My PhD student Sam Coward (jointly advised by Theo Drane from Intel) is about to head off on a speaking tour, where he will be explaining some of our really exciting recent developments. We’ve developed an approach that allows the discovery, exploitation, and generation of datapath hardware that works well in certain special cases. We’ve developed some theory (based on abstract interpretation), some software (based on egg), and some applications (notably in floating-point hardware design). Sam will be formally presenting this work at SOAP, EGRAPHS, and DAC over the coming weeks. In this blog post, I will try to explain the essence of the work. More detail can be found in the papers, primarily [1,2], with [3] for background.
We know that sometimes we can take shortcuts in computation. As a trivial example, we know that 

Readers of this blog may remember that Sam, Theo and I published a paper at ARITH 2022 that demonstrated that e-graphs can be used to discover hardware that is equivalent in functionality, but better in power, performance, and area. E-graphs are built by repeatedly using rewrite rules of the form 


So we set out to answer:
- how can we deal with conditional rewrites in our e-graphs?
- how can we evaluate whether a condition is true in a certain context?
- how can we make use of this to discover and optimise special cases in numerical hardware?
Based on an initial suggestion from Pavel Panchekha, Sam developed an approach to conditionality by imagining augmenting the domain in which we’re working with an additional element, let’s call it 



So how do we actually evaluate whether a condition is true in a given context? This is essentially a program analysis question. Here we make use of a variation of classical interval arithmetic. However, traditionally interval arithmetic has been a fairly weak program analysis method. As an example, if we know that ![x \in [-1,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002)

![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=ffffff&fg=000000&s=0&c=20201002)



![[0,0]](https://s0.wp.com/latex.php?latex=%5B0%2C0%5D&bg=ffffff&fg=000000&s=0&c=20201002)
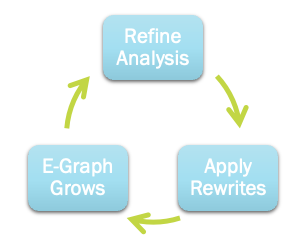
This interaction between rewrites and conditions goes even further: a more precise analysis leads to the possibility to fire more conditional rewrite rules, as more conditions will be known to hold; firing more rewrite rules results in an even more precise analysis. The two techniques reinforce each other in a virtuous cycle:
Our technique is able to discover, and generate RTL for, near/far-path floating-point adders from a naive RTL implementation (left transformed to right, below), resulting in a 33% performance advantage for the hardware.

I’m really excited by what Sam’s been able to achieve, as I really think that this kind of approach has the potential to lead to huge leaps forward in electronic design automation for word-level designs.

3 thoughts on “Discovering Special Cases”