In early September, my PhD student Marta Andronic will be off to Turin to present our latest work “NeuraLUT: Hiding Neural Network Density in Boolean Synthesizable Functions” at the Field-Programmable Logic and Applications conference. Ahead of the detailed presentation at the conference, this blog post provides a short accessible summary of her exciting work.
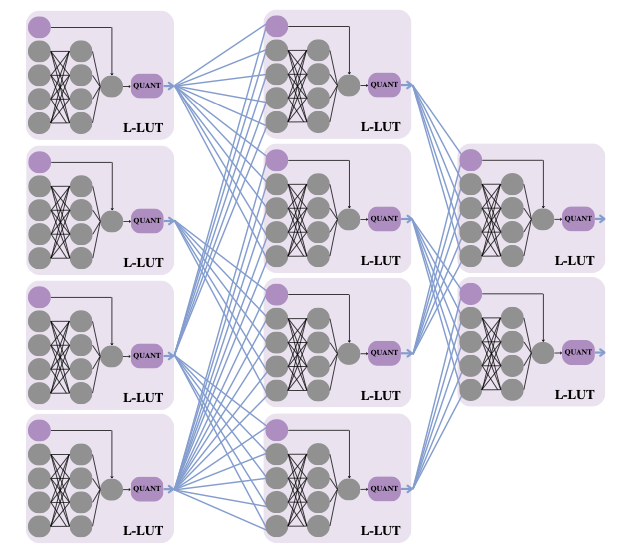
In 2019 I first proposed making better use of FPGA lookup tables by exposing them as trainable hardware, together with my then PhD student Erwei Wang and coauthors, in our LUTNet work. In common with AMD’s LogicNets and our PolyLUT, our new work NeuraLUT hides certain aspects of a neural network within a synthesisable Boolean lookup table (which we call an L-LUT), to achieve very efficient and very low latency inference. LogicNets hid a dot product and activation function – the clever thing in LogicNets was that, as a result, the weights can be real-valued – no quantisation needs to be performed, because the only thing that’s important is the finite truth table of the lookup table; once this has been enumerated, the real-valued weights are irrelevant, the only quantisation is at the inputs and outputs of the L-LUT. The tradeoff here is that LogicNets networks needed to be extremely sparse.
NeuraLUT takes this a step beyond by hiding whole neural networks inside Boolean lookup tables! These internal neural networks can be fully dense – or even irregularly connected – and real-valued in both weight and activation, for the same reason. The only thing that’s important is that the inputs and outputs of these “sub networks” are quantised and connections between sub networks are sparse, because these are the only parts that get exposed to the hardware design itself. One can interpret the resulting network as a standard deep neural network, with a specific hardware-friendly sparsity pattern, as illustrated in the figure below.
The increased expressive power of NeuraLUT leads to considerable reductions in latency. We’re targeting here very low latency applications like you may find in particle physics. 12 nanosecond MNIST classification, anyone? 3 nanoseconds to tag jet substructures in a particle accelerator? Come and listen to Marta’s talk to find out how!