation interval (the time you need to wait before executing another iteration of the loop).