I’ve always struggled with the concept of “doing your best”, especially with regards to avoiding harm. This morning from my sick bed I’ve been playing around with how I could think about formalising this question (I always find formalisation helps understanding). I have not got very far with the formalisation itself, but here are some brief notes that I think could be picked up and developed later for formalisation. Perhaps others have already done so, and if so I would be grateful for pointers to summary literature in this space.
The context in which this arises, I think, is what does it mean to be responsible for something, or even to blame? We might try to answer this by appeal to social norms: what the “reasonable person” would have done. But in truth I’m not a big fan of social norms: they may be politically or socially biased, I’m never confident that they are not arbitrary, and they are often opaque to those who think differently.
So rather than starting from norms, in common with many neurodivergents, I want to think from first principles. How should we define our own responsibilities when we act with incomplete information? And what does it mean to be “trying one’s best” in that situation? And how do we not get completely overwhelmed in the process?
Responsibility and Causality
One natural starting point is causal responsibility. If I take action A and outcome B occurs, we ask: would B have been different if I had acted otherwise? Causal models could potentially make this precise through counterfactuals. This captures the basic sense of control: how pivotal was my action?
But responsibility isn’t just about causality. It is also about what I knew (or should have known) when I acted.
Mens Rea in the Information Age
The legal tradition of mens rea, the “guilty mind”, is helpful here. It recognises degrees of responsibility, such as:
Intention: I aimed at the outcome.
Knowledge: I knew the outcome was very likely.
Recklessness: I recognised a real risk but went ahead regardless.
Negligence: I failed to take reasonable steps that would have revealed the risk.
It’s the final one of these, negligence, that causes me the most difficulty on an emotional level. A generation ago, a “reasonable step” might be to ask a professional. But in the age of abundant online information, the challenge is defining what “reasonable steps” now are. No one can read everything, and I personally find it very hard to draw the line.
If we had knowledge of how the information we gain increases with the time we spend collecting that information, we would be in an informed place. We could decide, based on the limited time we have, how long we wish to explore any given problem.
From Omniscient Optimisation to Procedural Reasonableness
However, we must accept that there are at least two levels of epistemic uncertainty here. We don’t know everything there is to know, but nor do we even know how the amount of useful information we collect will vary based on the amount of time we put in. Maybe just one more Google search or just one more interaction with ChatGPT will provide the answer to our problem.
In response, I think we must shift the benchmark. Trying one’s best does not mean picking the action that hindsight reveals as correct. It means following a reasonable procedure given bounded time and attention.
So what would a reasonable procedure look like? I would suggest that we start with the most salient, socially-accepted, and low-cost information sources. We then keep going with our investigation until further investigation is unlikely to change the decision in proportion to its cost.
In principle, we may want to continue searching until the expected value of more information is less than its cost. But of course, in practice we cannot compute this expectation.
A workable heuristic appears then to be to allocate an initial time budget for exploration, and if by the end the information picture has stabilised (no new surprises, consistent signals), then stop and decide.
I suspect there is a good Bayesian interpretation of this heuristic.
The Value of Social Norms
What then of social norms? What counts as an obvious source, an expert, or standard practice, is socially determined. Even if I am suspicious of social norms, I have to admit that they carry indirect value: they embody social learning from others’ past mistakes. Especially in contexts where catastrophic harms have occurred such as in medicine and engineering, norms, heuristics and rules of thumb represent distilled experience.
So while norms need (should?) not be obeyed blindly, they deserve to be treated as informative priors: they tell us about where risks may lie and which avenues to prioritise for exploration.
Trying One’s Best: A Practical Recipe
Pulling these threads together, perhaps “trying one’s best” under uncertainty means:
Start with a first-principles orientation: aim for causal clarity and avoid blind conformity.
Consult obvious sources of information and relevant social norms as informative signals.
Allocate an initial finite time for self-investigation.
Stop when information appears stable. If significant new evidence arises during investigation, continue. The significance threshold should vary depending on the potential impact.
Document your reasoning if you depart from norms.
Responsibility is not about hindsight-optimal outcomes. It is about following a bounded, transparent, and risk-sensitive procedure. Social norms play a role not as absolute dictates, but as evidence of collective learning obtained in the context of a particular social environment. Above all, “trying one’s best” means replacing the impossible ideal of omniscience with procedural reasonableness.
While this approach still seems very vague, it has at least helped me to put decision making in some perspective.
Acknowledgements
The idea for this post came as a result of discussions with CM over the last two years. The fleshing out of the structure of the post and argument were over a series of conversations with ChatGPT 5 on 26th October 2025. The text was largely written by me.
This blog post sets up and analyses a simple mathematical model of Marx’s controversial “Law of the Tendency of the Rate of Profit to Fall” (CapitalIII §13-15). We will work under a simple normalisation of value that directly corresponds to the assumption of a fixed labour pool combined with the labour theory of value (LTV). I will make no remarks on the validity of LTV in this post, but all results are predicated on this assumption. We will also work in the simplest possible world of two firms, each generating baskets containing both means of production and consumer goods, and in which labour productivity equally improves productivity in the production of both types of goods. I will provide the mathematical derivations in sufficient detail that a sceptical reader can reproduce them quite easily with pen and paper.
The key interesting results I am able to derive here are:
If constant capital grows without bound, then the rate of profit falls, independently of any assumption on the rate of surplus value (a.k.a. the rate of exploitation).
There is a critical value of productivity (which we derive), above which innovation across firms raises the rate of profit of both firms, and below which the rate of profit is reduced.
There are investments that could be made by a single firm to raise its own productivity high enough to improve its own rate of profit when the competing firm does not change its production process. (We locate this threshold, ). However, none of these investments would reduce the rate of profit of when rolled out across both firms (i.e. ). There is therefore no “prisoner’s dilemma” of rates of profit causing capital investment to ratchet up.
However, a firm motivated by increasing its mass of profit (equivalently, its share of overall surplus value) is motivated to invest in productivity above a third threshold , which we also prove exists, and show that . Thus there is a range of investments that improve the profit mass of a single firm but also reduce the rate of profit when rolled out to both firms.
As a result, under the assumptions with which I am working, we can interpret Marx’s Law of the Tendency of the Rate of Profit to Fall to be an accurate summary of economic evolution in purely value terms, under the assumption that firms often seek out moderately productivity-enhancing innovations, so long as radically productivity-enhancing innovations are rare.
1. The Law of the Tendency of the Rate of Profit to Fall
Marx famously argued that the very innovations that make labour more productive eventually pull the average rate of profit downward. My understanding as a non-economist is that, even in Marxian economic circles, this law is controversial. Over my summer holiday, I have been reading a little about this (the literature is vast) and there are many complex arguments on both sides, often very wordy or apparently relying on assumptions that do not line up with a simple LTV analysis.
The aim of this post is thus to show, in the simplest possible algebra, how perfectly reasonable investment decisions by competitive firms reproduce Marx’s claim, providing explicit analysis for how the scale of productivity gains impact on the rate of profit and on individual motivating factors for the firms involved.
2. Set-up and notation
I will be working purely in terms of value, as I understand it from Capital Volume 1, i.e. socially necessary labour time (SNLT) – I will pass a very brief comment on price at the end of the post. We will use the following variables throughout the analysis, each with units of “socially necessary labour time per unit production period”.
Symbol
Definition
Economic reading in Capital
overall constant capital
machinery + materials
overall variable capital
value of wages
overall surplus value
unpaid labour
constant capital advanced by Firm i
machinery + materials
variable capital advanced by Firm i
value of wages
In addition, we will consider the following dimensionless scalar variables:
Symbol
Definition
Economic reading in Capital
The baseline production rate of commodities by Firm 2, as a multiple of that produced by Firm 1
capital deepening factor: the ratio of the post-investment capital advanced to the pre-investment capital advanced, evaluated in terms of SNLT at the time of investment
dearer machine (III §13)
labour-productivity factor: the ratio of the number of production units produced per unit production time post-investment to the same quantity prior to the investment.
fewer hours per unit (III §13)
We will work throughout under the constraint that . This can be interpreted as Marx’s “limits of the working day” (CapitalI §7) and flows directly from the LTV. Below I will refer to this as “the working day constraint”.
Before embarking on an analysis of productivity raising, it is worth understanding the rate of profit at an aggregate level. Marx defined the rate of profit as:
During my reading on the rate of profit, I have seen a number of authors describe the tendency of the rate to fall in the following terms: divide numerator and denominator by , to obtain . At that point an argument is sometimes made that keeping (the rate of surplus labour, or the rate of exploitation) constant (or bounded from above), as as . This immediately raises two questions: why should remain constant (or bounded), and why should ? In this post, I will attempt to show that the first of these assumptions is irrelevant, while providing a reasonable basis to understand the second. As a prelude, we will now prove the following elementary theorem:
Theorem 1 (Rate of Profit Declines with Increasing Capital Value). Under the working-time constraint, .
Proof.. □
It is worth noting that implies that , but the latter is not sufficient for – a simple counterexample would be to keep constant while , leading to an asymptotic rate of profit of .
Theorem 1 forms our motivation to consider why we may see increasing without bound. To understand this, we will be considering three scenarios:
Scenario A: the baseline. Each firm is producing in the same way, but they may have a different scale of production. We will normalise production of Firm 1 to 1 unit of production, with Firm 2 producing units of production per unit production time.
Scenario B: after a general rise in productivity. Each firm is again producing in the same way, with the same ratio of production units as Scenario A. Each firm has, however, made the same productivity-enhancing capital investment, so that Firm 1 is now producing units and Firm 2 is now producing units of production per unit time.
Scenario C: only a single firm, Firm 1, implements the productivity-enhancing capital investment. Firm 1 is now producing units and Firm 2 is still producing units of production per unit time. This scenario allows us to explore differences in rate and mass of profit for Firm 1 compared to Scenario A and Scenario B, proving several of the results mentioned at the outset of this post.
3. Scenario A — baseline
We have: and .
The total value of the units of production produced is (using the working day constraint). Each unit of production therefore has a value of . Firm 1 is producing 1 of these units.
The surplus value captured by (profit mass of) Firm 1 is therefore .
This gives an overall rate of profit for Firm 1 of: .
This rate of profit is the same for Firm 2, and indeed for the overall combination of the two. We now have a baseline rate and mass of profit, against which we will make several comparisons in the next two scenarios.
4 Scenario B — both firms upgrade
In this scenario, both firms upgrade their means of production, leading to productivity boost by a factor of , after an increase in the value of capital advanced by a factor of . We will assume that the firms keep the number of working hours constant, and ‘recycle’ the productivity enhancement to produce more goods rather than to drop the labour time employed.
We must carefully consider the impact on the value of variable and fixed capital of this enhancement. The value of variable capital has decreased by a factor , because it is now possible to meet the same consumption needs of the workforce with this reduced SNLT. Of course, we could make other assumptions, e.g. the ability of the labour force to ‘track’ productivity gains in terms of take-home pay, but the assumption of fixed real wages appears to be the most conservative reasonable assumption when it comes to demonstrating the fall of the rate of profit. Equally, the value of the fixed capital has reduced from the original for Firm to , because a greater investment has been made at old SNLT levels () but this investment has itself depreciated in value due to productivity gains. Marx refers to this as ‘cheapening’ in Capital III §14.
We will use singly-primed variables to denote the quantities in Scenario B, in order to distinguish them from Scenario A. We have:
The total value of the units of production produced is . Remembering that our firms together now produce units of production, each unit therefore has value .
Firm 1 is responsible for of these units, and therefore a value of . We may therefore calculate the portion of surplus labour it captures as:
, and its rate of profit as:
.
Simplifying, we have
.
These will be the same rate for Firm 2 (and overall) and a proportionately scaled mass for Firm 2.
It is clear that , i.e. profit mass is always increased by universally adopting an increased productivity (remember we are keeping real wages constant). However, it is not immediately clear what happens to profit rate.
Theorem 2 (Critical productivity rate for universal adoption). For any given set of variables from Scenario A, there exists a critical productivity rate . We have iff .
Proof. Firstly, we will establish that . This follows from the fact that and are both strictly less than 1.
Now iff . Clearing (positive) denominators and noting gives the equivalent inequality . Isolating gives . □
The the overall rate of profit in Scenario 2 can rise or fall, depending on the level of productivity those gains bring. The more the cost of the new means of production, the less is spent on wages, and the greater the fixed-capital intensive nature of the production process, the higher the productivity gain required to reach a rise in profit rate, arguably raising the critical threshold as capitalism develops. However, the fact that and that indicates it will always raise the rate of profit to invest in a productivity gain that’s more than the markup in capital required to implement that gain. That it is still beneficial for the overall rate of profit to adopt productivity gains less significant than the markup in capital expenditure, i.e. when , appears to be consistent with Marx’s Capital III §14, where he appears to be assuming this scenario.
5 Scenario C — Firm 1 upgrades alone
We are interested in now exploring a third scenario: the case where Firm 1 implements a way to increase its own productivity through fixed capital investment, but this approach is kept private to Firm 1. This scenario is useful for understanding cases that may motivate Firm 1 to improve productivity and to understand to what degree they differ from the cases motivating both firms to improve productivity by the same approach.
As per Scenario B, it is important to understand the changes to the SNLT required in production. In Capital I §1, it is clear that Marx saw this as an average. A suitable cheapening factor for labour in these circumstances is because with the same labour () as in Scenario A, we have gone from the overall social production of units of production ( from Firm 2 and 1 from Firm 1), to units of production.
In this scenario we will use doubly primed variable names to distinguish the variables from the former two scenarios. We will begin, as before, with fixed capital, noting that both firms’ capital and labour has cheapened through the change in SNLT brought about by the investment of Firm 1, however Firm 1 also bears the cost of that investment:
and .
.
The total value of the units of production produced by both firms during unit production time is now .
This means that since units of production are being produced, each unit of production now has value . As we did for Scenario B, we can now compute the value of the output of production of Firm 1 by scaling this quantity by , obtaining output value . We may then calculate the surplus value captured by Firm 1 by subtracting the corresponding fixed and variable capital quantities, remembering that both have been cheapened by the reduction in SNLT:
.
The first term in this profit mass expression simply reveals the revalued living labour contributed. The second term is intriguing. Why is there a term that depends on fixed capital value when considering the profit mass under the labour theory of value? Under the assumptions we have made, this happens because although fixed-capital-value-in = fixed-capital-value-out at the economy level, this is no longer true at the firm level; this corresponds to a repartition of SNLT in the market between Firm 1 and Firm 2, arising due to the fundamental assumption that each basket of production has the same value, independently of how it has been made. It is interesting to note that this second term, corresponding to revalued capital, changes sign depending on the relative magnitude of and . For , the productivity gain is high enough that Firm 1 is able to (also) boost its profit mass by capturing more SNLT embodied in the fixed capital, otherwise the expenditure will be a drag on profit mass, as is to be expected.
Now we have an explicit expression for , we may identify the circumstances under which profit mass rises when moving from Scenario A to Scenario C.
Theorem 3 (Critical Productivity Rate for Solo-Profit Mass Increase). For any given set of variables from Scenario A, there exists a critical productivity rate for which we have iff .
Proof. We will begin by considering the difference between surplus value captured in Scenario C and that captured in the baseline Scenario A. We will consider this as a function of .
.
Differentiating with respect to ,
.
Both denominators are positive. The first numerator is clearly positive. The second numerator is also positive for . Hence is strictly increasing over the interval .
Now note that as , . However, at , simplifies to . Hence by the intermediate value theorem and strict monotonicity there is a unique value with such that iff . □
At this point, it is worth understanding where this critical profit-mass inducing productivity increase lies, compared to the value we computed earlier as the minimum required productivity increase in Scenario B required to improve the rate of profit. It turns out that this depends on the various parameters of the problem. However, a limiting argument shows that for large Firm 1, any productivity enhancement will improve profit mass, whereas for small Firm 1 under sufficiently fixed-capital-intensive production, only productivity enhancements outstripping capital deepening would be sufficient:
Theorem 4 (Limiting Firm Size and Solo-Profit Mass). As , . As , .
Proof. Both statements follow by direct substitution into the expression for given in the proof of Theorem 3 and taking limits. □
It is worth dwelling briefly on why there is this dichotomous behaviour between large and small firms. A large Firm 1 () has an output that dominates the value of the product; it takes the lion share of SNLT, and the only impact on the firm of raising its productivity is to reduce the value of labour power as measured in SNLT, which will always be good for the firm. However, a small Firm 1 () has no impact on the value of the product or of labour power. It is certainly able to recover more overall value from the products in the market (the term ), but it must carefully consider its outlay on fixed-capital. In particular if , only small – a low capital intensity – would lead to a rise in profit mass.
So at least for large firms (or low capital intensity) there is a range of productivity enhancements that will induce a rise in profit mass for solo adopters (Scenario C) but would lead to a fall in the overall rate of profit when universally adopted (Scenario B).
It is now appropriate to consider the individual rate of profit of Firm 1 in Scenario C, having so far concentrated only on the mass of profit.
The rate of profit of Firm 1 in Scenario C is:
.
As with the mass of profit, we are able to demonstrate the existence of a critical value of productivity, above which Firm 1 increases its rate of profit as a solo adopter:
Theorem 5 (Critical Productivity Rate for Solo-Profit Rate Increase). For any given set of variables from Scenario A, there exists a critical productivity rate for which we have iff .
Proof. As per the proof of the profit mass case, we will firstly compute the difference between the two scenarios, which we will denote . Forming a common denominator that does not depend on between the expressions for and allows us to write where . Note that is differentiable for , with:
Hence is strictly increasing with .
Now let’s examine the sign of as . Firstly, by direct substitution, , where we have also recognised that , total surplus value in Scenario A, is . This expression simplifies to . Of the three multiplicative terms, the first is negative () while the other two are positive. Hence becomes negative as , and hence so does .
We should also examine the sign of at . This time, , which simplifies to . Since both multiplicative terms are positive, and hence is positive.
So again we can make use of the intermediate value theorem, combined with our proof that is strictly increasing to conclude that there exists a unique such that iff , completing the proof. We have already shown that that via the second half of the sign-change argument. □
It remains, now, to try to place in magnitude compared to the other critical value we discovered, :
Theorem 6 (Productivity required for solo rate improvement dominates that required for universal rate improvement)..
Proof. We can place our earlier expressions for and over a common denominator that does not depend on . Here and where and .
Note that . Evaluating at , we have . From Theorem 2, we know that and so the second term is negative and so .
Since was independent of and positive, we can conclude that . However, we also know that by definition of . Hence . And we may therefore conclude that . □
This theorem demonstrates that there is no “prisoner’s dilemma” when it comes to rate of profit in this model: if a firm is motivated to invest in order to raise its own rate of profit ( then that investment will also raise overall rate of profit if implemented universally.
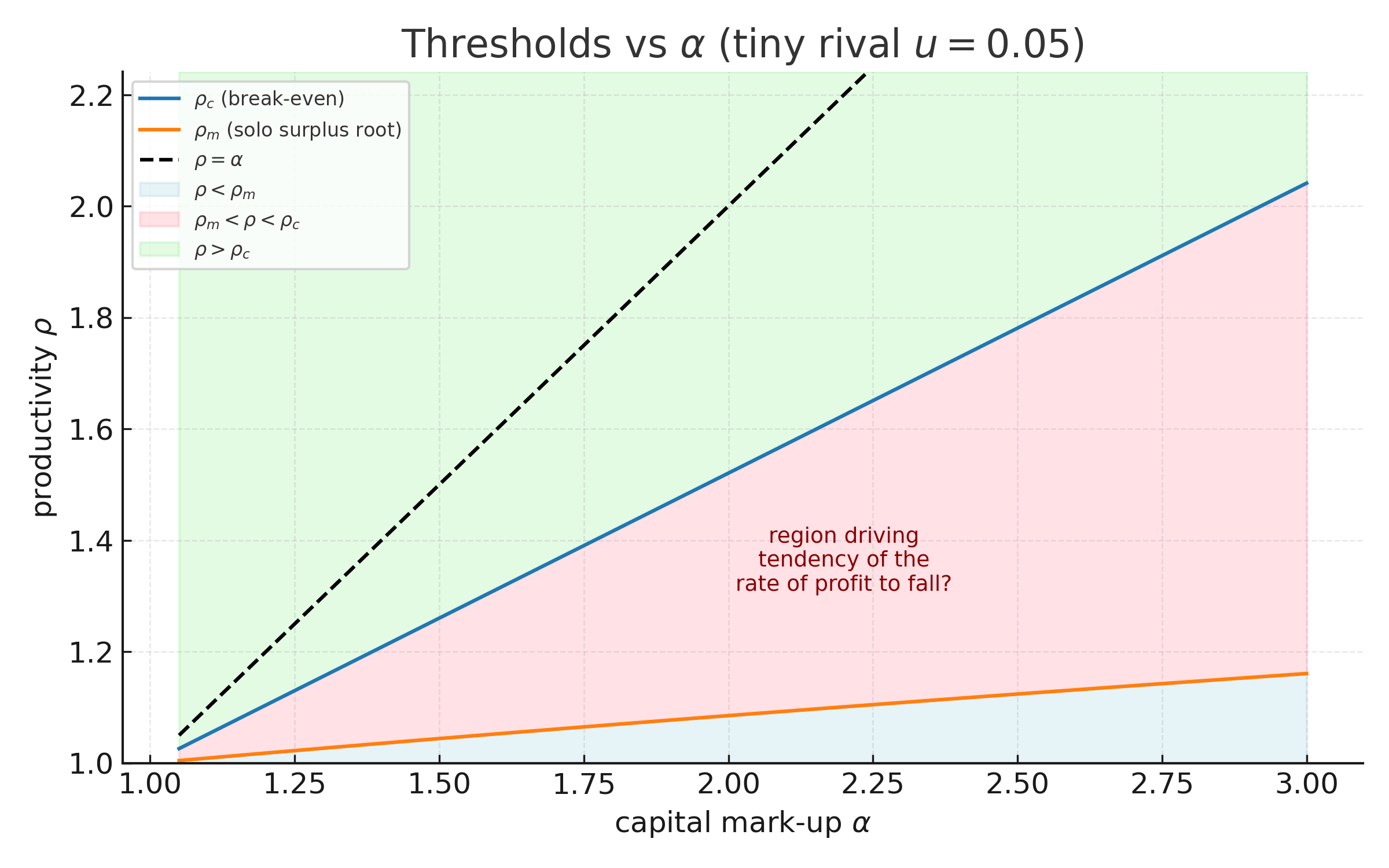
6. Summary of Thresholds
We have demonstrated a number of critical thresholds of productivity increase. Collecting results, we have
In the case of large firms (or production that is sufficiently low in fixed-capital input), we may also write:
A numerical example of these thresholds is illustrated below, for the large firm case.
Several conclusions flow from this order:
There are no circumstances under which a firm, to improve its rate of profit, makes an investment that will not also improve the rate of profit if universally adopted ().
There are cases, especially for large firms, where investments that may be attractive from the perspective of improving profit mass nevertheless reduce profit rate ().
There are productivity-enhancing investments that may be unattractive from a purely driven (either mass or rate).
7. Conclusion: The Falling Rate of Profit
In this model, we can conclude that continuous investment in moderately productivity-enhancing means of production () will lead to a falling rate of profit. Overall capital value will grow, which (Theorem 1) will lead to a falling rate of profit independent of assumptions on the rate of exploitation (rate of surplus value) .
The results in this post suggest that, if value after investment is considered by the investing firm, a key driver for this capital investment may not be the individual search for rate-of-profit enhancement by individual firms but rather simply a drive to increase their profit mass, capturing a larger proportion of overall surplus value, a situation particularly relevant under constraints on the total working time available (e.g. constrained population), and a common situation for large firms.
Some further remarks:
It is important to note that unlike a typical Marxian analysis, none of these results rely on the dislocation of price and value. Of course, it is quite plausible that the incentive to invest is based not on value but rather on current prices, but we have been able to show that such dislocation is not necessary to explain a falling rate of profit.
We have also not considered temporal aspects. It is possible that investment could be motivated by values before investment, leading to ‘apparent’ rates and masses of profit, rather than values after investment. To keep this post at a manageable length, I have not commented on this possibility, but again the aim has been to show that the falling rate can be explained without recourse to this.
We have not discussed the economic advantage that Firm 1 in Scenario 3 may have, e.g. being able to use its additional surplus value for power over the market. This may be an additional motivator for Firm 1 to move despite lower rate of profit, further accelerating the decline in the rate of profit.
Finally, as noted earlier in the post, we have preserved real wages in value after productivity enhancements, rather than allowed real wages to track productivity or benefit even slightly from productivity enhancement. This is a purposely conservative assumption, made as it seems the most hostile to retaining the falling rate of profit, and yet we still obtain a falling rate. If we allow wages to scale with productivity, this will of course further reduce the rate of profit.
I would very much welcome comments from others on this analysis, in particular over whether you agree that my analysis is consistent with Marx’s LTV framework.
Acknowledgements
The initial motivation for this analysis came from discussions with TG, YL and LW. I improved my own productivity by developing the mathematics and plot in this blog post using a long sequence of interactive sessions with the o3 model from OpenAI over a last week or so.
Update 28/6/25: The proof of Theorem 3 contained an error spotted by YL. This has now been fixed.
Update 12-13/7/25: Added further clarification of redistribution of value in Scenario C following discussion with YL and LW. Corrected an earlier overly simple precondition for spotted by YL.
My PhD student Sam Coward (jointly advised by Theo Drane from Intel) is about to head off on a speaking tour, where he will be explaining some of our really exciting recent developments. We’ve developed an approach that allows the discovery, exploitation, and generation of datapath hardware that works well in certain special cases. We’ve developed some theory (based on abstract interpretation), some software (based on egg), and some applications (notably in floating-point hardware design). Sam will be formally presenting this work at SOAP, EGRAPHS, and DAC over the coming weeks. In this blog post, I will try to explain the essence of the work. More detail can be found in the papers, primarily [1,2], with [3] for background.
We know that sometimes we can take shortcuts in computation. As a trivial example, we know that can just be replaced by for non-negative values of . Special cases abound, and are often used in complex ways to create really efficient hardware. A great example of this is the near/far-path floating-point adder. Since the publication of this idea by Oberman and Flynn in the late 1990s, designs based on this have become standard in modern hardware. These designs use the observation that there are two useful distinct regimes to consider when adding two values of differing sign. If the numbers are close in magnitude then very little work has to be done to align their mantissas, yet a lot of work might be required to renormalise the result of the addition. On the other hand, if the two numbers are far in magnitude then a lot of work might be needed to align their mantissas, yet very little is required to renormalise the result of the addition. Thus we never see both alignment and renormalisation being significant computational steps.
Readers of this blog may remember that Sam, Theo and I published a paper at ARITH 2022 that demonstrated that e-graphs can be used to discover hardware that is equivalent in functionality, but better in power, performance, and area. E-graphs are built by repeatedly using rewrite rules of the form , e.g. . But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g. , where I am using math script to denote the value of a variable and teletype script to denote an expression.
So we set out to answer:
how can we deal with conditional rewrites in our e-graphs?
how can we evaluate whether a condition is true in a certain context?
how can we make use of this to discover and optimise special cases in numerical hardware?
Based on an initial suggestion from Pavel Panchekha, Sam developed an approach to conditionality by imagining augmenting the domain in which we’re working with an additional element, let’s call it . Now let’s imagine introducing a new operator that takes two expressions, the second of which is interpreted as a Boolean. Let’s give the following semantics: . In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as . These function symbols then appear directly within the e-graph data structure. Note that the assume on the right-hand side here is important: we need both sides of the rewrite to evaluate to the same value for all possible values of , and they do: for negative values they both evaluate to and for non-negative values they both evaluate to .
So how do we actually evaluate whether a condition is true in a given context? This is essentially a program analysis question. Here we make use of a variation of classical interval arithmetic. However, traditionally interval arithmetic has been a fairly weak program analysis method. As an example, if we know that , then a classical evaluation of would give me , due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite would likely fire, resulting in zero residing in the same e-class as . Since the interval associated with is , the same interval will automatically be associated with by our software, leading to a much more precise analysis.
This interaction between rewrites and conditions goes even further: a more precise analysis leads to the possibility to fire more conditional rewrite rules, as more conditions will be known to hold; firing more rewrite rules results in an even more precise analysis. The two techniques reinforce each other in a virtuous cycle:
A virtuous cycles: greater precision leads to more rewrites leads to greater precision.
Our technique is able to discover, and generate RTL for, near/far-path floating-point adders from a naive RTL implementation (left transformed to right, below), resulting in a 33% performance advantage for the hardware.
Left: A naive floating-point subtractor. Right: The subtractor produced by our software.
I’m really excited by what Sam’s been able to achieve, as I really think that this kind of approach has the potential to lead to huge leaps forward in electronic design automation for word-level designs.
Over the last few weekends I’ve been reading Frege’s “The Foundations of Arithmetic”, a wonderful book mixing philosophy, logic and mathematics from 1884. I hope I will find time to post on the book more generally, but for now I was intrigued enough by this interesting passage to want to play a little with it.
Frege writes:
The proposition
“if every object to which stands in the relation to falls under the concept , and if from the proposition that falls under the concept it follows universally, whatever may be, that every object to which stands in the relation to falls under the concept , then falls under the concept , whatever concept may be”
is to mean the same as
“ follows in the -series after “
G. Frege, “The Foundations of Arithmetic”, Section 79.
Let’s write “ follows in the -series after ” as . Then I read Frege’s definition as:
iff
Frege’s definition appears to be a characterisation of the transitive closure of , that is the smallest transitive relation containing . Or is it? Perhaps this is not immediately apparent. I thought it might be a fun exercise to formalise this and explore it in Coq, a formal proof assistant I’ve played with a little in the past.
I enclose the Coq code I wrote below (note I am very much an amateur with Coq) that shows that Frege’s definition, once tying down an object universe ( in the code) indeed (i) contains , (ii) is transitive and (iii) is contained in any other transitive relation containing .
I hope you enjoy.
(* Coq analysis of a definition of Frege *) (* Formalises Frege’s ‘follows’ definition and proves it equivalent to transitive closure *) (* George A. Constantinides, 25/03/23 *)
RequireImportCoq.Relations.Relation_Definitions. (* for inclusion and transitive *) RequireImportCoq.Relations.Relation_Operators.
VariableA : Type. Variablephi : A → A → Prop.
DefinitionFregeFollows (x : A) (y : A) := ∀ (F : A → Prop),
(∀ (a : A), (phixa) → (Fa)) ∧
(∀ (d : A), (Fd) → (∀ (e : A), (phide) → (Fe)))
→ (Fy).
(* We will separately show: *) (* 1. phi is included in FregeFollows *) (* 2. FregeFollows is transitive *) (* 3. Amongst all relations meeting conditions 1 & 2, FregeFollows is minimal. *)
(* 1. phi is included in Frege’s relation *)
TheoremIncludesPhi : inclusionAphiFregeFollows. Proof. unfoldinclusion. introsxy. unfoldFregeFollows. introsHF. introsH1. destructH1. (* we only need base case *) apply (H0y). auto. Qed.
It’s nearly Christmas, and despite illness hitting our house this year, we’re still managing to play games. One of the games I enjoy playing with my family is Star Realms, however the built-in mechanism for keeping track of life total – known in this game as “Authority” – is a little clunky, and so my son and I quickly decided to use spin-down life counters from Magic: The Gathering instead.
Authority starts at 50, and it can go up and down during a game of Star Realms. This means we need at least three spin down life counters to represent our Authority, assuming that the total authority is equal to the sum of the values displayed on the life counters. We did briefly consider using one to represent tens and one to represent units, but this was too fiddly to operate in practice.
Two ways of representing 22 Authority: 12+10 and 20+2.
Over the years, I’ve had many disputes with my son and wife over how I choose to represent my Authority total. If they have a total Authority of , then they like to have spin-downs on the battlefield. For , if is not a multiple of , then they keep precisely of these spin downs at Authority, with the remaining one at . They get very annoyed with me, as that’s not how I keep them at all: I choose a seemingly random collection of values that adds up to .
But there is method in my madness. When I want to deduct, say, 10 authority from a total represented as , it’s easy for me: I find a spin down with at least the amount I wish to deduct (if one exists) and deduct it from only that one, so I’d get . In the same position, they’d to deduct the , remove that spin down from the battlefield, and then deduct the remaining from the final spin down to get a single spin down showing .
They complain that it’s hard to figure out how much Authority I have and whether I’m in the lead or not. And they’re right. In my system, arithmetic tends to be easier – I tend to need to flip fewer spin downs – but comparison is harder.
This is exactly the same situation, for essentially exactly the same reason, as one is faced with in computer arithmetic. They have chosen a canonical number representation, leading to efficient storage (few spin downs on the table) and efficient comparison. I have chosen a redundant number system, leading to fast computation but complex comparison.
Such redundant number systems have a long history. My friend and colleague Miloš Ercegovac, who is an expert in this field, has pointed out to me that an account of such a system was described in a 1726 paper by Mr John Colson FRS (please do download the PDF – the language is a joy). More recently, Miloš developed a deep and profoundly appealing system known as online arithmetic based on exploiting the properties of redundancy in computer arithmetic, a topic we continue to work on to this day. I strongly recommend Miloš’s book for details on this arithmetic and much much more.
Computer arithmetic pops up everywhere. Even when ill and on a Christmas holiday!
(Fellow gamers who also like spin down life counters might also be interested in this paper my son and I published some years ago.)
Over the past few weeks, my son has been telling me about St. Anselm’s ontological argument for the existence of God. Last weekend I decided to play around with trying to formalise a version of this argument mathematically. This post briefly records my thoughts on the matter. I make no claim to originality, nor have I undertaken a review of what other people have done in this area; this was just a fun way to spend some of the weekend. I would also caution that I am neither a philosopher nor a logician, however I am a user of formal logic. If any philosophers or logicians happen across this blog post and strongly disagree with anything I’ve said, it would be fun to hear about it and I’d love to learn more. It is entirely possible that I’ve committed some cardinal sin. Pun intended.
The version of the argument given in the Internet Encyclopaedia of Philosophy is as follows:
It is a conceptual truth (or, so to speak, true by definition) that God is a being than which none greater can be imagined (that is, the greatest possible being that can be imagined).
God exists as an idea in the mind.
A being that exists as an idea in the mind and in reality is, other things being equal, greater than a being that exists only as an idea in the mind.
Thus, if God exists only as an idea in the mind, then we can imagine something that is greater than God (that is, a greatest possible being that does exist).
But we cannot imagine something that is greater than God (for it is a contradiction to suppose that we can imagine a being greater than the greatest possible being that can be imagined.)
Our first challenge is to understand what it means to be “an idea in the mind”. I tend to think of an idea in the mind as a description of something and, formally, as a logical formula defining a predicate. (I am not sure if this is what others think!) For the sake of simplicity, I will consider in the below “an idea in the mind” to simply mean a predicate defined on “physical things”, but keep in mind that when I refer to a predicate below, I’m really referring to the equivalence class of formulae defining this predicate.
The reading of ideas as formulae (or predicates) makes it hard to say what we mean when we compare two things, one which exists and one which doesn’t, in Line 3 of Anselm’s argument, though, an issue we will address below.
Finally, to my way of thinking, there appears to be an unnecessary implicit focus on uniqueness in the way the argument presented above is given, so let’s strip that away to simplify matters, so we just want to focus on a predicate which may be taken to describe ‘godliness’, or ‘godlike things’ – call it .
Premises
Taking the above arguments together, I will redefine the first premise as “the concept of godliness is a concept of which there is none greater.”
The other unnecessary element in this argument seems to be the use of language to draw the reader into trying to define ‘greater’ as some kind of second-order predicate denoting an order (of some kind) on first-order predicates. We will see below that this is not necessary, so we will consider ‘greater’ as simply referring here to an arbitrary 2-place second-order predicate . Thus we obtain
1. .
We obtain Premise 2 directly by simply stating Premise 1 formally, given our conception of ‘an idea in the mind’.
Premise 3 is interesting. In our reformulation, we have a few approaches to this premise depending on what is meant by “other things being equal”. It seems that the weakest interpretation would be “for any concept describing something that doesn’t exist, there’s some greater concept”:
3a. .
(Note that here, and in the following, I’ve used the convention that a ‘dot’ indicates an opening bracket that is closed at the end of the statement.)
Proof
The proof then follows Lines 4-6 directly:
From Premise 3a, conclude via universal instantiation. Then using Premise 1 and modus tollens, one obtains .
In English: we may conclude from Premise 3a that if a god does not exist then there exists a concept greater than godliness. But since there is no concept greater than godliness (Premise 1), a god exists.
What does this mean?
This argument is valid, but what is its semantic content? Let’s try to build some ‘unorthodox’ models to see if we can satisfy these premises and understand the rigidity these premises provide. In this section I will use to denote the interpretation of a formula in a model, and I will use to denote the false predicate, i.e. is false for all .
One simple model has (M1) true for any predicate with different interpretation to , (M2) false for all other predicate pairs, and (M3) true for all . Let’s verify the premises under this model. Since and differ in interpretation, Premise 1 is true by (M2 + M3). Equally, Premise 3a is true by (M1). What’s this model (one of several) actually saying? “Everything is godlike! A godlike thing exists!”. So quite reasonable logically, but perhaps not in line with a typical reading – perhaps it can be taken as a pantheistic reading!
Another simple model has all the same interpretations as above but with true for exactly one element. This model is saying “There’s a unique existent God! But the concept of God is no greater than the concept of any other existent thing.”
Both of these models do actually have as a partial order, though there are also models where it is not. Even if we were to impose strict totality on , then there are minimal restrictions on the order: we require only that godliness is at the top.
In general, in every model, the interpretation of is one for which there is an epimorphism from onto a specific relation on . Then the relation in question is . We also require and . Another way of saying this is that any relation will do, so long as its digraph can be partitioned into two vertex subsets: a nonempty set containing zero indegree nodes (including ), and a nonempty subset containing the rest (including ). Note that to achieve this, the interpretation of and must necessarily differ, i.e. a god must exist.
It appears that Anselm’s argument has basically shifted the problem ‘existence of God’ onto the problem of “what does ‘greater’ mean?” The special relation described in the preceding paragraph forms the archetype of acceptable answers to the latter question: ideas that are greatest must be those that describe an existing thing.
“Other things being equal”
Let’s go back to the line ‘other things being equal’. The best I can muster here as an alternative interpretation of Premise 3 taking this line into account is that “for every concept describing something that doesn’t exist, there’s some greater concept describing only those things described by that also exist”:
3b. .
However, (3b) is clearly unsatisfiable: For an arbirary predicate , assume the antecedent . Then the third conjunct enforces , which directly contradicts the second conjunct.
Discussion
I have provided two readings of St. Anselm’s argument, based on simplification away of uniqueness of “things possessing godliness” and using formulas (second-order predicates) to discuss “ideas in the mind”. The difference of these two readings hinges on the interpretation of the phrase “other things being equal”. One reading leads to a variety of models, including a model in which every (real) thing has godliness. The other reading renders Premise 3 of St. Anselm’s argument unsound. Neither reading makes strong use of any order properties relating to the phrase ‘greater than’, however the first reading is satisfiable exactly when existence is encoded within the concept ‘greater than’.
Quite an interesting way to spend a few hours – thanks to my son for interesting me in this!
Here are a few personal highlights from the FPGA 2020 conference, which took place this week in Seaside, California. (Main photo credit: George Constantinides.)
Jakub Szefer‘s invited talk on “Thermal and Voltage Side Channels and Attacks in Cloud FPGAs” described a rather nifty side-channel through which secrets could be leaked in the context of cloud-based FPGAs. The context is that one user of an FPGA would like to transmit information secretly to the next user of the same FPGA. Jakub suggests transmitting this information via the physical temperature of the FPGA. His proposal is that if the first user would like to transmit a ‘1’, they heat up the FPGA by running a circuit that uses a lot of current, such as a ring oscillator; if they would like to transmit a ‘0’, they don’t. The second user, once they arrive, measures the temperature of…
 (which we derive), above which innovation across firms raises the rate of profit of both firms, and below which the rate of profit is reduced.
(which we derive), above which innovation across firms raises the rate of profit of both firms, and below which the rate of profit is reduced. ). However, none of these investments would reduce the rate of profit of when rolled out across both firms (i.e.
). However, none of these investments would reduce the rate of profit of when rolled out across both firms (i.e.  ). There is therefore no “prisoner’s dilemma” of rates of profit causing capital investment to ratchet up.
). There is therefore no “prisoner’s dilemma” of rates of profit causing capital investment to ratchet up. , which we also prove exists, and show that
, which we also prove exists, and show that  . Thus there is a range of investments that improve the profit mass of a single firm but also reduce the rate of profit when rolled out to both firms.
. Thus there is a range of investments that improve the profit mass of a single firm but also reduce the rate of profit when rolled out to both firms.


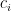




 . This can be interpreted as Marx’s “limits of the working day” (Capital I §7) and flows directly from the LTV. Below I will refer to this as “the working day constraint”.
. This can be interpreted as Marx’s “limits of the working day” (Capital I §7) and flows directly from the LTV. Below I will refer to this as “the working day constraint”.
 , to obtain
, to obtain  . At that point an argument is sometimes made that keeping
. At that point an argument is sometimes made that keeping  (the rate of surplus labour, or the rate of exploitation) constant (or bounded from above),
(the rate of surplus labour, or the rate of exploitation) constant (or bounded from above), 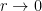 as as
as as  . This immediately raises two questions: why should
. This immediately raises two questions: why should  .
. . □
. □ implies that
implies that  constant while
constant while  , leading to an asymptotic rate of profit of
, leading to an asymptotic rate of profit of  .
. units of production per unit production time.
units of production per unit production time.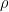 units and Firm 2 is now producing
units and Firm 2 is now producing  units of production per unit time.
units of production per unit time. and
and  .
. (using the working day constraint). Each unit of production therefore has a value of
(using the working day constraint). Each unit of production therefore has a value of  . Firm 1 is producing 1 of these units.
. Firm 1 is producing 1 of these units.  .
. .
. . We will assume that the firms keep the number of working hours constant, and ‘recycle’ the productivity enhancement to produce more goods rather than to drop the labour time employed.
. We will assume that the firms keep the number of working hours constant, and ‘recycle’ the productivity enhancement to produce more goods rather than to drop the labour time employed. to
to  , because a greater investment has been made at old SNLT levels (
, because a greater investment has been made at old SNLT levels (
 . Remembering that our firms together now produce
. Remembering that our firms together now produce  units of production, each unit therefore has value
units of production, each unit therefore has value  .
. . We may therefore calculate the portion of surplus labour it captures as:
. We may therefore calculate the portion of surplus labour it captures as: , and its rate of profit as:
, and its rate of profit as: .
.  .
. , i.e. profit mass is always increased by universally adopting an increased productivity (remember we are keeping real wages constant). However, it is not immediately clear what happens to profit rate.
, i.e. profit mass is always increased by universally adopting an increased productivity (remember we are keeping real wages constant). However, it is not immediately clear what happens to profit rate.  . We have
. We have  iff
iff  .
. . This follows from the fact that
. This follows from the fact that  and
and  are both strictly less than 1.
are both strictly less than 1.  . Clearing (positive) denominators and noting
. Clearing (positive) denominators and noting  . Isolating
. Isolating  . □
. □ , appears to be consistent with Marx’s Capital III §14, where he appears to be assuming this scenario.
, appears to be consistent with Marx’s Capital III §14, where he appears to be assuming this scenario. because with the same labour (
because with the same labour ( ) as in Scenario A, we have gone from the overall social production of
) as in Scenario A, we have gone from the overall social production of  units of production (
units of production ( units of production.
units of production. and
and  .
. .
. .
. units of production are being produced, each unit of production now has value
units of production are being produced, each unit of production now has value  . As we did for Scenario B, we can now compute the value of the output of production of Firm 1 by scaling this quantity by
. As we did for Scenario B, we can now compute the value of the output of production of Firm 1 by scaling this quantity by  . We may then calculate the surplus value captured by Firm 1 by subtracting the corresponding fixed and variable capital quantities, remembering that both have been cheapened by the reduction in SNLT:
. We may then calculate the surplus value captured by Firm 1 by subtracting the corresponding fixed and variable capital quantities, remembering that both have been cheapened by the reduction in SNLT:
 .
. , the productivity gain is high enough that Firm 1 is able to (also) boost its profit mass by capturing more SNLT embodied in the fixed capital, otherwise the expenditure will be a drag on profit mass, as is to be expected.
, the productivity gain is high enough that Firm 1 is able to (also) boost its profit mass by capturing more SNLT embodied in the fixed capital, otherwise the expenditure will be a drag on profit mass, as is to be expected. , we may identify the circumstances under which profit mass rises when moving from Scenario A to Scenario C.
, we may identify the circumstances under which profit mass rises when moving from Scenario A to Scenario C. for which we have
for which we have  iff
iff  .
.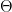 of
of  .
. .
. . Hence
. Hence  .
. ,
,  . However, at
. However, at  ,
,  simplifies to
simplifies to ![\Theta(\alpha) = \frac{(\alpha - 1)\left[ u+ (1+u)v_1 \right]}{(\alpha + u)(u + 1)} > 0](https://s0.wp.com/latex.php?latex=%5CTheta%28%5Calpha%29+%3D+%5Cfrac%7B%28%5Calpha+-+1%29%5Cleft%5B+u%2B+%281%2Bu%29v_1+%5Cright%5D%7D%7B%28%5Calpha+%2B+u%29%28u+%2B+1%29%7D+%3E+0&bg=ffffff&fg=000000&s=0&c=20201002) . Hence by the intermediate value theorem and strict monotonicity there is a unique value
. Hence by the intermediate value theorem and strict monotonicity there is a unique value  such that
such that  . □
. □ ,
,  . As
. As  ,
,  .
. ) has an output that dominates the value of the product; it takes the lion share of SNLT, and the only impact on the firm of raising its productivity is to reduce the value of labour power as measured in SNLT, which will always be good for the firm. However, a small Firm 1 (
) has an output that dominates the value of the product; it takes the lion share of SNLT, and the only impact on the firm of raising its productivity is to reduce the value of labour power as measured in SNLT, which will always be good for the firm. However, a small Firm 1 ( ), but it must carefully consider its outlay on fixed-capital. In particular if
), but it must carefully consider its outlay on fixed-capital. In particular if  , only small
, only small  – a low capital intensity – would lead to a rise in profit mass.
– a low capital intensity – would lead to a rise in profit mass. that will induce a rise in profit mass for solo adopters (Scenario C) but would lead to a fall in the overall rate of profit when universally adopted (Scenario B).
that will induce a rise in profit mass for solo adopters (Scenario C) but would lead to a fall in the overall rate of profit when universally adopted (Scenario B).  .
. for which we have
for which we have  iff
iff  .
. . Forming a common denominator
. Forming a common denominator  that does not depend on
that does not depend on  and
and 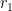 allows us to write
allows us to write  where
where ![N(\rho) := (c_1+v_1)\left[ \rho - (1+u)v_1 + \frac{u(u+1)c_1(\rho-\alpha)}{\rho+u} \right] - (\alpha c_1 + v_1)\left[ 1 - (1+u)v_1 \right]](https://s0.wp.com/latex.php?latex=N%28%5Crho%29+%3A%3D+%28c_1%2Bv_1%29%5Cleft%5B+%5Crho+-+%281%2Bu%29v_1+%2B+%5Cfrac%7Bu%28u%2B1%29c_1%28%5Crho-%5Calpha%29%7D%7B%5Crho%2Bu%7D+%5Cright%5D+-+%28%5Calpha+c_1+%2B+v_1%29%5Cleft%5B+1+-+%281%2Bu%29v_1+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Note that
. Note that  is differentiable for
is differentiable for  , with:
, with:![\frac{dN}{d\rho} = (c_1+v_1)\left[ 1 + u(u+1)c_1\frac{u+\alpha}{(\rho+u)^2} \right] > 0](https://s0.wp.com/latex.php?latex=%5Cfrac%7BdN%7D%7Bd%5Crho%7D+%3D+%28c_1%2Bv_1%29%5Cleft%5B+1+%2B+u%28u%2B1%29c_1%5Cfrac%7Bu%2B%5Calpha%7D%7B%28%5Crho%2Bu%29%5E2%7D+%5Cright%5D+%3E+0&bg=ffffff&fg=000000&s=0&c=20201002)
 is strictly increasing with
is strictly increasing with  . Firstly, by direct substitution,
. Firstly, by direct substitution, ![N(\rho) \to (c_1+v_1) \left[ S + c_1 u (1-\alpha) \right] - (\alpha c_1 + v_1)S](https://s0.wp.com/latex.php?latex=N%28%5Crho%29+%5Cto+%28c_1%2Bv_1%29+%5Cleft%5B+S+%2B+c_1+u+%281-%5Calpha%29+%5Cright%5D+-+%28%5Calpha+c_1+%2B+v_1%29S&bg=ffffff&fg=000000&s=0&c=20201002) , where we have also recognised that
, where we have also recognised that  . This expression simplifies to
. This expression simplifies to ![(1-\alpha)c_1 \left[S+ (c_1+v_1)u \right]](https://s0.wp.com/latex.php?latex=%281-%5Calpha%29c_1+%5Cleft%5BS%2B+%28c_1%2Bv_1%29u+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Of the three multiplicative terms, the first is negative (
. Of the three multiplicative terms, the first is negative (![N(\alpha) = (c_1+v_1)\left[ \alpha - (1 - S) \right] - (\alpha c_1 + v_1) S](https://s0.wp.com/latex.php?latex=N%28%5Calpha%29+%3D+%28c_1%2Bv_1%29%5Cleft%5B+%5Calpha+-+%281+-+S%29+%5Cright%5D+-+%28%5Calpha+c_1+%2B+v_1%29+S&bg=ffffff&fg=000000&s=0&c=20201002) , which simplifies to
, which simplifies to ![N(\alpha) = (\alpha - 1)v_1\left[ 1+ c_1(1 + u) \right]](https://s0.wp.com/latex.php?latex=N%28%5Calpha%29+%3D+%28%5Calpha+-+1%29v_1%5Cleft%5B+1%2B+c_1%281+%2B+u%29+%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Since both multiplicative terms are positive,
. Since both multiplicative terms are positive,  and hence
and hence  is positive.
is positive. iff
iff  and
and  over a common denominator
over a common denominator  that does not depend on
that does not depend on  and
and  where
where  and
and  .
.  . Evaluating at
. Evaluating at  , we have
, we have  . From Theorem 2, we know that
. From Theorem 2, we know that  .
. was independent of
was independent of  . However, we also know that
. However, we also know that  by definition of
by definition of  . And we may therefore conclude that
. And we may therefore conclude that  then that investment will also raise overall rate of profit if implemented universally.
then that investment will also raise overall rate of profit if implemented universally.

 ).
). .
. can just be replaced by
can just be replaced by  for non-negative values of
for non-negative values of  , e.g.
, e.g.  . But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g.
. But our original ARITH paper wasn’t able to consider special cases. What we really need for that is some kind of conditional rewrite rules, e.g.  , where I am using math script to denote the value of a variable and teletype script to denote an expression.
, where I am using math script to denote the value of a variable and teletype script to denote an expression. . Now let’s imagine introducing a new operator
. Now let’s imagine introducing a new operator  that takes two expressions, the second of which is interpreted as a Boolean. Let’s give
that takes two expressions, the second of which is interpreted as a Boolean. Let’s give  . In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as
. In this way we can ‘lift’ equivalences in a subdomain to equivalences across the whole domain, and use e-graphs without modification to reason about these equivalences. Taking the absolute value example from previously, we can write this equivalence as  . These
. These ![x \in [-1,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) , then a classical evaluation of
, then a classical evaluation of  would give me
would give me ![[-2,2]](https://s0.wp.com/latex.php?latex=%5B-2%2C2%5D&bg=ffffff&fg=000000&s=0&c=20201002) , due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite
, due to the loss of information about the correlation between the left and right-hand sides of the subtraction operator. Once again, our e-graph setting comes to the rescue! Taking this example, a rewrite  would likely fire, resulting in zero residing in the same e-class as
would likely fire, resulting in zero residing in the same e-class as  . Since the interval associated with
. Since the interval associated with  is
is ![[0,0]](https://s0.wp.com/latex.php?latex=%5B0%2C0%5D&bg=ffffff&fg=000000&s=0&c=20201002) , the same interval will automatically be associated with
, the same interval will automatically be associated with 


 falls under the concept
falls under the concept 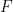 , and if from the proposition that
, and if from the proposition that  falls under the concept
falls under the concept  falls under the concept
falls under the concept  . Then I read Frege’s definition as:
. Then I read Frege’s definition as: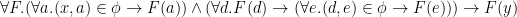
 in the code) indeed (i) contains
in the code) indeed (i) contains 
 , then they like to have
, then they like to have  spin-downs on the battlefield. For
spin-downs on the battlefield. For  , if
, if 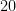 , then they keep precisely
, then they keep precisely 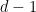 of these spin downs at
of these spin downs at  . They get very annoyed with me, as that’s not how I keep them at all: I choose a seemingly random collection of values that adds up to
. They get very annoyed with me, as that’s not how I keep them at all: I choose a seemingly random collection of values that adds up to  , it’s easy for me: I find a spin down with at least the amount I wish to deduct (if one exists) and deduct it from only that one, so I’d get
, it’s easy for me: I find a spin down with at least the amount I wish to deduct (if one exists) and deduct it from only that one, so I’d get  . In the same position, they’d to deduct the
. In the same position, they’d to deduct the  , remove that spin down from the battlefield, and then deduct the remaining
, remove that spin down from the battlefield, and then deduct the remaining 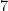 from the final spin down to get a single spin down showing
from the final spin down to get a single spin down showing 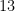 .
. . Thus we obtain
. Thus we obtain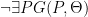 .
.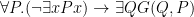 .
.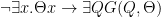 via universal instantiation. Then using Premise 1 and modus tollens, one obtains
via universal instantiation. Then using Premise 1 and modus tollens, one obtains 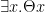 .
.  to denote the interpretation of a formula
to denote the interpretation of a formula  to denote the false predicate, i.e.
to denote the false predicate, i.e.  is false for all
is false for all 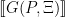 true for any predicate
true for any predicate  with different interpretation to
with different interpretation to  false for all other predicate pairs, and (M3)
false for all other predicate pairs, and (M3)  true for all
true for all  from
from  onto a specific relation on
onto a specific relation on  . Then the relation in question is
. Then the relation in question is  . We also require
. We also require 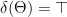 and
and  . Another way of saying this is that any relation
. Another way of saying this is that any relation  .
. , assume the antecedent
, assume the antecedent  . Then the third conjunct enforces
. Then the third conjunct enforces  , which directly contradicts the second conjunct.
, which directly contradicts the second conjunct.
